

There is much at stake in the world of datacenter inference and while the market has not yet decided its winners, there are finally some new metrics in the bucket to aid decision-making. Interpreting those, however, is a challenge and given the breadth of results there is still work to do make meaningful sense of true performance profiles and comparisons.
There are over 100 companies building AI inference devices and while those with datacenter chips do not represent the vast majority, there is enough competition for server inference to make the space interesting for a while before the market whittles down the options as neatly as it did for training. Left at the top of the market for training are Nvidia GPUs as accelerators and CPUs in many cases before full production at smaller shops. There is room for the ASICs, but so far they do not represent anywhere near a sizable share of training deployments, and that is being generous.
In terms of market, however, inference is a different animal. The opportunity is vast as both the workloads and devices can scale endlessly. This might make it seem like benchmarking inference devices for the datacenter is a cleaner task but with the introduction of MLperf inference results today, this is not the case. Comparing systems with dramatically different architectures for dramatically different deployments (inside a server on the same plane with devices designed to infer inside a camera or drone) is tough, as we discussed with one of the leads behind the MLperf Inference effort, David Kanter, a few months ago.
The newly released MLperf Inference Benchmark is the result of intensive efforts on behalf of more than 30 companies and organizations and over 200 engineers and practitioners. The team’s first call for submissions drew over 600 measurements across 14 companies and 44 systems. Because of the nature of these metrics that pull from so many points of measurement, however, it is not difficult for each submitting company to find at least one area where they can showcase dominance. This means take heed, those stunning headlines about how company X blew away the competition in AI inference based on MLperf are not as clean as one might think. In many senses, everyone is a winner with this benchmark and that is where things get a little dangerous.
Of all the submissions, for datacenter inference there are only results for four commercially available processors. This includes Google’s TPUv3, Nvidia with its Turing architecture, Habana’s Goya chips, and the Intel Xeon P9282.
With that said, this is a valiant effort that, well, just takes some extra effort. For instance, boiling the results down to a per-accelerator number is a proper first step since the different system types make it tough to evaluate clear winners or losers. Even then, many companies left some of the benchmark areas incomplete or unpublished (as happened with the MLPerf training benchmarks). And for anyone trying to make a true comparison between these architectures based on MLperf results clearly understanding the power consumption and relative costs is impossible as well. It would be possible to pick through the results and build charts and arts to show some of these things, which all the vendors have done in favor of their architecture. This isn’t a new thing in the world of hardware benchmarking, but in an area like this with so much architectural diversity and workload/form factor differences having this information seems more critical than ever.
In an effort to account for the tremendous diversity of form factors and application areas, the benchmark has five components: Image classification using both MobileNet-v1 (less accurate) and ResNet-50 v1.5 (higher accuracy); Object detection with both low and high res variants (single-shot detector with MobileNet-v1 and then with ResNet-34) and finally, GNMT (the recurrent neural network for translation English to German in this case).
There are four different scenarios as well. There’s the simpler offline scenario (images stored locally, for instance, how fast can you run inference during photo tagging). There is also a server scenario, in which requests come in with bursts and lulls, so imagine users searching the internet or getting recommendations with these bursts of activity. This is measuring how much throughput is achieved at what latency thresholds. The latter is much more complex, of course, than working on data at rest. There are two other divisions here with single and multi-stream (relevant in autonomous driving with many streams of input) scenarios in both offline and server. In short, offline requires static batching whereas in servers, you have to work within latency-constrained batching, which depends on traffic patterns of how requests come in. For the datacenter inference work we focus on here at TNP, we’ll pay more attention to the latter.
Let’s take a look at how some of the vendors have presented their results, starting with Nvidia, which we believe did the right thing by breaking down the results to a per-accelerator figure.
In one example of reported results, The Next Platform’s Michael Feldman talked to Habana about their outcomes. As Feldman explains as a companion analysis to this piece:
Take just the image detection category, which alone encompasses eight different benchmarks, consisting of four scenarios (single stream, multi-stream, server, and offline) for the two selected models (MobileNet-v1 and ResNet-50 1.5). Same goes for the object detection category. Since submitters didn’t run all the different iterations on their respective platforms, the results don’t line up very well across competing hardware. For example, it would have been instructive to compare the performance of the NVIDIA’s T4 GPU, Google’s Cloud TPU, and Habana Lab’s Goya chip – three of the higher-profile inference platforms currently available and ones we’ve spilled quite a bit of ink for here at The Next Platform. For image detection, the three processors line up only in the offline scenario with the ResNet-50 model.
