
If you want to rank in the world of supercomputing – as national and state governments as well as academic and research institutions most certainly do to prove their worth for research and development – then you need to have at least a petaflops ante now to play the game. And it won’t be long before tens and then hundreds of petaflops become normal, exaflops become commonplace, and we start arguing about the name of the next leap beyond that.
There is no rest for the wicked, or for the demands of number crunching to drive the pace of innovation. Moore’s Law could be the immovable object that meets the irresistible appetite for ever-scaling applications on embiggening blocks of compute. We shall have to see. And while the pace of increasing the compute capacity of supercomputers – limited as much by budgets as by technology – has slowed in recent years, the latest iteration of the Top500 rankings of supercomputers shows that progress is being made from top to bottom and that organizations that use traditional HPC simulation and modeling applications, and that are increasingly are also using machine learning techniques either within these HPC applications or side-by-side with them, are continuing to invest in various technologies to bring more flops to bear.
This broader trend is perhaps more important than the performance ratings twice a year of the machines in the upper echelon of supercomputing. These capability-class machines blaze the trail, but that doesn’t mean anything if the rest of the industry doesn’t follow them and benefit from all of the investment and innovation that went into these behemoths. If the technology doesn’t trickle down, then it can’t do as much good as it ought to in the marketplace, and that is why we watch with a critical eye about what approaches actually go mainstream and what designs remain exotic, expensive, and almost boutique in nature.
The High Performance Linpack (HPL) implementation of the Linpack test, which solves a dense matrix of linear equations to stress test clustered systems, is written in C, not in Fortran as the earlier implementations of Linpack from the 1980s were. This makes it more portable across different system architectures and it also reflects the fact that newer HPC applications are increasingly written in C or C++ rather than Fortran, even though there is still plenty of Fortran in the HPC software library and it will stay that way for a long, long time.
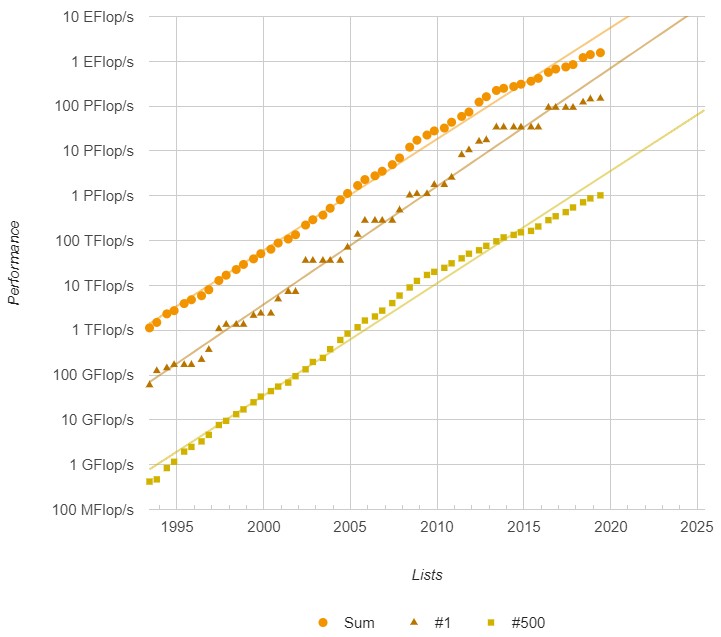
Starting six years ago, with the June 2013 Top500 list, the aggregate performance of the 500 machines that ran the Linpack benchmark and were certified by the organizers of the list – Jack Dongarra of the University of Tennessee and Erich Strohmaier and Horst Simon of Lawrence Berkeley National Laboratory – started to slow down and eventually crossed under the expected Moore’s Law trendline. This was after a burst of performance gains that had the aggregate growing a little bit faster than Moore’s Law for some time. The aggregate performance of the June 2019 list is 1.56 exaflops, up 28 percent from the 1.22 exaflops in the June 2018 list and double that if the 749 petaflops aggregate on the June 2017 list. (Again, this is gauged by sustained 64-bit by floating point math capability on the Linpack test for the system). But to have stayed on the Moore’s Law line, we would have been at around 4 exaflops total for all 500 systems here in June 2019, and this is a huge gap.
