

Processor hardware for machine learning is in their early stages but it already taking different paths. And that mainly has to do with dichotomy between training and inference. Not only do these two application areas present significantly different requirements for the hardware, but the markets for these systems also present their own particular needs.
At this point, those diverging hardware requirements are fairly well understood. Training neural networks is the most computationally demanding of the two, inference is the most demanding of low latency performance. Because of the long training times of neural networks – often days or weeks – throughput is critical. For inference, the bigger focus is on getting a quick answer to the query being posed to the model, thus the need to reduce latency. Throughput is still important in inference, but computational requirements are much less than that of training. And since inference is usually performed in large-scale cloud setups, its power envelope must enable it to fit into standard server gear.
In a nutshell, processors used for training need to supply lots of flops (primarily of the 32-bit and 64-bit floating point variety), be able to access large amounts of memory (the faster, the better), and have the ability to scale out into large multi-node systems (ideally using high-performance RDMA networks). Inference processors need to provide reasonable amounts of mathematical performance (using a mix of lower precision floating point and integer), medium amounts of memory, and latency-hiding features – all at relatively low power. All the vendors in the space are designing their processors accordingly, at least the ones who are building separate products targeting each application area.
Nvidia has been offering distinct Tesla GPU products for training and inference for some time and Intel is following suit with its Neural Network Processor (NNP) chips. Others, like Wave Computing, initially developed a dual-purpose architecture to address both areas, but switched strategies when they realized that the machine learning market was becoming more specialized. But AI startup Habana Labs has been on this bifurcated path from its inception and the company’s two initial offerings do reflect these diverging requirements.
Habana released its inference processor, the Goya HL-1000, at the beginning of 2018. The processor is characterized as a heterogeneous architecture, comprised of a general matrix to matrix multiplication (GEMM) engine and 8 Tensor Processor Cores (TPCs). Each TPC has its own local memory, as well as access to shared memory in the form of SRAM. The chip supports numerical formats commonly used for inference work, including FP32, INT32, INT16, INT8, UINT32, UINT16, UINT8. A DMA engine acts the intermediary between the shared memory and both external memory and I/O. A couple of DDR4 channels can be hooked up to as much as 16 GB of external memory. The GEMM, TPC, and DMA engines can operate concurrently with the shared memory, offering a latency-hiding mechanism.

The Goya silicon is wrapped in a PCI-Express 4.0 card meant to plug into standard datacenter servers. It’s 200 watt TDP is on the high side, but supposedly power draw during typical use is in the 100 to 140 range. The card is generally available today, being one of the few custom-built inference cards in commercial production.
According to the company, using a batch size of 10, it can run ResNet-50 inference at a rate of over 15 thousand images per second with one millisecond of latency. That’s three times as fast as what Nvidia’s Tesla T4 inference GPU can manage with a batch size of 128, while delivering 26 milliseconds of latency. To get down to 1 millisecond of latency, the Tesla T4 accelerator must use a batch size of 1, but then can only churn through about one thousand images per second.
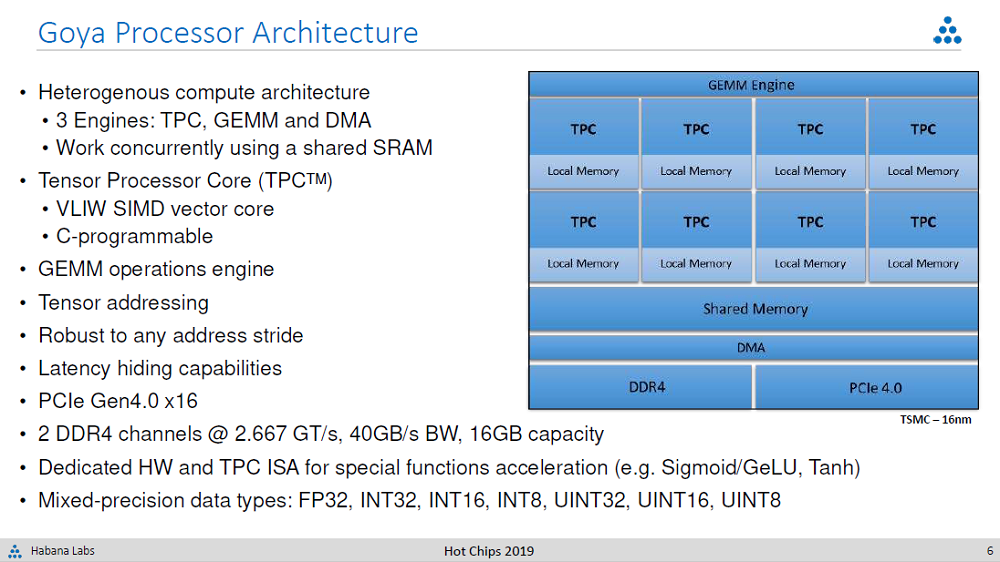
On a more complex inference task, in this case using the state-of-the-art BERT model for natural language processing (NLP), Goya can deliver throughput of 1,273 for determining if one sentence is the answer to a second sentence. Latency is 9.4 milliseconds of latency, using a batch size of 12. The equivalent T4 results are a throughput of 736 at 16.3 milliseconds of latency. Goya can get the latency down to 7.2 milliseconds with a batch size of 8, which reduces throughput only modestly to 1108. In some cases, that kind of tradeoff might be worthwhile if lower latency is the goal, as it is for many interactive NLP tasks. And since BERT is the basis for a lot of NLP models these days, the better performance should be realized in similar types of applications.
Habana chief business officer Eitan Medina recently described his company’s architectural strategy at this year’s Hot Chips event. According to him though, one of their biggest advantages is that the software they provide enables the hardware to be customized for different types of application goals. In fact, he considers the software even more important the hardware. For example, Goya’s SRAM shared memory is managed by software, which the company says enables better use of the entire memory hierarchy.
One particular element that is under user control is the accuracy loss that can be tolerated. In general, you want as high an accuracy as possible, but in some situations, you may want to lower accuracy for better performance or vice-versa. This can be managed through a software API, which modifies the data type accordingly based on the desired accuracy.
For example, with the ResNet-50 model, the use of 8-bit integer (INT8) provides the best image recognition throughput, but with an accuracy loss of 0.4 percent for compared to a GPU baseline. That’s fine for most cases, but not all. “If you want to look for that tumor in an X-ray, that 0.4 percent is probably too much,” explains Medina. In cases like that, you move up to INT16 and take the performance hit.
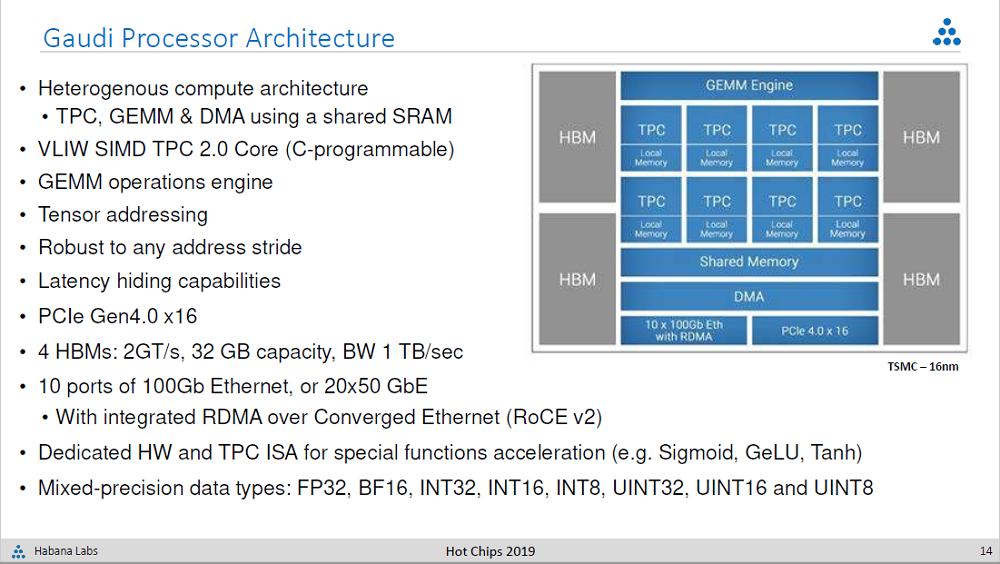
Habana’s training chip, known as the Gaudi HL-2000, shares a number of design elements with Goya, but overall is a much different architecture.