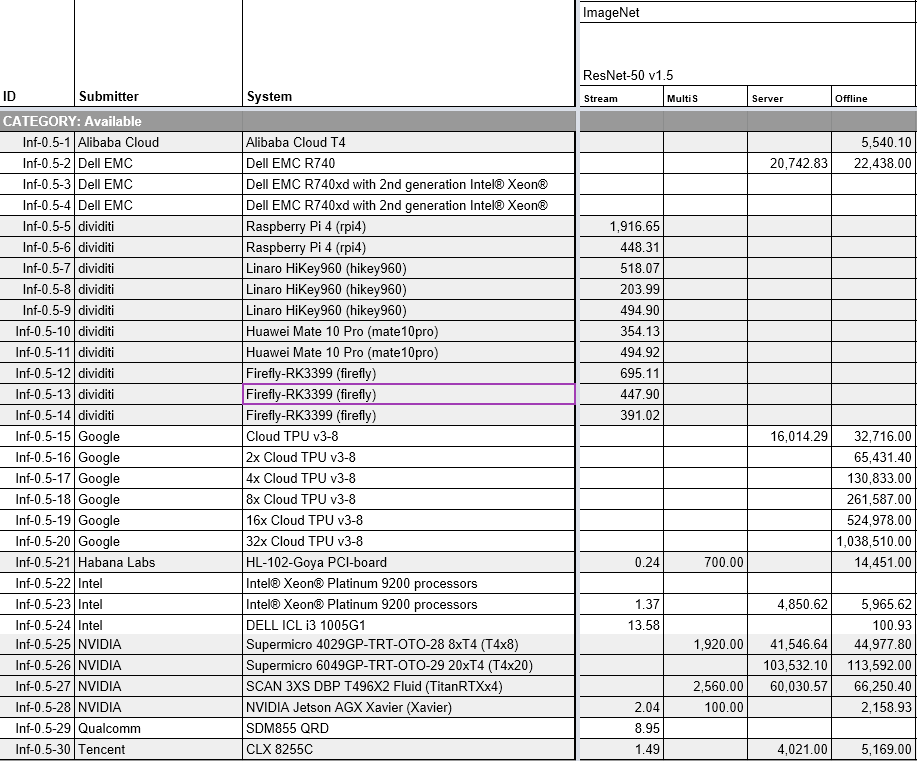
Here is a summary of those results (using systems with as few of those processors as possible):
Alibaba Cloud T4 = 5,540 samples/second
Google Cloud TPU = 32,716 samples/second
Habana Goya = 14,151 samples/second.
Unfortunately, the offline scenario is probably the least useful of the four since it’s the one that where latency – essentially the response time for a query — is ignored. In most inference situations, latency is a critical element. It’s worth noting though that even in the other scenarios where latency must fall within certain bounds, some systems are going to deliver much better latency than others, which might make a big difference in practice. Again, the details here matter a lot.
Another potential source of confusion is the amount of hardware being applied to benchmark. In the results we cited above, the TPU system is comprised of four chips, while the T4 and Goya results are based on a single processor. In one sense, it doesn’t really matter how many chips are being used, or if they are part of a multi-chip package, exist as multiple processors on a board, or are spread across a multi-node system. The real criteria should probably be the amount of power used to run the benchmark, since that takes into account all the processors and accelerators being used, as well as the memory subsystem and the network.
Besides the standard inference benchmarks used to compare different platforms in the “closed” division, MLPerf also offers an “open” division, where organizations can submit results for other models or hardware/software configurations for which there are no standard MLPerf criteria. In fact, most of the initial inference submissions (429 to be exact) fall under this category.
One example is a set of results submitted by Habana Labs, using their Goya chip to run the well-regarded natural language processing model known as BERT (Bidirectional Encoder Representations from Transformers). It shows its performance results, in the form of sentence-per-second throughput and latency, compared to a T4 GPU. Because of BERT’s increasing popularity for NLP, it may very well end up as a closed division benchmark in the future.
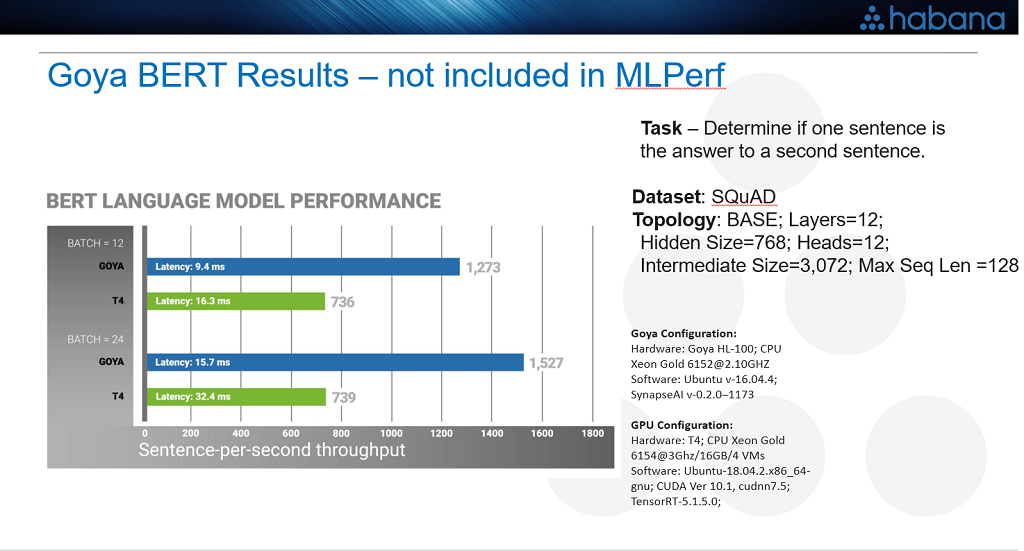
That is one example of results reporting, which show dominance, but only on a small slice of the workloads.
