

While accelerators have been around for some time to boost the performance of simulation and modeling applications, accelerated computing didn’t gain traction for most people until the commercialization of the Tesla line of GPUs for general computing by Nvidia.
This year marked the tenth annual Nvidia GPU Technology Conference (GTC). I have been to all but one starting with the inaugural event in 2009. Back then it was a much smaller group. Attendance has leaped 10X with this year’s meeting attracting over 9,000 participants. In 2009, GTC brought together a rag-tag group of scientists, engineers, and programmers who were largely working and struggling in isolation to develop and port applications to the new GPU based architecture. In a bold and risky move to open up its products to general purpose use, Nvidia released the CUDA (Compute Unified Device Architecture) development environment a few years prior. No longer would GPUs be restricted to graphics processing. With CUDA, anything that could run on a CPU could also run on a GPU. Those applications with sufficiently exposed parallelism could experience a significant performance boost. The Fermi chip released in 2009 concurrent with GTC was the first true general-purpose GPU platform for computing. We still have a few of these boards laying around our office at Stone Ridge Technology. Back then, GTC was dominated by physicists, chemists, and engineers looking for alternatives to CPUs for high-performance computing. Many talks centered on the building blocks of HPC and scientific computing such as sparse linear algebra, fast Fourier transforms, and stencil codes. The results were good – in some cases very good.
The GTC crowd remained about the same for at least five years. The acceleration that people got when they ported their codes to GPUs improved and the infrastructure became more robust. Nvidia invested heavily in compilers, libraries, and the software ecosystem needed to make developers productive. However, even by 2013, it was not clear that GPU computing could ever gain significant traction in HPC or contribute more than a fraction to Nvidia’s main business of graphics. Starting in 2014, however, the composition of the meeting changed with a pre-Cambrian explosion of interest and applications in artificial intelligence, machine learning, and deep learning. Today’s GTC is dominated by applications and startups pursuing these areas aggressively, promising stability and continued vigorous growth in GPU hardware and software capabilities in the coming years.
Stone Ridge Technology began experimenting with CUDA as soon as it became available. We built applications with it for seismic imaging, financial modeling, DNA sequencing, and linear algebra. The culmination of these efforts was a shift of our full attention in 2013 to the development of ECHELON, the first commercial computational engineering application fully designed and built from inception for GPUs. ECHELON is a petroleum reservoir simulator. It models how oil, gas, and water flow underground in the presence of wells. Energy companies use it for field planning and optimization. In the early days, we had to educate clients on these new GPU devices. We were essentially asking customers to consider running business-critical applications on the same hardware their kids were using to play video games. One metric of how much GPUs have become mainstream in HPC is that we don’t have these conversations anymore.
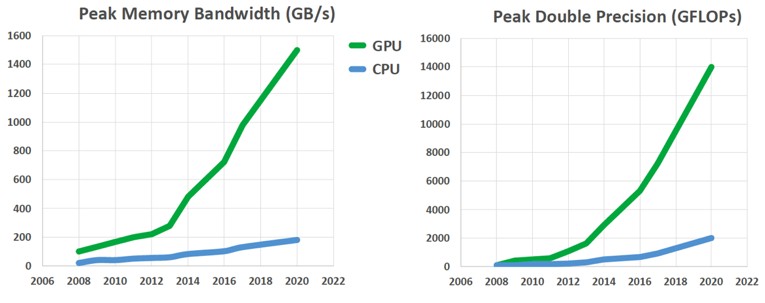
Over the last decade, Nvidia has produced six generations of GPU accelerators, from the original Tesla through today’s Volta. In that generational evolution, bandwidth has increased 9X from 100 GB/sec to 900 GB/sec and double precision flops have soared nearly 100X from 77 gigaflops to 7.45 teraflops. The US Department of Energy labs, as stewards of the nation’s state-of-the-art HPC facilities, have been acquiring GPU accelerated hardware since 2012. Industry, led by Energy companies like Eni, which we talk about here, and Total, which we talk about there, has also invested heavily in GPU hardware. Five of the top ten supercomputers in the world today use Nvidia GPUs. GPU computing has come a long way in a decade, from its start as a haven for hobbyists and other enthusiasts a decade ago to a fully mature, business-critical platform for HPC that is here to stay.
