

High performance computing isn’t what it used to be. Performance, in particular, has become a slippery metric as a result of the design constraints of modern clustered systems. A revealing illustration of what this is all about was provided by Dan Stanzione, the director of the Texas Advanced Computing Center at the University of Texas.
Stanzione gave his take on the subject at the recent 2019 MVAPICH User Group meeting, where he talked about performance in the context of TACC’s new “Frontera” supercomputer, which we first talked about a year ago when the contract award was announced. By all accounts, Frontera is one of the most powerful systems in the world. Its peak performance of 38.8 petaflops yielded 23.5 petaflops on the High Performance Linpack (HPL) benchmark test, which earned it the number five spot on the latest TOP500 list.
Frontera is comprised of 8,008 dual-socket nodes, lashed together with HDR InfiniBand at 100 Gb/sec between the nodes and with the spare uplinks to the network backbone running at the full 200 Gb/sec speed that HDR InfiniBand supports. The nodes are powered by Intel’s top bin “Cascade Lake” Xeon SP 8280 processor, which has 28 cores running at 2.7 GHz. The nodes have 192 GB of DRAM per node operating at 2.93 GHz. Compared to the top-end “Skylake” Xeon SP 8180s that were available last year when the Frontera win was announced, the Xeon SP 8280 has the same number of cores but an 8 percent higher clock speed and 10 percent more memory bandwidth because of the higher memory cycle time.
The Frontera machine is still something of a work in progress. TACC is just now getting around to adding nodes that will be outfitted with Optane persistent memory based on 3D XPoint PCM memory. The plan is to deploy 16 nodes with 6 TB of Optane memory. Those will be quad-socket nodes, using the same Xeon SP 8280 processor as in Frontera’s vanilla servers. The nodes are expected to be used for things like burst buffering and in-memory database processing.
Also coming any day now will be 90 GPU nodes, each outfitted with four Nvidia Quadro 5000 RTX cards. Although these workstation GPUs are not intended for datacenter use, TACC will be using oil immersion technology to keep them comfortably cool (courtesy of Green Revolution Cooling). The rationale here was to get a compute engine that could offer a lot of single-precision and mixed-precision performance for workloads like molecular dynamics and machine learning, but not pay the premium for double precision and Tensor Core math units as TACC would have for the top-end Tesla V100 GPU accelerators.
Even without these special-purpose nodes, the core CPU cluster is enough to make Frontera the most powerful academic supercomputer in the world, both in peak performance and by Linpack standards. But Stanzione doesn’t think those numbers mean all that much. Not that he isn’t thrilled to have Frontera. As we’ll get to in a moment, Frontera is actually doing what it was intended to do, namely run HPC applications much faster than Blue Waters, the previous top-ranked academic supercomputer. But as for that 38.8 petaflops figure, Stanzione is having none of it. “It’s a horrible, horrible lie,” he stated.
The problem is that it’s rather difficult to calculate peak floating point performance these days. It used to be fairly straightforward: multiply the processor’s core count, vector length, and simultaneous FMA issues by the clock frequency and then multiply that by the number of sockets on the machine. Which is what was done to get Frontera’s peak performance.
But you can’t operate at the processor’s stated 2.7 GHz frequency when you’re running Cascade Lake’s 512-bit Advanced Vector Extensions (AVX-512) unit continuously. As we have talked about in the past, because of thermal issues, Intel has to step down the clock rates on the AVX-512 units. “In this case, you run at the AVX-512 frequency, which is way, way lower than 2.7 GHz,” he explained.
So even the Frontera represents 38.8 petaflops, there is no way to get there, not even theoretically. By Stanzione’s calculation, which takes into account that this processor’s AVX frequency is around 1.8 GHz, Frontera’s real peak performance is something in the neighborhood of 25.8 petaflops, which, as you may note, is a lot closer to the HPL result of 23.5 petaflops.
All of which may help explain why Linpack and peak performance are not very well correlated on the TOP500 list anymore – at least for machines using AVX-512 math units. Stanzione thinks the metric was more useful in the past, when that correlation was much tighter. For example, when Intel’s “Sandy Bridge” Xeon E5 was the processor of choice for supercomputers, Linpack could achieve around 90 percent of a system’s theoretical peak. Now with the peak floating point performance metric being misused, typical Linpack yield is often around 60 percent to 65 percent. By the way, Stanzione noted that all modern processors suffer from this confusion, not just Intel’s.

