

In a wide-ranging keynote address that ran nearly three hours at the GPU Technology Conference in San Jose, Nvidia co-founder and chief executive officer Jensen Huang talked up the company’s successes and new products across its graphics, robotics, and AI and HPC lineups. Huang also brought Mellanox co-founder and chief executive officer Eyal Waldman onstage to welcome Mellanox into the Nvidia fold, just a week after purchasing the company for $6.9 billion.
In the HPC space, Nvidia is still basking in the glow of its 2018 achievements, which saw the company expand its dominance in both traditional and AI-flavored HPC with its Tesla V100 GPU. In that regard, Huang reminded GTC attendees that his company’s GPUs now power the most powerful supercomputers in the United States (Summit), Europe (Piz Daint), and Japan (ABCI) and are running inside 22 of the 25 most energy-efficient systems in the world. Huang also noted that GPU computing is penetrating more deeply into commercial domains like retail, manufacturing, and finance as demand for data analytics and machine learning in those areas continues to grow. “They will all be high performance computing customers,” he said.
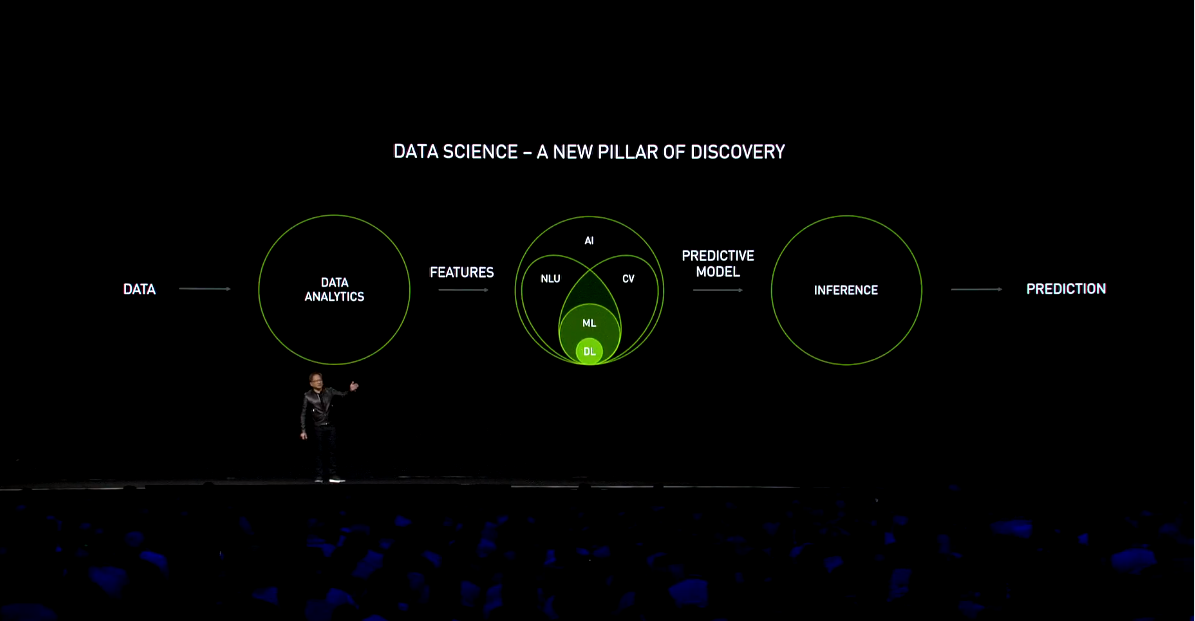
But what Huang really wanted to get across was the idea that data science has become the new driver across the computing landscape, encompassing analytics, AI/machine learning, and inferencing. According to Huang, there are three factors that make data science such a big deal today: the generation of enormous amount of data from sensors and other devices, breakthroughs in machine learning algorithms that produce highly accurate models, and the availability of large amounts of computational hardware (meaning Nvidia GPUs). But, as in all things computational, there never seems to be enough. “Data science is the new HPC challenge,” Huang asserted.
To meet that challenge, Nvidia is introducing what it’s calling the data science server, a platform aimed at hyperscale and enterprise datacenters. Whereas the latest DGX-2 box Nvidia has been selling is built as an AI supercomputer in the form of an appliance, Huang cast the data science server as a more all-encompassing solution. As a result, instead of the handful of organizations that can buy a $399,000 DGX-2 appliance, the data science server will make the technology available to the three million or so data scientists that Huang claims now roam the Earth.
But because the new server is aimed at a different market, it’s an altogether different beast, and a much less powerful one at that. Instead of the scale-up design of the DGX-2, where each enclosure houses 16 Tesla V100 GPU accelerators and 512 GB of HBM2, the Data Science server is built as a scale-out platform, with just four Tesla T4 accelerators and 64 GB of GDDR6. Given the less impressive mixed precision performance levels of the T4 (65 teraflops) compared to a V100 (125 teraflops) and the fact that there are less of them, the data science server tops out at 260 peak teraflops, as against the 2 peak petaflops delivered by the DGX-2.

