

If you are going to take on Intel in server processors, you have to play the same kind of long game that Intel itself played as it jumped from the desktop to the datacenter. And now that Cavium is part of chip giant Marvell and others have exited the field to Marvell’s advantage, there is definitely a much longer game that the ThunderX line of server chips are playing.
One of the best things to ever happen to Cavium, and therefore Marvell, was that Avago bought Broadcom, the former a company that does not have a lot of patience and is looking to milk established niches to their fullest. We don’t have a problem with that strategy, so don’t get the wrong impression. It is just different from making big bets and taking big chances, which every one of the Arm server players has done to date.
In any event, because Avago bought Broadcom for a whopping $37 billion in May 2015 and took its name, and because Avago founder Hock Tan likes established companies with rich profit pools from legacy business – which is the only explanation for the $18.9 billion acquisition of CA Technologies by Broadcom in July 2018 – and because Broadcom was trying to do a $117 billion takeover of chip rival Qualcomm in November 2017, Cavium got lucky three times over. First, the distraction of the Broadcom deal forced Qualcomm to rethink its “Amberwing” Centriq 2400 Arm server chip aspirations and that in turn forced Microsoft to rethink who its CPU partner was going to be for Arm servers. (Qualcomm was reportedly in the front running here for Microsoft Azure.) As all of this was going on, Broadcom – the new one, not the old one – lost interest in its “Vulcan” line of Arm server chips. And so, Cavium picked up the Vulcan chip for a song, renamed it the ThunderX2, got some good chip designers to boot, and has been pretty successful with pushing it into the hyperscaler and HPC markets.
That 32-core Vulcan ThunderX2 was a lot better than the original 54-core ThunderX2 that was being developed by Cavium itself, and we never heard of that original ThunderX2 again. The main reason why, we think, is that the original ThunderX2 only had six memory controllers, and therefore had the same bottlenecks as the Intel Xeon SPs do. Moreover, with 54 cores running at 3 GHz without simultaneous multithreading (SMT), this was about the same number of threads that Intel can bring to bear with 28-core, 56-thread chip that does have Intel’s Hyperthreading variant of SMT. The Vulcan ThunderX2 had eight memory controllers, and its compute and memory bandwidth were more balanced and therefore its 32 cores could go toe to toe with the Xeon SPs, and often beat them on benchmarks – just like IBM’s “Nimbus” Power9 and AMD’s “Rome” Epyc 7002 chips can do, by the way. We did a detailed analysis of the first ThunderX2 benchmarks back in May 2018.)
A lot of water has passed under the bridge since then. Ampere has emerged, after acquiring Arm server pioneer Applied Micro, as a contender, with Carlyle Group as its backer and former Intel president Renee James as its chief executive officer. (We will be covering recent developments with Ampere and its roadmap to the datacenter separately in a forthcoming article.) Ampere put a variant of Applied Micro’s “Skylark” X-Gene 3 processor into the field as the 32-core eMAG 8180, and has been mainly chasing hyperscalers and cloud builders rather than HPC centers. HiSilicon, the chip subsidiary of Chinese Huawei Technology, is pushing ahead with its Kunpeng 920 processor, which really only has a chance in the Middle Kingdom and some Asian satellite nations for geopolitical reasons. But most importantly for the mainstreaming of Arm server chips, Amazon Web Services has just revealed its second generation Graviton2 processor, a homegrown Arm chip that is heavily based on Arm Holding’s “Ares” Neoverse N1 server chip designs. The AWS Graviton2 instances will be the quickest and easiest way for companies to test out Arm code.
But when it comes to running Arm servers on premises as well as on the cloud, right now the ThunderX2 processor from Marvell holds the lead. Microsoft has started to deploy the ThunderX2 chips internally in the past few weeks, and there is an outside chance with AWS deploying a much-improved Graviton processor with 64 cores (we don’t think the Graviton2 has multithreading) that Microsoft will also expose raw Arm server instances to customers on the Azure cloud rather than just keeping the Arm chips for its internal use, as has been its plan all along.
Marvell has been a little quiet this year as all of these developments have been underway, but sat down with The Next Platform to give us an update of what is going on and where the ThunderX line of chips is going. Companies like to see a steady cadence of improvements in their server chips, and having a roadmap and talking about the future is perhaps the most crucial part of any discussion of selling today’s processor above and beyond actually delivering a competitive chip. That’s the hard part, of course, but we live in a Janet Jackson world. (What have you done for me lately?)
