

It is difficult to talk about AI at scale without invoking the decades of work that has happened in the supercomputing trenches. This is where much of the underlying GPU foundation was built, not to mention various other elements in storage, networks, and systems software to keep beefy CPUs and accelerators fed.
This week at The Next AI Platform event in San Jose we will be talking about high performance computing infrastructure, but not in the traditional scientific and academic sense. This is because of this pioneering work in supercomputing that is leading us to scalable systems for AI—and these systems do not look much different than what one might find at a national lab with arrays of GPU-dense servers matched against high core-count CPUs with intense demands on networks and storage.
There are few storage companies that have stood the test of time quite like Panasas. They were among the first to deliver a parallel file system to meet the new demands of the cluster era in supercomputing and have since broadened those roots to capture large-scale systems outside of traditional HPC, including AI.
One of the company’s lead architects, Curtis Anderson tells The Next Platform that just like the era of monolithic supercomputers gave way to one of scale-out architectures, the same thing will happen in AI. He cites the new monolithic supercomputers of AI—the GPU-dense machines like Nvidia’s DGX appliances as a good example. While these are good at solving complex AI training problems now, the dominant architecture will evolve as a scale out problem in part because of I/O bottlenecks.
“AI will adopt some of the best practices HPC learned over its scale out journey,” Anderson argues and “AI storage will start from HPC storage but diverge as needed.”
There are several differences between HPC and AI storage requirements, however. In HPC, performance is measured by a faster total execution of the application, a metric that includes I/O performance with a great deal of programmer effort put into optimization of I/O. In AI performance for training is gauged by never letting the GPU go idle, something that is targeted by the neural network models themselves versus I/O specific developer work in HPC to optimize.
Also, in HPC, large sequential reads and writes of very few large files is the norm with “read ahead” as a common mechanism to hide latency in storage system latency. For AI, these large reads are much less prevalent. The real challenges lie in moderate sized random reads inside a set of moderately-sized files. In other words, read-ahead does not solve any problems, the real challenge is moving data with ultra-low latency. And ultimately, bandwidth is a key consideration over the pure low-latency IOPS needed in AI.
Despite some of these differences, Anderson says that as enterprises adopt AI they are building HPC datacenters—whether they call them that or not. Just as HPC progressed from single mission sites to shared resource centers that could support a wide range of applications and I/O workloads, enterprises will have their own workloads with AI part of the essential mix. “Storage should automatically ensure data coherency and performance across all users,” he adds, noting that there needs to be a flexible storage architecture in place to support the needs of mixed workloads.
There are other complicating factors with such mixed workloads from a storage perspective. For instance, labelled and prepared AI training data is a valuable resource that does not tend to get deleted. This requires scale-out storage with automatic, incremental, and transparent growth.
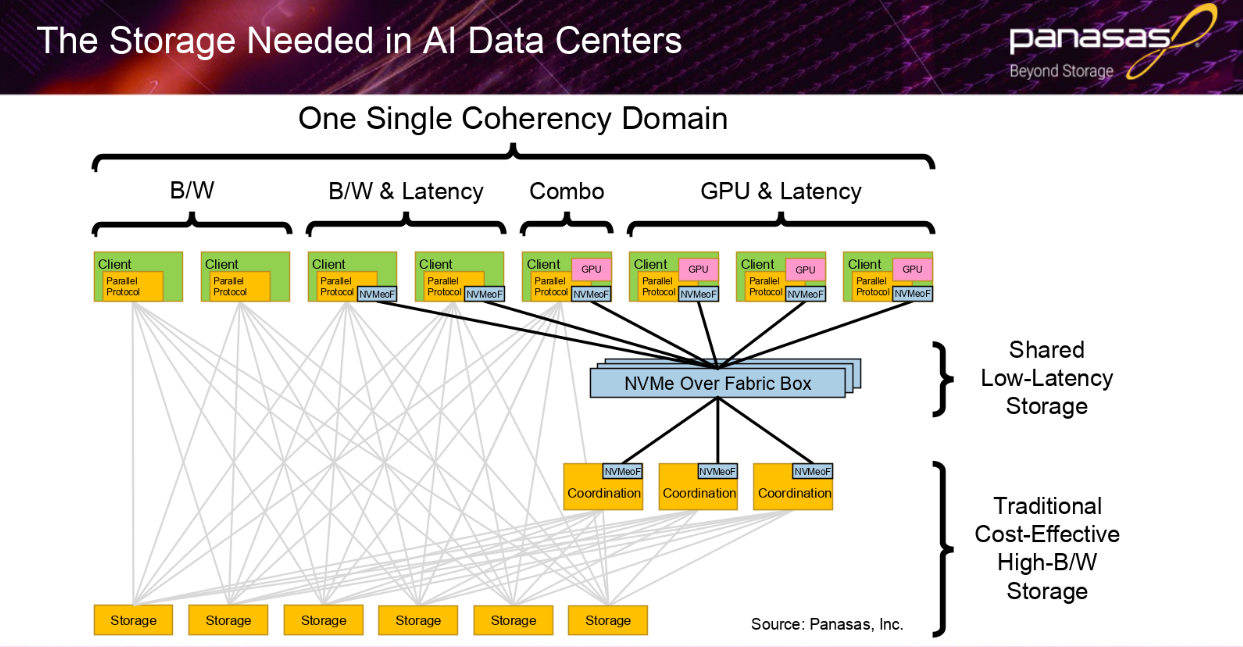
“If you multiply all the other performance needs, including growth in total capacity, total available bandwidth has to grow proportionally. As newer GPUs and ASICs are released, bandwidth needs to growth proportionally as well. Add to this that demand for results is so high that the user wants the wall clock time to go down as well,” Anderson explains.
While a project might go cold, all of that training data stays hot. The key to managing this is uniform storage access density. In other words, users should not have cold data that is slower to access, but instead scale-out low latency, incremental growth of capacity and performance with access to all the same performance, POSIX simplicity, and low TCO.”
Even though the workloads are changing, the evolutionary path of systems that Panasas has charted is familiar. From monolithic architectures designed to tackle one type of problem to a far more distributed, scale-out approach, the real challenge has been keeping pace with data. With decades of work on the file system and storage hardware co-design front during that first transition, the company is seeing where the old best practices carry over into the new world of AI with all of the reliability and manageability of the more traditional one.
We will be talking with Anderson more on this topic at The Next AI Platform event where he is a special speaker on the interplay between HPC and AI storage and where these converge, diverge, and all points in between.


Adding ML To Legacy Applications Without The Learning Curve
If you read The Next Platform, you probably love hardware and there are probably two reasons for that. First of all, it is the substance on which ephemeral codes flit about, and it is more immediately graspable in terms of feeds and speeds than is software. The focus on either …
Be the first to comment