The performance of the number one system on the list over time, which is the middle line on the chart above, is always a bit of a stairstep, with the big machine being king of the hill typically for two, three, and sometimes four lists in a row. To be on the Moore’s Law line, the industry should have already delivered a system with nearly 500 petaflops of sustained performance on Linpack. The Moore’s Law line says we should have an exaflops machine by September 2020, and it looks like we will probably be about a year late for that – depending on how the United States, China, Japan, and Europe deliver on their plans. That will close the Moore’s Law gap considerably.
Interestingly, though, the bottom performer on the list started to go sub-Moore in June 2014 and has not really recovered, even though it now takes a machine with at least 1 petaflops of double-precision floating point performance on Linpack. While this is an achievement, the bottom of the list should be at 2.5 petaflops already and should be three times that as we cross the exaflops barrier sometime in 2021. The bottom and the top need to catch up at about the same rate.
None of this analysis is meant to be critical. The HPC industry continues to evolve and face many challenges, again and again and again, when it comes to compute and the networking that lets it scale and the storage that keeps it fed. But two things are clear: it is getting harder architecturally to keep the pace and it is getting more expensive to do so. As we observed years ago and updated more recently, it is far easier to make a supercomputer more powerful than it is to bring the cost of a unit of compute down. This is just the way that it is, and many of the best minds on the planet are trying to push the technology envelope on many fronts. To one way of thinking about it, it is amazing that we are on the threshold of exascale computing at all, and particularly one where the unit of performance is a lot less expensive than many would have predicted and in a thermal envelope that many did not think was possible.
And with that in mind, let’s take a look at the June 2019 Top500 rankings. The “Summit” system built by IBM with help from Nvidia and Mellanox Technologies for Oak Ridge National Laboratory boosted its performance a little bit with some tuning, hitting 148.6 petaflops of sustained Linpack oomph – almost all of which comes from the “Volta” Tesla GPU accelerators in the system. Summit is now delivering 70.4 percent of the 200.8 petaflops peak performance running Linpack. The “Sierra” system at Lawrence Livermore National Laboratory was the same at 94.6 petaflops and held onto its number two position.
The Sunway TaihuLight system at the National Supercomputing Center in Wuxi, China with the custom SW26010 processor was close behind with its 93 petaflops ranking. The Tianhe-2A system at the National Super Computer Center in Guangzhou, China, which is built using the Matrix-2000 DSP accelerator attached to Xeon server nodes, ranked number four with 61.4 petaflops of performance. There were rumors that China was trying to field one of its pre-exascale systems for the June 2019 list to topple Summit from its perch, but if that rumor was correct, it clearly did not happen. But if true, it could happen by the November 2019 rankings. We expect a certain amount of jockeying around the 200 petaflops sustained performance band before the leap to exascale begins in earnest in late 2021 and early 2022 at the core HPC national labs on Earth.
The “Frontera” system at the Texas Advanced Computing Center at the University of Texas, which was built by Dell using top bin 28-core “Skylake” Xeon SP-8280 Platinum processors and 200 Gb/sec InfiniBand interconnect from Mellanox, came onto the list for the first time at number five. Frontera is an all-CPU machine, and it has a peak theoretical performance of 38.7 petaflops and delivered 23.5 petaflops running Linpack, a computational efficiency of only 60.7 percent across its 448,448 cores. We suspect that this machine will be tuned up to run Linpack better in the coming lists.
The “Piz Daint” Cray XC50 system at the Swiss National Supercomputing Centre, which is built from Intel Xeon E5 v3 processors and Nvidia Tesla P100 accelerators, was the same at 21.2 petaflops sustained performance and was pushed down to number six on the list. Piz Daint is still the most powerful supercomputer in Europe. The SuperMUC-NG system built by Lenovo for Leibniz Rechenzentrum in Germany is an all-CPU system as well, using 24-core Xeon SP-8174 Platinum processors and 100 Gb/sec Omni-Path interconnect from Intel, is the second most powerful machine in Europe, with 26.9 petaflops peak and 19.5 petaflops sustained on Linpack – a computational efficiency of 72.4 percent, which is not so bad as these things go.
