

Earlier in this decade, when the hyperscalers and the academics that run with them were building machine learning frameworks to transpose all kinds of data from one format to another – speech to text, text to speech, image to text, video to text, and so on – they were doing so not just for scientific curiosity. They were trying to solve real business problems and addressing the needs of customers using their software.
At the same time, IBM was trying to solve a different problem, naming creating a question-answer system that would anthropomorphize the search engine. This effort was known as Project Blue J inside of IBM (not to be confused with the open source BlueJ integrated development environment for Java), was wrapped up into a software stack called DeepQA by IBM. It was this DeepQA stack, which was based on the open source Hadoop unstructured data storage and analytics engine that came out of Yahoo and another project called Apache UIMA, which predates Hadoop by several years and which was designed by IBM database experts in the early 2000s to process unstructured data like text, audio, and video. This Deep QA stack was embedded in the Watson QA system that was designed to play Jeopardy against humans, which we talked about in detail here eight years ago. The Apache UIMA stack was the key part of the WatsonQA system that did natural language processing that parsed out the speech in a Jeopardy answer, converted it to text, and fed it into the statistical algorithms to create the Jeopardy question.
Watson won the contest against human Jeopardy champs Brad Rutter and Ken Jennings, and a brand – which invoked IBM founder Thomas Watson and his admonition to “THINK” as well as Doctor Watson, the sidekick of fictional supersleuth Sherlock Holmes – was born.
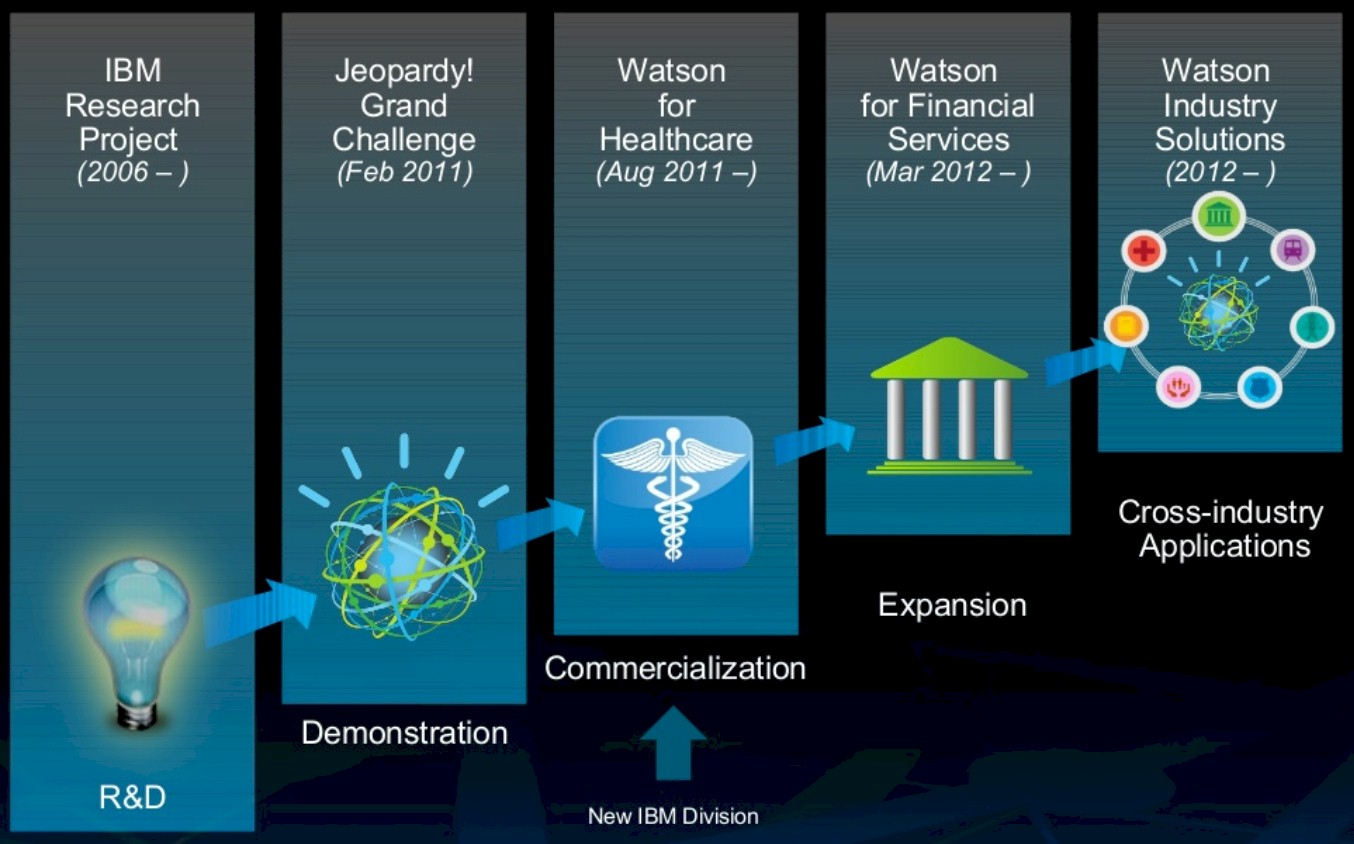
Rather than make Watson a product for sale, IBM offered it as a service, and pumped the QA system full of data to take on the healthcare, financial services, energy, advertising and media, and education industries. This was, perhaps, a mistake, but at the time, in the wake of the Jeopardy championship, it felt like everything was moving to the cloud and that the SaaS model was the right way to go. IBM never really talked in great detail about how DeepQA was built, and it has similarly not been specific about how this Watson stack has changed over time – eight years is a long time in the machine learning space. It is not clear if Watson is material to IBM’s revenues, but what is clear is that machine learning is strategic for its systems, software, and services businesses.