The first thing to consider is that Marvell is not a pipsqueak like Cavium and Applied Micro were. The company was founded in 1995 and has over 6,000 employees and had $2.9 billion in revenues in its fiscal 2019 year ended in January of this year. The company makes all kinds of chips for embedded and datacenter products, including CPUs and NPUs as well as a slew of other kinds of peripheral controllers and such. Marvell has a 10,000-strong portfolio of patents, too, which is important in the modern IT era where companies sometimes lawyer up to fight technology battles. The Marvell portfolio is pretty wide, as you can see:

Some of these assets came from the QLogic, XPliant, Broadcom, and Cavium acquisitions, some of these came from other acquisitions or were developed internally. The origin doesn’t matter at this point as much as the breadth of the portfolio and the fact that Marvell has a commitment to expanding its footprint in the datacenter. Marvell demonstrated this even further last week by selling off its WiFi and Bluetooth chip businesses to NXP Semiconductors for $1.76 billion. That gives Marvell a pretty sizeable warchest with which to fight for business against rivals in the datacenter.
Moreover, Marvell bought the IBM Microelectronics division – the part of Big Blue that used to do custom ASIC design – from GlobalFoundries back in May for $650 million. Over 800 engineers and a slew of tools and technologies come with this deal, and which will generate an incremental $300 million or so to Marvell a year. Marvell also picked up the engineers who worked on the Centriq line of Arm server chips at Qualcomm, and is setting up a chip design center in Raleigh, North Carolina.
Now, Marvell has three different routes to market for its chippery:
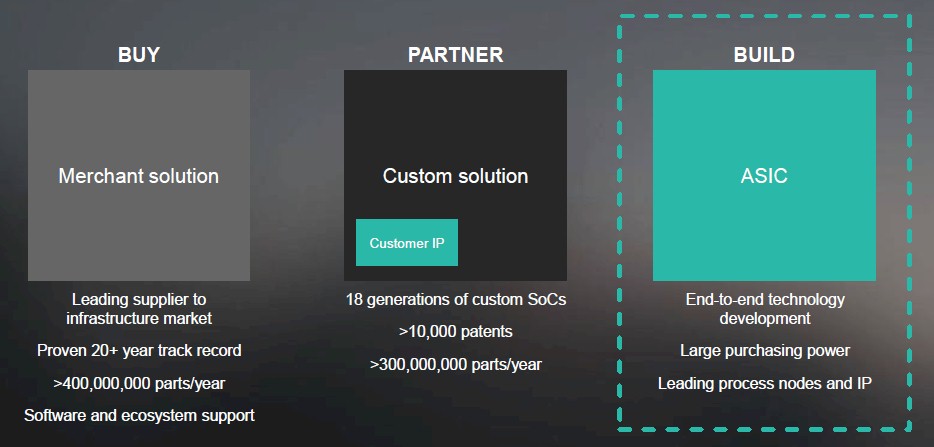
And, it now has a foot in the door with the hyperscalers and telcos that were using the IBM/GloFo unit to design custom chips. At this point, Marvell has over 100 partners that work directly with the company concerning the ThunderX2 processor. Two of the biggies are Cadence and Mentor Graphics, with their EDA and CAE tools – which is where Intel made so much investment in its Xeon chips and the Linux operating system to get both hardened for the datacenter back in the 2000s. (History does repeat itself, with little twists and turns. . . .)
The various lines of business at Marvell have been designing and shipping CPUs and NPUs for more than 15 years and collectively account for billions of chips shipped. This includes not only the ThnderX1 and ThunderX2 lines pulled in from the Cavium deal, but also the Armada line of chips designed by Marvell itself as well as the Octeon TX and Octeon Fusion network processors that are based on MIPS64 cores. (The ThunderX1 is really an Octeon III NPU that global replaced the MIPS cores with Arm cores and then gussied it up a bit.)
The point is, this is not the tiny Cavium operation anymore. And ThunderX2 has put a dent, however small, in the server market, with 20 production installations among hyperscalers and HPC centers and with tens of thousands of units shipped, according to Gopal Hegde, general manager of the server processor business unit at Marvell. Without naming too many names, Hegde says that Marvell is working with all of the ODMs that build servers and other datacenter gear, but thus far only Foxconn, Gigabyte, and Pegatron are public references. As for the OEMs, Hewlett Packard Enterprise (including work done by Cray) and Atos (the Bull server division, to be precise) are the big ones, and they are all aiming at deploying ThunderX2 in HPC centers, sometimes with GPU acceleration but often in CPU-only clusters.