Rounding out the top ten machines on the June 2019 list is number ten, the “Lassen” unclassified baby clone of the Sierra system at Lawrence Livermore National Laboratory, which weighs in at 23.1 petaflops peak and 18.2 petaflops sustained – a very healthy 79 percent computational efficiency, slightly better than the 75.3 percent that Sierra, which is more than five times as large in terms of node counts and performance, delivers. The number seven machine on the list is the “Trinity” XC40 system shared by Los Alamos National Laboratory and Sandia National Laboratories, which is based on Cray’s “Aries” interconnect and a mix of Xeon and Xeon Phi processors. And finally, number eight is the ABCI system built from Xeon SP-6148 Gold processors and Nvidia Tesla V100 SXM2 GPU accelerators, which as an aggregate of 32.6 petaflops peak and 19.9 petaflops sustained, or only 61 percent computational efficiency. This machine, built by Fujitsu, uses the 100 Gb/sec InfiniBand interconnect from Mellanox.
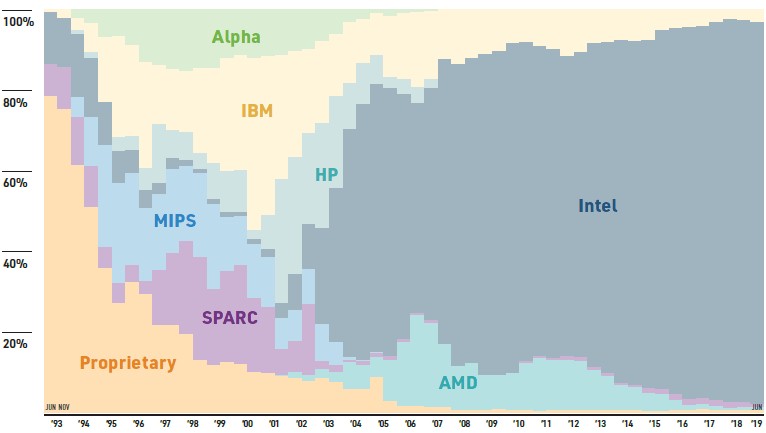
Intel has been the dominant supplier, by system count at least, of the processors used in supercomputers since around 2003 or so, and that has not changed one bit this time around. Intel has a very commanding 95.6 percent share of the CPUs on the Top500 systems, and here is where we get a little picky about the list itself. As we have pointed out for years, an increasing number of machines that are running and submitting Linpack results have nothing – absolutely nothing – to do with HPC workloads or even AI workloads and are just being submitted by companies in the United States and China, with more modest shenanigans in Europe and Japan, to bolster their countries rankings on the Top500. There is no rule that a submitted machine has to be doing HPC or even AI as its day job to submit results, and the hyperscalers and cloud builders, not to mention tier two webscale companies and other service providers, have enough iron laying around to run the tests and pack the list. This distorts the HPC nature of the list and actually drives real HPC centers off the list, and perhaps more importantly, makes that Moore’s Law gap look a lot less big than it probably is on real HPC work.
We find this particularly annoying, and we wish further that there was some sort of vetting on the Top500 list to make sure that a machine is actually doing real HPC work most of the time before its results are submitted. We want to really understand the HPC trends, not the trends of the machines that were set up to run the Linpack benchmark test. We are fairly confident that the machines at the top of the Top500 list as well as any machine that is clearly at a government, research, or academic site represent real HPC iron. Those machines labeled in industry – particularly telecom, hosting, service provider, and such – are all suspect until proven otherwise. And that is a shame, really. We do not believe for even a second that China is doing more actual HPC supercomputing than the United States is doing. At least not yet, anyway.