So that is why IBM is finally bringing together all of its machine learning tools and putting them under the Watson brand and, very importantly, making the Watson stack available for purchase so it can be run on private datacenters and in other public clouds besides the one that IBM runs. To be precise, the Watson services as well as the PowerAI machine learning training frameworks and adjunct tools tuned up to run on clusters of IBM’s Power Systems machines, are being brought together, and they will be put into Kubernetes containers and distributed to run on the IBM Cloud Private Kubernetes stack, which is available on X86 systems as well as IBM’s own Power iron, in virtualized or bare metal modes. It is this encapsulation of this new and complete Watson stack with IBM Cloud Private stack that makes it portable across private datacenters and other clouds.
By the way, as part of the mashup of these tools, the PowerAI stack that focuses on deep learning, GPU-accelerated machine learning, and scaling and distributed computing for AI, is being made a core part of the Watson Studio and Watson Machine Learning (Watson ML) software tools. This integrated software suite gives enterprise data scientists an end-to-end developer tools. Watson Studio is an integrated development environment based on Jupyter notebooks and R Studio. Watson ML is a set of machine and deep learning libraries and model and data management. Watson OpenScale is AI model monitoring and bias and fairness detection. The software formerly known as PowerAI and PowerAI Enterprise will continue to be developed by the Cognitive Systems division. The Watson division, if you are not familiar with IBM’s organizational chart, is part of its Cognitive Solutions group, which includes databases, analytics tools, transaction processing middleware, and various applications distributed either on premises or as a service on the IBM Cloud.
It is unclear how this Watson stack might change in the wake of IBM closing the Red Hat acquisition, which should happen before the end of the year. But it is reasonable to assume that IBM will tune up all of this software to run on Red Hat Enterprise Linux and its own KVM virtual machines and OpenShift implementation of Kubernetes and then push really hard.
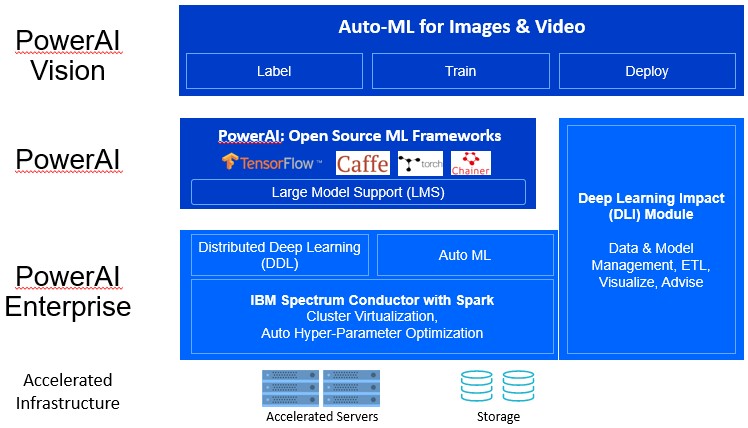
It is probably helpful to review what PowerAI is all about and then show how it is being melded into the Watson stack. Before the integration and the name changes (more on that in a second), here is what the PowerAI stack looked like:
According to Bob Picciano, senior vice president of Cognitive Systems at IBM, there are more than 600 enterprise customers that have deployed PowerAI tools to run machine learning frameworks on its Power Systems iron, and obviously GPU-accelerated systems like the Power AC922 system that is at the heart of the “Summit” supercomputer at Oak Ridge National Laboratory and the sibling “Sierra” supercomputer at Lawrence Livermore National Laboratory are the main IBM machines people are using to do AI work. This is a pretty good start for a nascent industry and a platform that is relatively new to the AI crowd, but perhaps not so different for enterprise customers that have used Power iron in their database and application tiers for decades.