The difference between ThunderX1 and ThunderX2 was not just in core counts, memory controllers, and process shrinks. The biggest change has been the software ecosystem.
“If you go back a few years, the ecosystem was not there,” recalls Hegde. “The compilers, the tools – everything had to be put together by hand. But by this year, at the ISC19 supercomputing conference, Nvidia could take a ThunderX2 system, add GPUs, and benchmark the whole thing, and they never really talked to us and they did the whole thing themselves. But between then and the SC19 supercomputer conference, we did a lot of work with Nvidia and Arm and we saw a lot of benchmarks being published. What this tells us is that the Linux ecosystem, especially as it relates to the compilers, the libraries, and the toolchain, is pretty mature. It didn’t take very long for HPC centers to bring up their applications and none of them actually called us for support or help. They were on their own. And equally important, the numbers were pretty good and it didn’t take a lot of optimization to get them.”
Microsoft’s use of Arm on Azure – and ThunderX2 specifically – presented an interesting case separate from the Linux ecosystem that Hegde is talking about above. Back in March 2017, Microsoft announced its “Project Olympus” server designs and also said that it was porting Windows Server to Arm chips, but only for internal workloads or those that are exposed as services on Azure rather than as raw infrastructure.
“A lot of people ask me why it took two and a half years to get Windows Server running on Arm, and why there has been radio silence on what has been going on with Windows Server on Arm on Azure,” says Hegde. We have asked Microsoft repeatedly to talk about what it is doing – the desire to have 50 percent of its compute on Azure be running atop Arm machinery, expressed a few years back, was pretty bold – and to little avail. We reached out to Microsoft a few weeks ago when it talked about how it was finally deploying ThunderX2 on Azure, but it would not comment at all on how widely or with what workloads. Static.
“Windows Server took a lot of work because Windows is a different type of operating system compared to Linux,” according to Hegde. “We collaborated very closely with Microsoft to get Windows working on an Arm server. Not only that, but we got all of the compilers and libraries – the entire toolchain – were tested and verified so they could be deployed into production. Datacenter customers are extremely picky when it comes to platforms, and Azure was no different in its qualification process. That process took a lot of work between Marvell, Ingrasys, Microsoft’s hardware manufacturer for ThunderX2 nodes, and Microsoft.”
Moreover, the server firmware, the Hyper-V server virtualization hypervisor, and the Autopilot monitoring and management tools that run Azure all had to be made aware of Arm-based server nodes. Microsoft also has its own set of network cards, flash and disk drives, FPGA and GPU accelerators, and other peripherals that all need to be fully qualified on the Arm-based Olympus machines.
It would have been better had Microsoft started earlier and finished sooner, of course. But as a wise man once said: The best time to do anything was ten years ago; the second best time is right now.
Before we get into the ThunderX roadmap, let’s talk for a moment about an adjacent market that is emerging for Arm servers, and that is for Arm client software development that needs to be tested to run on various SKUs of Linux platforms that can be emulated on Arm servers in the cloud. This is not big money by general purpose server standards, but it is not nothing, either. Take a look:
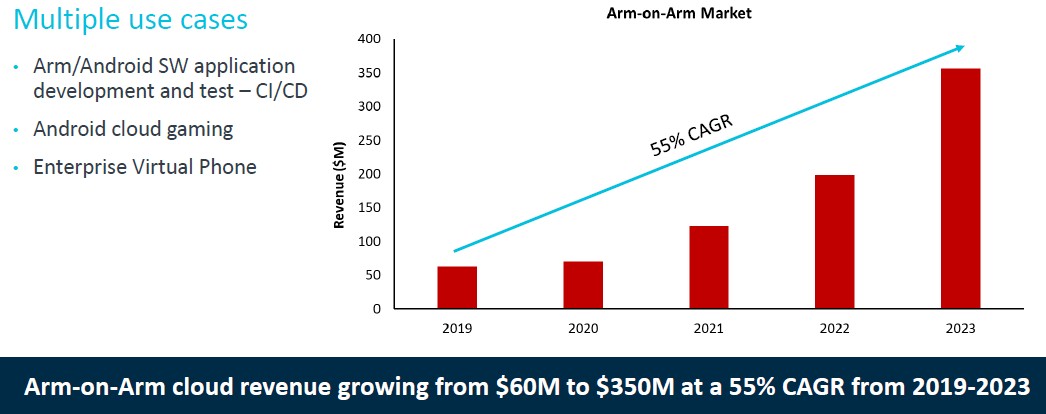
Believe it or not, there are over 10 million baby Arm devices – a lot of them are Raspberry Pi embedded servers, some are banks of actual smartphones and tablets – that are being used to develop, test, and qualify client software on Arm devices – usually running some variant of Linux. There is a tremendous opportunity to emulate these devices on a beefier server and eliminate some of the sprawl and get better total cost of ownership and drive up return on investment. Hegde says that in benchmark tests, a single two-socket ThunderX2 server could replace 190 Raspberry Pi nodes doing this smartphone and tablet emulation, and could lower TCO by deliver 50 percent or more.
