

It’s par for the course for AI chip startups to focus on peak performance on outdated benchmarks to appeal to the hardware folks who might give their gear a go for deep learning training or inference.
It’s also not unexpected to hear that these decisions might fly in the face of the weeks and months of development efforts on projects that simply can’t run well, efficiently, or at all on a new device with its own custom developer environment. This is especially unsurprising because for each chip architecture we unravel here at TNP, when we get to the software stack part of the conversation the details get sparse; hand-waving ensues. But the conversations go far beyond compilers and standards.
The gap in understanding is not a general gripe about the lack of tools or time or resources. There are some deep-seated, fundamental holes in how AI chips are designed (and by whom), how developers experiment with new architectures, and how the market/more developers can adopt them if they ever do manage to find a way into production.
It is actually quite a bit more convoluted than anyone coming from a hardware point of view (guilty as charged) can fully grasp and but Codeplay’s Andrew Richards unpacked the long list of grievances, along the way highlighting some observations that are obvious on the face but could be the reason why far fewer AI accelerators ever get meaningful adoption.
Let’s start with some of the most notable observations about this ideological, technical mismatch. And it goes to the very roots of most of the prominent AI accelerator companies.
Nearly all of the AI chip startups have technical founders who come from the world of DSPs and embedded devices (Graphcore’s CEO was ex-PicoChip and XMOS; Wave Computing’s team was largely embedded systems, just to name a couple). This might seem like excellent expertise from a workload/market point of view (especially for inference), but for AI chips, which are accelerators (and thus are offload engines) this is an entirely new way of thinking about compute. In DSPs nearly all signal processing happens on the device. You design/develop around that exclusively. A host CPU is simply turning things off and on without complex management.
“In terms of backgrounds, it would be much more useful for these AI hardware vendors to hire people that seem the complexity of the offload problem in all of its forms,” Richards says. He points to the HPC community as a prime wellspring of talent since they’ve spent years teaching large supercomputers how to speak GPU on complex, massively parallel applications, often with very unique software environment constraints. In short, they understand offload and what it means from the developer point of view. It’s no small undertaking to offload the right bits of a workload to the right device and it can take a year or more to establish that on a new architecture. The same is true of developers in the game world who were the first to sort the offload problem for early games on GPUs (this is where Richards got his feet wet).
Which brings us to our second point. By the time developers have experimented and tested an AI architecture that might eventually land in production, it’s already been a year of work. It takes a robust business model for chip startups to field these. And there’s much more to this than just this long path to production usability. It’s also about availability of experimentation. Because to even get developers innovating a new architecture, it means the devkits and demo hardware has to be made available. And here’s another area where that embedded background of easy to test devices does not serve AI accelerator startups.
Richards says that one of the reasons why GPUs took off so quickly in the early days was because Nvidia would come to meetings and hand out chips and let them go develop their own codes around it. Nvidia also, as time went on, did an incredible job of developing a rich ecosystem for nearly every workload that could be GPU accelerated to make it easier for developers to port. But the initial concept is one of enormous value. Yes, it would be ideal to hand out or let developers just purchase one or two or maybe four chips but these startups simply cannot make that part of their business model. It doesn’t work with expensive accelerators. So here is a big chicken and egg problem, among several.
“If you’re an AI software developer your job is to experiment. And when you do, you’re going to buy a very small number of chips for development. The AI chip companies now are not set up to build or sell just one or two. That is very difficult for an AI startup to do—to get to that point in distribution where they can sell just one processor.”
If developers can’t have their own devkits and test devices, even the most novel architecture-minded hardware folks on their team cannot approve those devices if the applications can’t run on them. And without time to test, the development cycle could take a year, perhaps more.
But wait, there’s more.
What all of this means is that it’s going to be a hard sell for developers to use anything but GPU/CPU. Not that it isn’t already that way at this point in the datacenter (edge/automotive are different animals).
“This is a fast-moving field and developers need to be able to write their own software as well as run existing frameworks. It’s common for developers to take TensorFlow or PyTorch and modify on top and it’s also common to always be trying something new. As a software developer thinking about trying something different, you already know that you can just run PyTorch or TensorFlow out of the box on Nvidia GPUs or Intel CPUs and whatever the AI chip companies say, you know that will not be the case,” Richards says.
“In many cases with AI hardware companies, the software people assume the API functions run on the CPU and offloads asynchronously to their accelerator. But the hardware vendor assumes that the software API function runs on their processor. It’s just a completely different way of thinking,” Richards says, adding that he’s worked with some of the AI chip vendors to talk about the way they interface for AI software folks, only to find these deep, fundamental divides.
“One of the most important things the AI chip people need to get into their heads is that while they think they are selling a processor, that chip has to fit within a system with a host CPU. They have to start remembering that this is not about individual chip performance figures on benchmarks that are not even so relevant to what developers are doing now, like ResNet, and understand that these are part of a system.”
With all of this in mind, Richards was kind enough to grant us use of his chart below that shows all of the missing pieces. It is food for thought, to say the least, if you’re coming at AI accelerators from a hardware-centric point of view.