That Time Intel Ghosted HPC
By comparison performance on CPU architectures over the last decade has been incremental at best. The main advance has been in the number of cores per chip which has grown from an average of four in 2009 to roughly 24 in 2019. The additional cores add raw floating-point capability, but they are all fed by the same limited data pipe. These computational engines are hungry for bytes but they all sip through the same straw and the capacity of that straw has grown very slowly. Unfortunately, modern scientific and engineering applications are performance-limited by how fast you can move data from memory to the cores (bandwidth) and not by how fast the core can operate on data (gigaflops). Getting data to the chip rapidly is the most important metric for the performance of modern applications.
Recognizing the slow pace of progress on its traditional X86 architectures and acknowledging the danger to its HPC hegemony posed by GPU computing, Intel had for years promoted the Intel Xeon Phi platform, which was created out of the failed “Larrabee” effort to develop a discrete GPU with X86 cores that was intended to take on Nvidia and AMD in GPU graphics processing.
After a decade of promises, Intel sent the HPC community a text to let us know they were moving on. We were ghosted.
Beginning with “Knights Ferry” in 2010, Xeon Phi was Intel’s answer to GPUs and many-core computing; like having the GPU compute capability without the graphics. Lulled by the promise of easy porting and GPU-like performance from Xeon Phi, many customers chose to wait rather than transition codes, hardware, and people. Why put in the effort to port codes to GPUs when Intel would ride to the rescue with Xeon Phi in a few years? Three generations of Xeon Phi came and went and then with a brief communication known as a product change notification in July 2018 Intel unceremoniously announced it would end the Phi line of hardware. After a decade of promises, Intel sent the HPC community a text to let us know they were moving on. We were ghosted.
Now Intel is talking about bringing out a line of GPUs, called Xe, and creating its own universal parallel computing environment, called OneAPI, which are at the heart of the future Aurora A21 exascale system at Argonne National Laboratory, one of the flagship DOE facilities. There is understandable skepticism. It sounds a lot like a walk back to 2009 for a do-over and winning a big supercomputing system, or even several as Xeon Phi did, doesn’t make something a commercial product that the rest of us can count on.
Looking Ahead To HPC In The 2020s
Where does all this leave HPC today? We now have good market visibility for HPC platforms over at least the next three to five years. There are two options, i) multi-core CPUs and ii) GPUs. That’s it.
I have been asked on several occasions a variation of a question like this: “How do you know a new platform for HPC won’t emerge in the next few years?” The answer, of course, is that we don’t know for sure. However, we do know a few relevant and useful things.
First, we know that the new mystery platform does not seem to exist today, so it has yet to be discovered or revealed to the world. We also know that creating the chips for these compute platforms at the mind-boggling feature size of 7 nanometers is an expensive process, so it would be difficult to proceed through a long engineering, design, development and optimization cycle in stealth.
The performance differential of GPUs is substantial and growing, even accelerating, into the 2020s.
Third, if Xeon Phi has taught us anything, it is that the emergence of a new powerful chip for general purpose computing alone is insufficient to be useful and to create a user base. A strong entrenched user base must be present and a rich ecosystem of software must also be delivered. The latter means robust compilers, libraries, debuggers, performance tools, and so forth. This requires significant investments in both money and especially time from both suppliers and users. The history of HPC is littered with promising new compute architectures that never gathered sufficient momentum to survive.
Finally, whatever future platform emerges will be part of the many-core parallel world. There is no going back to some sort of ultra-powerful single core processor. This is an important point. Those who have created GPU optimized codes have already done the exceptionally difficult work of developing very fine-grained parallel algorithms for sophisticated HPC applications. What remains would be a mapping of these algorithms on this new mystery platform, should it ever emerge.