There is also an opportunity to run Android cloud games on ThunderX2 and other Arm servers, and additionally, there is a market for enterprise virtual phones – think of it like virtual desktop infrastructure (VDI), but with a phone personality instead of a Windows PC personality – emerging as well. All of these can be hosted on Arm servers in the datacenter, and probably should be given the software compatibility between the Android client and the Arm server. Collectively, this market is going to grow by 6X over the next four years.
The chart above is just counting the server silicon opportunity, not the entire server opportunity, that these three emerging areas represent. Multiply by a factor of maybe 3X to 4X to get the full server opportunity. Call it $1.2 billion in Arm servers running this by 2023. That’s 5 percent revenue share or so right there, without displacing one single X86 server because it is actually capturing brand new markets.
That brings us to the ThunderX roadmap. Back in June, Arm Holdings and Marvell inked a three year deal that will see the former invest in the latter for roadmap development between now and 2022. None of the details were disclosed, but we suspect that Marvell will hew closer to the Neoverse “Ares” and “Zeus” and “Poseidon” designs and ride the Moore’s Law curve as Arm itself has committed it will do with substantial (at least 30 percent, sometimes more) performance boosts in an annual cadence at the system level. Los Alamos National Laboratory, which deployed a Cray XC50 system equipped with ThunderX2 processors and using the “Aries” interconnect from Cray back in November 2018, is also kicking in funding to develop the “Triton” ThunderX3 processor and beyond, according to Hegde.
And that bring us to the ThunderX roadmap, which looks like this in its public version:
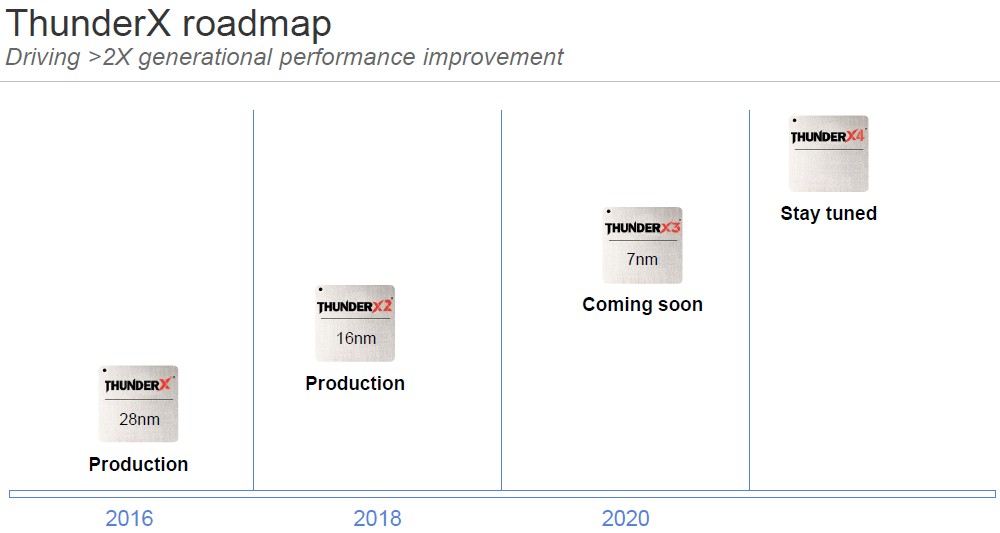
That’s pretty thin on the details, but we can help flesh it out a little.