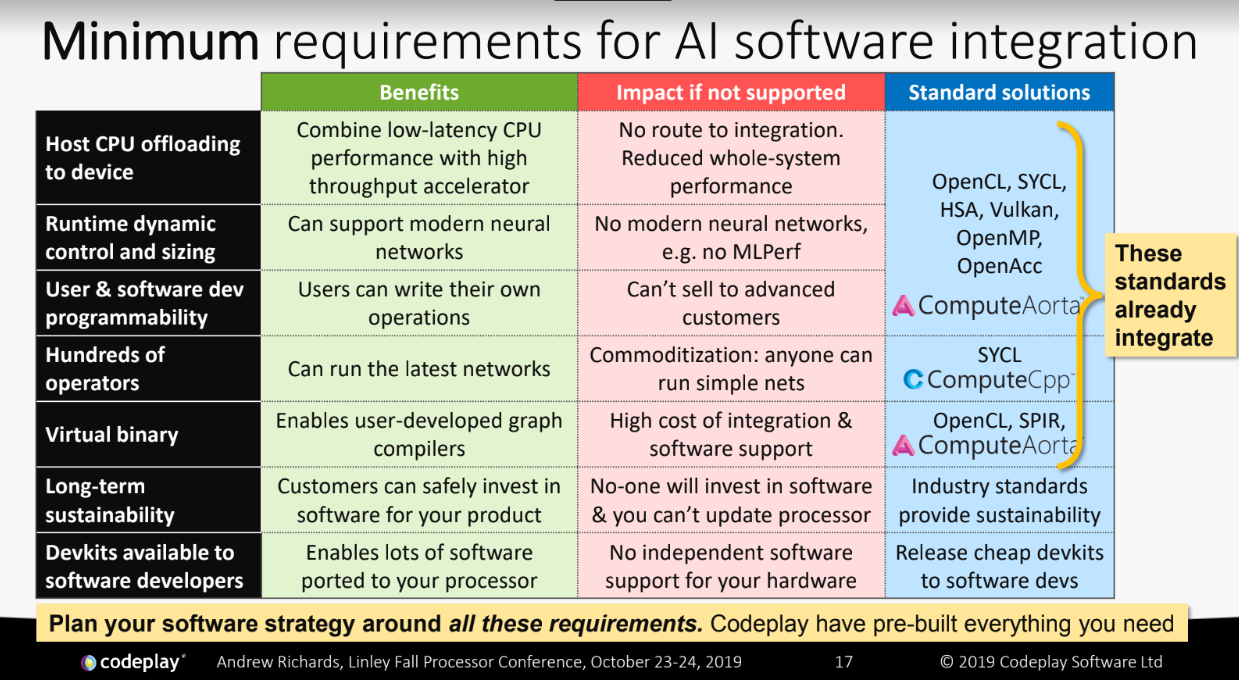
Richards says each of these items presents a tough problem if you’re a hardware vendor in this space. Aside from the long development times where they have to pony up one chip in a board for developers and wait a year to see if it’s successful, “any AI processor vendor also needs to say their first versions is just a devkit with the idea that the next version would go into production. From their standpoint, that is tough, if not impossible, business model.”
And that market for AI chips is diverse and expanding while the market is holding true to some maxims, as told by Richards in a second chart he shared. This is eye-opening if you think of it from a business model standpoint for AI chip startups.
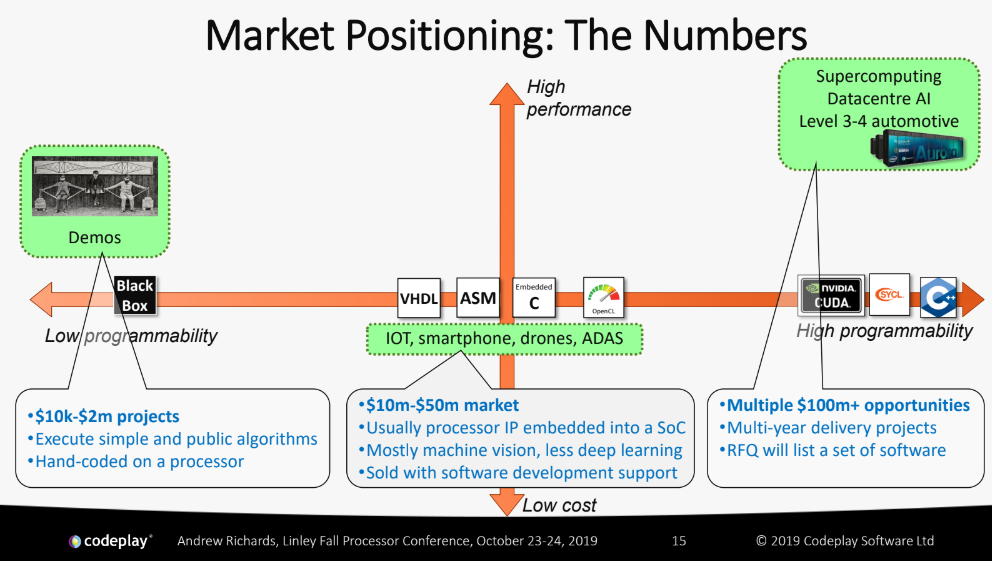
Richards says that lots of developers will buy demo machines across the three segments above. But what they do after that is completely different and presents a make or break scenario for AI accelerators. Remember, what AI developers want is the ability to write their own software and have their choice tools mesh with an architecture. And as you get to the far right on the chart with large-scale datacenters, that proposition gets much trickier, especially in supercomputing sites or hyperscale datacenters where either custom or long-loved legacy codes are paramount.
“Lots of AI software developers are coming from a background that looks more like HPC or even gaming. Because they will inherently understand, for instance, that latency sensitive tasks should be running on the CPU while compute-sensitive tasks get passed to the accelerator. Therefore, the total system, which is what actually matters, is where it should be, Richards concludes. “If you haven’t been through that or haven’t had a bridge built to help you understand that it might not be clear how critical that is.”
Considering much of the emphasis has been placed on single chip performance on benchmarks outside of a real-world developer view, it is also clear that everyone but the software folks have forgotten that every single one of the datacenter devices for AI is built as part of a system. Seeing how that works from a code development and production view makes the conversation much more nuanced.

Be the first to comment