The Hybrid Mirage
One of the strong indicators that GPUs are the better option for HPC today is that we see more and more production CPU codes engaging in efforts to splice in GPU capability to achieve some performance gain. Some examples are codes such as ABINIT, LAMMPS, and GAMESS in molecular dynamics and computational chemistry, HFSS, MAXWELL and FLUENT from ANSYS in computational engineering and as well in our own industry of reservoir simulation. Our team at Stone Ridge Technology has done such a good job demonstrating significant performance gains with GPUs that several of our competitors have chosen to imitate us by grafting GPU components into their mature CPU codebase. These efforts are a tacit admission that the only path to performance going forward is through GPUs and it pokes a big hole in the thesis that performance gains can come from just adding more and more CPU cores. Why else would an organization go through such an arduous code refactoring?
These hybrid CPU-GPU approaches which add GPU performance to selected parts of CPU codes as an afterthought are quite different from ECHELON, which was designed from the ground up to squeeze as much performance from GPU as possible. Porting a sophisticated multi-level parallel CPU code to GPU is a non-trivial task that is fraught with challenge and yields limited benefit. It comes with severe limitations that will both meter performance and will obviate some of the principal advantages of GPU computing. There are several important deficiencies of hybrid approaches which splice GPU code into a mature CPU application.
- First is simply Amdahl’s law which states that the performance of an accelerated code is limited by how much is left unaccelerated. For example, if a particular function consumes half the execution time of an application and one miraculously finds a way to complete it almost instantly the best one can do is speed up the overall application by 2X.
- Second, by patching part of a CPU code with GPU capability you lose one of the principal benefits of GPU computing, namely, the vastly reduced hardware footprint. The bandwidth from a full rack of 40 CPU nodes can be replaced by 8 Nvidia V100s in a single GPU node. A hybrid code that executes partly on CPUs and partly on GPUs still requires the big CPU footprint for the sections of the code that remain on the CPU. So there is no reduction in hardware footprint. This is particularly important when running in the cloud and you are paying for node-hours of runtime.
- Third, hybrid solutions require data to be moved back and forth between CPU and GPU over PCIe lanes. Sloshing data back and forth like this is an expensive waste of time. Pure GPU solutions like ECHELON do not suffer this drawback since all data and state properties are stored on GPU for the entire calculation. Reporting data can be sent back periodically concurrent with calculation so there is no impairment on performance.
- Finally, when creating a GPU version of a piece of CPU code, the momentum of effort favors an approach that preserves the CPU algorithm. In other words, do the work the same way its done on the CPU. The reasons for this are to make it easier to maintain, to ensure that results on CPU and GPU will be the same and also its often necessary to avoid a full restructuring of the data containers. This means that CPU algorithms will be transferred as is to the GPU and not optimized at the high-level. This can make an enormous difference in terms of memory usage and overall performance.
The Growing Performance Gap
As the 2020s unfold in the coming years we have made an argument for two HPC platforms i) traditional CPUs and ii) GPUs. On a chip to chip comparison, GPUs currently outpace CPUs on both bandwidth and floating point operations by about a factor of 10X. Over the last decade, that gap has grown on average about 10 percent per year. However, over just the last five years, it has grown almost 40 percent per year. The performance differential of GPUs is substantial and growing, even accelerating, into the 2020s. The draw of this powerful advantage and the technology trend it informs is compelling organizations to find ways to hybridize their codes to introduce GPU performance with minimal work. However, these hybrid approaches have serious deficiencies and the best way to ride this GPU performance wave is with a code that was specifically designed and built for GPUs.
Vincent Natoli is the president and founder of Stone Ridge Technology. He is a computational physicist with 30 years experience in the field of high-performance computing. He holds Bachelors and Masters degrees from MIT, a PhD in Physics from the University of Illinois Urbana-Champaign and a Masters in Technology Management from the Wharton School at the University of Pennsylvania.

Peak memory bandwidth graph for CPUs
what about Fujitsu’s Post-K A64FX and NEC’s SX-AURORA (both ~1TBytes/sec) ?
No mention of FPGAs. Present on all clouds and a key enabler of heterogeneous computing.