“We are driving a very aggressive roadmap,” says Hegde. “ThunderX3 will come out in the early part of 2020, and we are driving a greater than 2X generational performance improvement. You will recall what AMD was able to do going from Naples to Rome in the Epyc X86 server chips, which was a 2X generational improvement due to higher core counts and better IPC, and so on. We have a very similar model here. Our IPC from generation to generation is going up substantially and so is our core count. So the delta between ThunderX2 and ThunderX3 is much higher than 2X.”
Marvell has parallel teams working on every other generation, and with ThunderX4, it is the Raleigh team that is driving the design. Hegde is not at liberty to disclose much in the way of specifics for either ThunderX3 or ThunderX4, but with each jump, there will be power efficiency increases as well as core count and IPC boosts.
The Marvell roadmap is not, by the way, just an airbrushing of the Neoverse roadmap from Arm Holdings as far as we can see. Arm Holdings is on an annual cadence, and Marvell is on a two year cadence, for one thing. But Marvell could be pulling things from Neoverse and expanding and tweaking it and then releasing the results every other year. In fact, that is what we think it will do. Marvell could become the poster child for the Neoverse line and make more use of the intellectual property that Arm Holdings has worse so hard on for the past several years. It doesn’t make much sense to reinvent these wheels when time to market has really hurt the Arm collective. And so, we think, Marvell could take the Neoverse designs and global replace the generic Arm cores with its homegrown ones, using the mesh interconnect and other features that Arm Holdings has cooked up in Neoverse.
The one thing we can tell you for sure is that ThunderX3 will be a monolithic design, which Hegde confirmed to The Next Platform. Marvell does not want to use cores and chips that are designed for laptops and desktops and then gang them up inside a single socket, chiplet style, to make a server processor. And the IPC jump combined with the clock speed jump from ThunderX2 to ThunderX3 is expected to be around 50 percent, which is a pretty big deal. L1 instruction caches and L2 caches will be expanded, and Marvell will be tweaking arithmetic units, branch predictors, and other parts of the chip’s front end. The caching hierarchy will be tweaked, and so will the prefetchers, and frequency will go up, not down.
If ThunderX3 has 64 cores, as we expect, then that would be a 3X performance boost per socket with a higher clock speed and the IPC boost together. Call it 20 percent for IPC and 30 percent for higher clocks (pushing up from 2.2 GHz to 2.9 GHz). If you geared the chips down a bit back to 2.2 GHz, you could drop the thermals a lot, perhaps back down to the 150 watts of the ThunderX2 instead of the 200 watts we expect from the ThunderX3.
Marvell has a lot of levers it can pull, and only some of them come from chip partner Taiwan Semiconductor Manufacturing Corp.
“Intel has a lot of legacy circuits that go back decades to support applications, but Arm has a clean slate architecture,” says Hegde. “We have a custom Arm core that is designed for server applications, and when we look at the performance per watt and the performance per area, we clearly see a big advantage. We have about a 20 percent die area advantage over Naples, and we have a similar power advantage. And when we move to 7 nanometers with ThunderX3, we see that our area and power advantage actually gets better. Our area compared to AMD Rome and Intel Ice Lake is better, and our power efficiency will be significantly better.”

Marvell Throws Hat Into Intel’s Universal Chiplet Interconnect Ring
Marvell Technology is the latest chipmaker to join the emerging Universal Chiplet Interconnect Express (UCI-Express) consortium, which is working toward an open interconnect standard for chiplet architectures. The chipmaker joins several heavy hitters in the tech arena that have thrown their weight behind the project, including AMD, Arm, Qualcomm, and …
Setting The Stage For 1.6T Ethernet, And Driving 800G Now
Marvell has had a large and profitable I/O and networking silicon business for a long time, but with the acquisitions of Inphi in October 2020 and of Innovium in August 2021, the company is building a credible networking stack that can take on Broadcom, Cisco Systems, and Nvidia for the …

Betting On Mass Customization In A Post Moore’s Law World
If you wanted to wrest control of datacenter compute as embodied mainly in the Xeon SP processor away from Intel, there are a number of approaches that you might take. You could take Intel head on in the core of its market, as AMD has done with the Epyc line …
Be the first to comment