The initial PowerAI code from two years ago started with versions of the TensorFlow, Caffe, PyTorch, and Chainer machine learning frameworks that Big Blue tuned up for its Power processors. The big innovation with PowerAI is what is called Large Model Support, which makes use of the coherency between Nvidia “Pascal” and “Volta” Tesla GPU accelerators and Power8 and Power9 processors in the IBM Power Systems servers – enabled by NVLink ports on the Power processors and tweaks to the Linux kernel – to allow much larger neural network training models to be loaded into the system. All of the PowerAI code is open source and distributed as code or binaries, and thus far only on Power processors. (We suspect IBM will go agnostic on this eventually, since Watson tools have to run on the big public clouds, which with the exception now of the IBM Cloud, do not have Power Systems available. (Nimbix, a specialist in HPC and AI and a smaller public cloud, does offer Power iron and supports PowerAI, by the way.)
Underneath this, IBM has created a foundation called PowerAI Enterprise, and this is not open source and it is only available as part of a subscription. PowerAI Enterprise adds Message Passing Interface (MPI) extensions to the machine learning frameworks – what IBM calls Distributed Deep Learning – as well as cluster virtualization and automatic hyper-parameter optimization techniques, embedded in its Spectrum Conductor for Spark (yes, that Spark, the in-memory processing framework) tool. IBM has also added what it calls the Deep Learning Impact module, which includes tools for managing data (such as ETL extraction and visualization of datasets) and managing neural network models, including wizards that suggest how to best use data and models. On top of this stack, IBM’s first commercial AI application that it is selling is called PowerAI Vision, which can be used to label image and video data for training models and automatically train models (or augment existing models supplied with the license).
So after all of the changes, here is what the new Watson stack looks like:

As you can see, the Watson Machine Learning stack supports a lot more machine learning frameworks, notably the SnapML framework that came out of IBM’s research lab in Zurich that is offering a significant performance advantage on Power iron compared to running frameworks like Google’s TensorFlow. This is obviously a more complete stack for machine learning, including Watson Studio for developing models, the central Watson Machine Learning stack for training and deploying models in production inference, and now Watson OpenScale (it is mislabeled in the chart) to monitor and help improve the accuracy of models based on how they are running in the field as they infer things.
For the moment, there is no change in PowerAI Enterprise licenses and pricing during the first quarter, but after that PowerAI Enterprise will be brought into the Watson stack to add the distributed GPU machine learning training and inference capabilities atop Power iron to that stack. So Watson, which started out on Power7 machines playing Jeopardy, is coming back home to Power9 with production machine learning applications in the enterprise. We are not certain if IBM will offer similar distributed machine learning capabilities on non-Power machines, but it seems likely that is customers want to run the Watson stack on premises or in a public cloud, it will have to. Power Systems will have to stand on its own merits if that comes to pass, and given the advantages that Power9 chips have with regard to compute, I/O and memory bandwidth, and coherent memory across CPUs and GPUs, that may not be as much of an impact as we might think. The X86 architecture will have to win on its own merits, too.


Systems Turn In A Good Year for Big Blue
You can’t turn back the hands of time, but if you are lucky enough in business, you can continue to find some modicum of relevance that outlasts your initial success and even adapt to new conditions as they inevitably and often unexpectedly change. Say what you will, but that is …
Another Crazy Idea: Intel Might Buy Globalfoundries
Back in March, when we wrote up Intel’s Integrated Device Manufacturing 2.0 strategy put forth in the vaguest of terms by then-new chief executive officer Pat Gelsinger, we quipped that Intel might be wishing as it launches Intel Foundry Services that it had some of its older fabs around with …

IBM’s Systems Business Awaits The Red Hat Effect
It is frustrating sometimes how IT vendors talk about themselves, particularly when it comes to public companies and those rare few who report financial results even though they are privately held. The summary data is compiled to give Wall Street and other investors the rosiest possible view of the company …
Does PowerAI can tell an IBM’s employee a copycat or a real maker? I wish PowerAI will bring justice back to IBM, and let integrity be the basement of IBM.
For the good and profit of each company the entire stack wants to be controlled in-house. For the best result of the enterprise that is ML-or-AI, all pieces ought to inter-operate. Obvs.
If, for example, one wishes to reform the American health-care process, the interoperation of each proprietary data format should be mandated. HA ! Why, do you imagine, that didn’t happen ??