The essential problem in estimating performance nowadays is that the clock frequency is dynamically adjusted, based on the power and thermal environment that the chip is operating in. These adjustments are happening continuously, from millisecond to millisecond. So at any given moment, there is no simple way to tell how fast a given processor in a given node is running.
However, there are ways to optimize the environment for faster performance. For example, even though the Xeon SP 8280 runs the AVX-512 units at about 1.8 GHz when the vectors are running at full tilt, on Frontera, TACC has managed to increase that to about 2 GHz. That’s the result of employing an especially efficient direct water rack cooling system based on CoolIT technology. Stanzione said you can also use gimmicks like reducing the speed of your DRAM to create additional thermal headroom. TACC is unlikely to be resorting to such tricks, since in general, it’s not a good idea to slow down DRAM, given that codes are more apt to be memory-bound than compute-bound.
Setting all the aside, the good news is that Frontera passed all its performance goals on its chosen set of science applications. The chart below illustrates that the machine exceeded those target thresholds in each case, sometimes by just a few percent, in other instances, by more than 100 percent. Compared to Blue Waters, applications ran between 3.2X and 9.5X faster, with an average performance increase of 4.3X. Frontera also used far few nodes than were used on Blue Waters to achieve those performance increases, such that per node performance was improved by a factor of 7.8X.
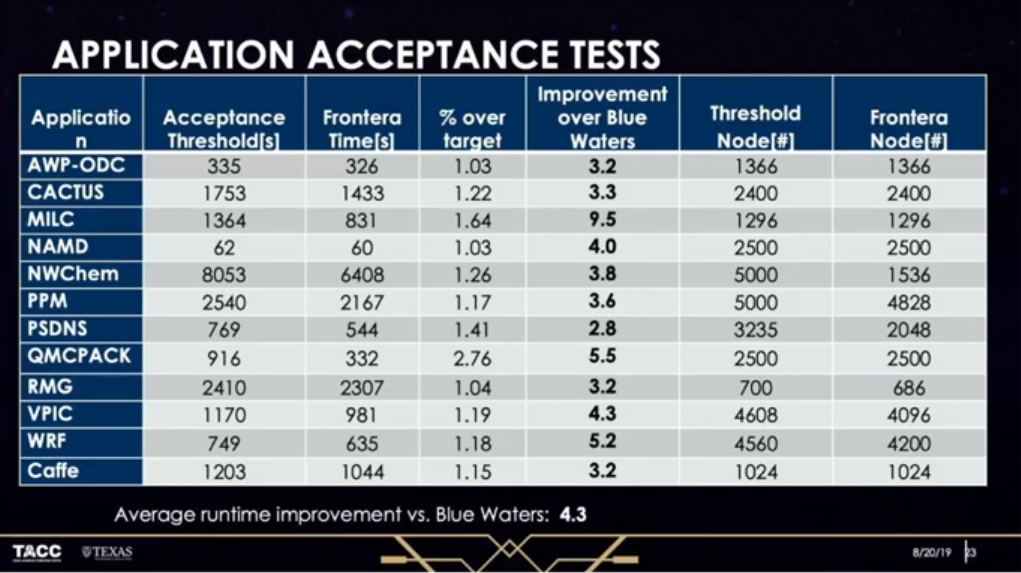
At this point, Frontera has 37 science applications running on it. The current set includes a general relatively code that models black hole collisions, a gravitational wave simulation, a virus-cell simulation that models interaction at the atomic level, a photovoltaic material science application, a brain cancer simulation, and a hybrid application that marries AI to quantum chemistry simulations. Stanzione expects Frontera to eventually have hundreds of applications.
But not thousands. Unlike some mid-level NSF supercomputers, Frontera, like its predecessor Blue Waters, is intended for capability-class applications that require the scale and power of a leading-edge supercomputer. So generally, only the largest science and engineering problems need apply. “We really want to give people large chunks of time on this machine,” said Stanzione.

Pointing out a small inaccuracy in the article… The Quadro 5000 RTX cards do have Tensor Core math units.
However, they have less NVLink lanes available. Looking, it seems they have just 1 NVLink connection instead of the 6 that the V100 has. And, of course, the Quadro 5000 RTXs have less memory bandwidth since they don’t have the HBM2 memory, as well as 16 GB being the only memory capacity option, whereas the V100 is available with 32 GB.
and without double precision and ECC Memory.
Nada que ver el rendimiento de una GPU y un CPU, son instrucciones muy distintas…