Machines loaded up with accelerators, which represent more than a quarter of the overall Top500 list, are all almost certainly doing HPC and/or AI work.
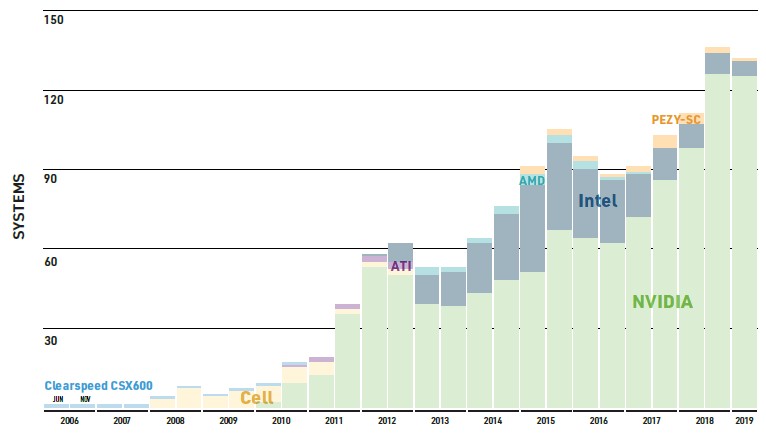
Machines using the Tesla V100 GPU accelerators in one form factor or another are in 62 systems, or 12.4 percent of the lost, but have 621.4 petaflops of peak performance and 406.3 petaflops of sustained performance, or about a quarter of the 1.56 exaflops of performance on the June 2019 list. The earlier Tesla P100 GPU accelerators are in 46 machines (9.2 percent of systems), but have 160.8 petaflops of peak and 94.6 petaflops of sustained Linpack performance (6.1 percent of aggregate performance). There are twelve other machines using Nvidia GPU accelerators that made the list, but their sustained performance only adds up to 44.7 petaflops, which ain’t much. There are only two machines that are based exclusively on the Xeon Phi many-core processors from Intel, and they are at this point noise in the data; there are a number of hybrid Xeon-Xeon Phi machines that have pretty reasonable floating point performance coming from the Xeon Phis, but these are not extracted in the summary data from the Top500.
The point is, accelerated systems are not yet normal, but they are getting there for supercomputing. Real supercomputing for capability-class systems, not capacity-class machines that are often running hundreds or thousands of applications that may or may not have been tuned to run on GPUs or even across more than 128 or 256 CPU cores. Nvidia created this market, and now AMD and Intel are both going to come in and try to compete, and that will drive up innovation and drive down pricing – both of which are good for customers but maybe not so good for the vendors. It is already hard to make money in HPC, and now it is going to get harder in the exascale era.


The Mystery Of Tianhe-3, The World’s Fastest Supercomputer, Solved?
We don’t like a mystery and we particularly don’t like it when what is very likely the most powerful supercomputer in the world – at this time anyway – is veiled in secrecy. But that is what the Tianhe-3 supercomputer built for the National Supercomputer Center in Guangzhou, China has …
Cadence Sells Custom GPU Supercomputers To Run New CFD Code
If money and time were no object, every workload in every datacenter of the world would have hardware co-designed to optimally run it. But that is obviously not technically or economically feasible. Just the same, sometimes a workload is so important that it warrants a highly tailored system to run …

At Long Last, HPC Officially Breaks The Exascale Barrier
Significant business and architectural changes can happen with 10X improvements, but the real milestones upon which we measure progress in computer science, whether it is for compute, storage, or networking, come at the 1,000X transitions. It has been nearly two decades since the “Roadrunner” hybrid Opteron-Cell was fired up at …
If you discount the 237 “Internet Company,” “Cloud Provider,” “Service Provider,” “Hosting Services,” and similar systems, then the 134 hybrid accelerated systems make up just over half of the remaining 263 TOP500 HPC systems. I count the TaihuLight as a hybrid system, since its 260 cores comprise four quadrants, each with a management cores and 64 compute cores, even if it is delivered as a single chip.
I could not agree more, and have been thinking along similar lines.