Besides having more powerful TPC and GEMM engines, support for numerical formats like bfloat16, and the inclusion of 32 GB of on-package HBM2 memory, the most significant addition is its networking capability. Each Gaudi processor has a whopping ten ports of 100 Gb/sec Ethernet that supports RDMA over Converged Ethernet (RoCE). In fact, it’s the only processor we know of that incorporates RDMA directly onto the package and certainly the only one that offers 1 Tb/sec of connectivity to each processor.
The reason behind this, says Medina, is that to support faster model training, you have to be able to scale the hardware effectively both within the node and across multiple nodes. And by effectively, he means using non-blocked RDMA. As we reported back in June, when Habana unveiled the chip, seven of the ports are used to connect Gaudis within a node, leaving three to link up to other servers.
Habana has built its own Gaudi-based system in the form of an 8-processor 3U server, known as the HLS-1. There are no host processors in the box, for that you link up to other CPU-based servers of your choice that allows you to select the desired CPU-to-accelerator ratio. (Separate PCIe links are used for this, since the 100 Gb/sec Ethernet ports are used only for hooking up to other Gaudis.) Since each chip provide three ports for external communication, that comes to 24 ports per HLS-1. The corresponding number for 100 Gb/sec ports on Nvidia’s DGX-1 and DGX-2 systems are four and eight, respectively.
Gaudi also allows users to train networks using either a data parallel approach or a model parallel one. Generally, training is performed with data parallelism, with dataset divided across servers, all of which are using the same model. It requires a manageable amount of bandwidth since they only need to exchange updates to the model as it’s trained. Data parallelism works fine with standard network components, and as we said, is the conventional way to do training.
In model parallelism, the neural network and its parameters are distributed across nodes. So each node is running a different model. This requires a lot of communication bandwidth, since the layers must be kept in sync. That’s where Gaudi’s generous supply of networking capacity comes in. A 128-Gaudi processor cluster can be built with 16 HLS-1 systems using 10 Ethernet switches. For that you get full bandwidth, with non-blocking communication. “That opens the possibility of solving much bigger parallel training problems,” Medina says.
On ResNet-50, Habana claims Gaudi systems can train up 3.8 times faster than a V100 GPU-based setup once you scale up to about 650 processors. Hopefully, we will get a better idea of how they perform on a range of applications, both in an absolute and energy efficiency sense, once they become generally available. At present, they are only shipping to select customers.




Is there any information on actual performance numbers for these chips in TFLOPs or TOPs anywhere or anything from Hotchips?
“Actual performance numbers” != TOPS. TOPS is a meaningless figure, the only interesting metric is well these chips perform in real world scenarios. Anyone can stuff a chip full of multipliers, doesn’t mean they can utilize them well.