

At this year’s Intel AI Summit, the chipmaker demonstrated its first-generation Neural Network Processors (NNP): NNP-T for training and NNP-I for inference. Both product lines are now in production and are being delivered to initial customers, two of which, Facebook and Baidu, showed up at the event to laud the new chippery.
The purpose-built NNP devices represent Intel’s deepest thrust into the AI market thus far, challenging Nvidia, AMD, and an array of startups aimed at customers who are deploying specialized silicon for artificial intelligence. In the case of the NNP products, that customer base is anchored by hyperscale companies – Google, Facebook, Amazon, and so on – whose businesses are now all powered by artificial intelligence.
Naveen Rao, corporate vice president and general manager of the Artificial Intelligence Products Group at Intel, who presented the opening address at the AI Summit, says that the company’s AI solutions are expected to generate more than $3.5 billion in revenue in 2019. Although Rao didn’t break that out into specific products sales, presumably it includes everything that has AI infused in the silicon. Currently, that encompasses nearly the entire Intel processor portfolio, from the Xeon and Core CPUs, to the Altera FPGA products, to the Movidius computer vision chips, and now the NNP-I and NNP-T product lines. (Obviously, that figure can only include the portion of Xeon and Core revenue that is actually driven by AI.)

The Neural Network Processors provide Intel with its first purpose-built AI products for the datacenter, a space that is currently dominated by Tesla GPUs from Nvidia, Xeon CPUs from Intel itself, and, to a lesser extent, FPGAs from both Intel and Xilinx.
Rao told the audience that although the AI market is not monolithic, requiring a variety of solutions based on different performance requirements and business demands, there is also a critical need for purpose-built AI processors at the high-end. To bolster that argument, Rao points to the increasing complexity of neural network models, which, based on the number of parameters, is growing about 10X per year. “This is an exponential that I have never seen before,” Rao says, adding that this rate of growth outpaces every technology transition that he’s aware of.
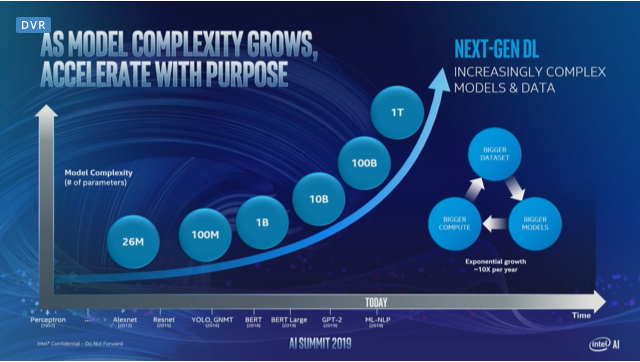
To deal with that kind of growth, the users will not only have to rely on specialized processors that can perform the relevant calculations very quickly, but the ability to use them in scaled-out fashion. In a nutshell, that’s the business case for the NNP product lines.
The inference line, NNP-I, is was not even envisioned three years ago when Intel acquired Nervana Systems. At that point, Rao and his team were developing a training chip that just did inference on the side. It was not seen as something worthy of specialization. Now, of course, inference is universally recognized as a distinct type of workload, with its own special needs for low latency, power efficiency, and specialized math.
The first-generation inference processor, the NNP-I 1000, is implemented in Intel’s 10 nanometer processes, which depending on the SKU, draws between 10 watts and 50 watts. It is comprised of 12 inference compute engines and two IA CPU cores hooked together with a cache coherent interconnect. It can perform mixed precision math, with a special emphasis on low-precision computations using INT8.
The NNP-I 1000 is offered in two products: the NNP I-1100, a 12-watt M.2 card containing a single NNP-I chip and the NNP I-1300, a 75 watt PCI-Express card that is powered by two of the chips. The NNP I-1100 supplies up to 50 TOPS, while the NNP I-1300 delivers up to 170 TOPS.
Rao claims NNP-I will be the inference leader in terms of performance per watt based on the MLPerf benchmarks, once power is factored into those results. It also offers exceptional density, he said, delivering “the most inferences per second you can jam into a single rack unit.” By Intel’s measure it also provides 3.7X the compute density of Nvidia’s T4 GPU. As a result, Rao said, “we can run larger models, more complex models, and run dozens of them in parallel.”