The reason for the more modest specs is that the Data Science server has to live within the space, power, and cost constraints of conventional datacenters. From its inception, the T4 was designed for enterprise and cloud setups, primarily as an inference engine for trained neural networks. It draws just 70 watts of juice, compared to 300 watts for the top-end V100 with NVLink. It’s also a lot less expensive that its more powerful older sibling. But as with any scale-out server, what it lacks in performance can be made up in volume. In this case, the design supports Mellanox or Broadcom network interface cards for linking the servers into clusters and to the outside world.
Although the T4 is really geared for inferencing work, it can do training as well, just not as adeptly as a V100. In general though, inferencing makes more sense for a platform destined for hyperscale and enterprise buyers, since by sheer volume, inferencing dominates the compute cycles at most businesses that currently use machine learning, not to mention at Google, Amazon, Baidu, and every other web service provider on the planet.
The data science server is not just different from the DGX-2 in hardware, though. The software stack has diverged as well. The central element is something called RAPIDS, a suite of open source libraries that Nvidia helped develop for GPU-accelerated data science. It offers CUDA-based packages for data preparation and analytics, model training, and soon, visualization. The whole thing is built atop Apache Arrow, an open source data management package that uses in-memory technology to speed analytics work.
The server will also use CUDA-X AI, a set of GPU acceleration libraries that span the data science workflow, encompassing analytics, machine learning, inferencing, and other areas. It is integrated into all the major deep learning frameworks and is used by all big cloud providers, including AWS, Google, and Microsoft, as well as by Charter, PayPal, SAS, and Walmart.
Unlike the DGX boxes, which are built and sold by Nvidia, the data science servers will be manufactured by OEMs, initially HPE, Lenovo, Dell EMC, Fujitsu, Sugon, and Inspur. These will be targeted to enterprise users. AWS will be also be building Data Science servers (or something closely resembling them) for its upcoming G4 instance. The G4 will offer cloud customers 1 to 8 T4 GPUs, along with Intel CPUs, local NVM-Express storage, and up to 100 Gb/sec networking. The new instance is primarily aimed at customers looking to do their inferencing work on their trained models, although graphics, video transcoding, and media streaming are other possible applications.
It remains to be seen how successful these T4-powered servers will be. Unlike in training, where the V100 and its predecessor had a clear computational advantage over CPUs and FPGAs, for inferencing, the advantages of GPUs are less clear-cut. Plus, chip startups like Habana Labs, which offers a custom-built inference card, and the prospect of neuromorphic computing could usher in a wave of specialization that might prove difficult to compete against with more general-purpose silicon.
Nonetheless, Nvidia’s success in building chips aimed at HPC and AI and developing a robust ecosystem around them is not to be taken lightly. If the last decade has shown anything, it is that, given the right software, GPUs have proven to be superior architecture for a lot of applications dependent on data throughput and matrix math. If Huang and company think they can parlay that into a bigger data science play, who are we to argue?

Nvidia To Build DGX Complexes In Clouds To Better Capitalize On Generative AI
GPU computing platform maker Nvidia announced its financial results for its fiscal fourth quarter ended in January, which showed the same digestion of already acquired capacity by the hyperscalers and cloud builders and the same hesitation to spend by enterprises that other compute engine makers for datacenter computing are also …

HPC In 2020: AI Is No Longer An Experiment
If we could sum up the near-term future of high performance computing in a single phrase, it would be more of the same and then some. Although no “revolution” is in the horizon, the four major trends of the past decade – the expansion of artificial intelligence technology, processor diversification, …
Oracle Takes The Whole Nvidia AI Stack For Its Cloud
The top hyperscalers and clouds are rich enough to build out infrastructure on a global scale and create just about any kind of platform they feel like. They are just that rich, and by using their services at massive scale, all of us collectively pay for the many degrees of …
Be the first to comment