Nvidia did a more thorough job of sharing results and did the added favor of breaking down the results on a per-device level instead of grouped by system, which currently makes outcomes difficult to eyeball. They only used devices that are commercially available and relevant in datacenter scenarios versus some of the other submissions that are preview or R&D based or that were focused on edge or mobile applications (they do have results for those we are just focused on datacenter for this now).
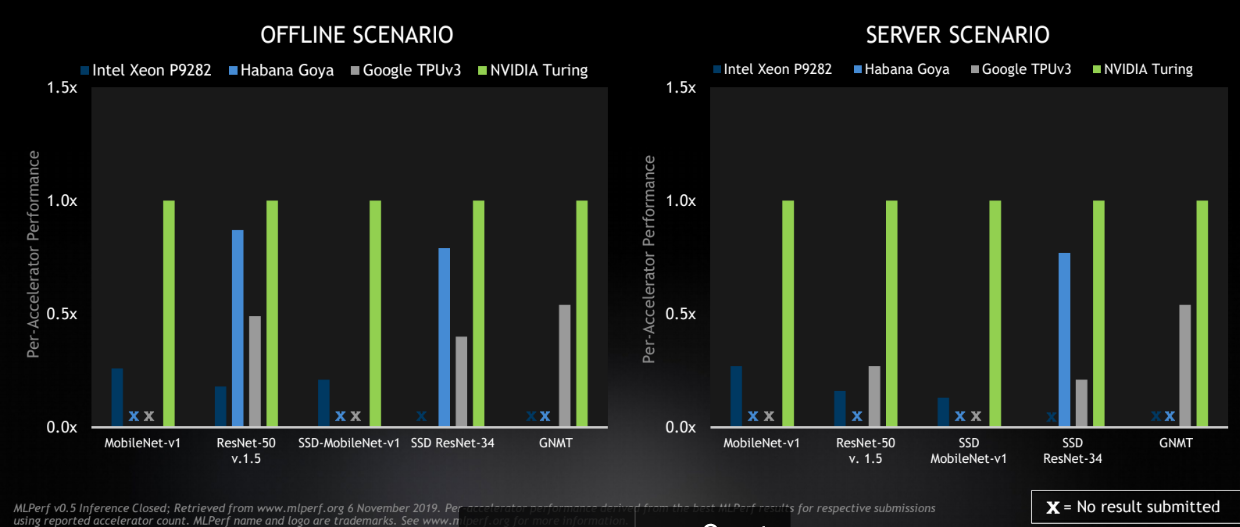
Without delving into the numbers, which were just released (we will do that now that we have them) it does appear that Nvidia’s performance was solid.
For Intel’s part, they have released the following select numbers to share:
- 9,468 images/sec in Offline scenario and 5,262 images/sec in Server scenario for COCO object detection on SSD-MobileNet v1 when using the OpenVINO toolkit, the lowest latency in single stream measurement among all submissions; and
- 29,203 images/sec in Offline scenario and 27,245 images/sec in Server scenario for ImageNet image classification on MobileNet v1; 5,966 images/sec in Offline scenario and 4,851images/sec in Server scenario for ImageNet image classification on ResNet-50 v1.5, both when using PyTorch.
Of course, without some standardization of the results on behalf of these companies getting a firm handle on what is most relevant in the datacenter will take some serious digging.
Without power or pricing ballpark figures, we might have the performance story to some degree, but the real decision factors take some more exploration.
We want to emphasize that this is an excellent first effort for the intensely varied (from workload/device/systems) MLperf working group. We expect it will self-sort over time, especially as the working group, comprised of diligent volunteers, refines the benchmark and how it is reported.
A paper was just released detailing the benchmark and the challenges of building metrics that encompass so much diversity in hardware and applications.

Ampere Computing Buys An AI Inference Performance Leap
Machine learning inference models have been running on X86 server processors from the very beginning of the latest – and by far the most successful – AI revolution, and the techies that know both hardware and software down to the minutest detail at the hyperscalers, cloud builders, and semiconductor manufacturers …
Optimizing AI Inference Is As Vital As Building AI Training Beasts
The history of computing teaches us that software always and necessarily lags hardware, and unfortunately that lag can stretch for many years when it comes to wringing the best performance out of iron by tweaking algorithms. This will remain true as long as human beings are in the loop, but …

Doing The Math On CPU-Native AI Inference
A number of chip companies — importantly Intel and IBM, but also the Arm collective and AMD — have come out recently with new CPU designs that feature native Artificial Intelligence (AI) and its related machine learning (ML). The need for math engines specifically designed to support machine learning algorithms, …
Be the first to comment