To support the level of scalability required in datacenters, especially those of hyperscale datacenters, Intel has developed a solution stack that is relevant to that kind of environment. In particular, the company has developed software that containerizes NNP-I applications using hooks into Kubernetes. It also provides a reference software stack that supports the function-as-a-service (FaaS) model, an emerging paradigm for cloud-based inference.
Facebook’s AI director, Misha Smelyanskiy, joined Rao, explaining that its Glow machine learning compiler has been ported to the NNP-I hardware, the implication being that the social media giant has begun to install these devices in at least some of its datacenters. Smelyanskiy did not offer any details about the scope of these deployments, but did mention some key inference applications that could be served by the new hardware, including photo tagging, language translation, content recommendation, and spam and fake account detection. The value of these purpose-built ASICs for Facebook, Smelyanskiy explained, is that they “make the execution of ML workloads highly performant and highly energy-efficient.”
The NNP-T 1000 ASIC, is a different chip altogether, offering much greater computational power. It is comprised of up to 24 Tensor Processing Cores (supporting FP32 and bfloat16 numeric formats), 55 MB to 60 MB of on-chip SRAM, 32 GB of High Bandwidth Memory (HBM), and an inter-chip link (ICL) consisting of 16 112 Gb/sec channels. The ASIC is offered in two form factors: a PCI-Express card (NNP-T 1300) or a Mezzanine Card (NNP-T 14000). The PCI-Express card draws up to 300 watts, while the Mezzanine Card tops out at 375 watts.
The ICL links can be used to span multiple levels of a system, serving as a glueless interconnect fabric across cards in a node, nodes in a rack, and racks in a POD. A node can be built with up to eight cards and these can be connected to build a multi-rack POD. At the AI Summit event, they were demonstrating a 10-rack POD with 480 NNP-T cards, without the use of a switch. The fabric is the key design element that enables the NNP-T platform to be used at a scale to train these multi-billion parameter models (in reasonable amounts of time). “Scale-out is probably the most important problem in training,” Rao explained, “and any new training architecture has to contemplate this.”
With a 32-card NNP-T rack, Intel has demonstrated 95 percent scaling efficiency on ResNet-50, a standard image classification model, as well as on BERT, an advanced model for natural language processing.
Baidu is an early adopter of the NNP-T silicon and has been collaborating with Intel on both the hardware and software. According Kenneth Church, an AI Research Fellow at Baidu, the software work focused implementing an NNP-T port for Paddle-Paddle, an open source deep learning platform that is widely employed at Baidu and is used by 1.5 million developers in China. On the hardware side, the company is using NNP-T to power its X-Man 4.0 AI supercomputer, which uses 32 of the devices per rack. Church said the system is already running workloads in their lab today. “We plan to use this throughout Baidu’s infrastructure soon,” he added.
Driving all of this is the exponential growth rate of the complexity of neural networks. Rao thinks the largest models today, which contain up to 100 billion parameters, represent something of an inflection point for the industry. At this level, these models are starting to do more than just extract useful information from data; they can now begin to understand that data well enough to turn it into knowledge. According to him, this means that information will have to be applied to past experience, and in that context, drive action. Which sounds suspiciously similar to what humans do. As he admitted though, the human brain has to deal with between 3 trillion and 500 trillion parameters and does this with just 20 watts. “Today, we’re just really scratching the surface,” said Rao.

I wonder how this compares with the Graphcore offering… https://www.graphcore.ai/posts/microsoft-and-graphcore-collaborate-to-accelerate-artificial-intelligence (that gives some BERT numbers, but they include training time, not just scaling efficiency).