
The history of digital computing is to provide increasing levels of abstraction to get programmers further and further away from directly manipulating the ones and zeros. So it is no surprise that so-called serverless computing is getting a lot of looks from developers who want to focus more on their applications and less on managing the infrastructure they run on.
As we at The Next Platform have discussed before, serverless computing doesn’t mean that the work is being done without servers, but rather that there is such a high level of abstraction for the compute that the server is no longer a concern for developers. They don’t have to worry about it because it’s a problem that someone else – like a cloud provider – has to deal with.
Vendors are growing their serverless computing capabilities – Amazon Web Services’ Lambda offering being an example – and enterprises continue to explore the possibilities. In a survey this year, RightScale, which offers a hybrid cloud management platform, found that serverless computing was the fastest-growing cloud service, with use growing from 12 percent last year to 21 percent in 2018. See the chart below:

“We’re finding that serverless has really proven itself as a technology has proven as its worth because of the benefits it brings to our customers,” Reza Shafii, vice president of platform services for OpenShift at Red Hat, tells The Next Platform. “One is it just allows for more effective or efficient development. People can just write functions and have them be dependent on specific events and then that function is just deployed to production really easily. So that’s one of the reasons why, for example, [AWS’] Lambda is so successful. That’s good and interesting to us, but it’s probably not just the most important part for us. The second one is the one that our customers are asking for even more, which is that once an application – not just a function – is serverless, it means that its runtime becomes just-in-time. The application is deployed to the servers just in time and then brought back to zero. And that on-demand aspect leads to a great deal of resource optimization at the compute level. So a Lambda function executes only for the time when an event happens. If it’s tied to an API event, it only processes that API and it goes back with no other resources being used.”
Here’s a look at what Red Hat views as an ideal serverless platform:
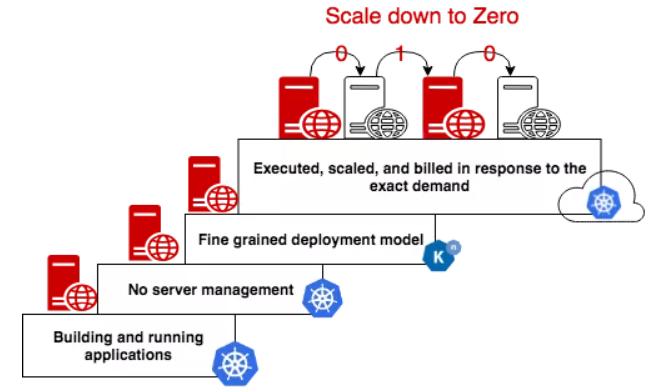
Earlier this year, Red Hat, Google, SAP, IBM, and Pivotal announced a platform that brings together serverless computing with the Kubernetes open source container orchestration system. The idea behind Knative, as this effort is called, is to offer a set open-source components that enables developers to create container-based serverless applications that can be easily moved between cloud providers, an important consideration at a time when adoption of containers for building applications that can be moved to the cloud is growing and more enterprise are putting their applications and data into more than one public cloud.
“Knative allows developers to easily leverage the power of Kubernetes,” Oren Teich, director of product management for Google Cloud, and Aparna Sinha, group product manager, wrote in a blog post. “Although Kubernetes provides a rich toolkit for empowering the application operator, it offers less built-in convenience for application developers. Knative solves this by integrating automated container build, fast serving, autoscaling and eventing capabilities on top of Kubernetes so you get the benefits of serverless, all on the extensible Kubernetes platform. In addition, Knative applications are fully portable, enabling hybrid applications that can run both on-prem and in the public cloud. Knative plus Kubernetes together form a general purpose platform with the unique ability to run serverless, stateful, batch, and machine learning workloads alongside one another.”
According to Red Hat’s Shafii, Knative solves a number of problems, including the fact that with some of the larger cloud providers like AWS and Microsoft Azure, many of the events available are tied to the providers’ infrastructures.
“Essentially it solves almost all of the problems in that it says, ‘Look, we are an open-source framework that allows for event sources to come in and plug themselves in amid any event,” he says. “The Knative engine can also then trigger any application to come to life, execute and process, and then go back to zero.”
Knative is now taking another step forward. Google has made Knative available to users via a serverless add-on to its Google Kubernetes Engine (GKE) since July, and the cloud provider has since added improvements found in the Knative 0.2 release, which was announced in November and includes an eventing component to go along with the serving and build components.
At this week’s KubeCon 2018 in Seattle, Red Hat, IBM and SAP are putting Knative in their commercial offerings. IBM is enabling enterprises to install Knative in their IBM Cloud Kubernetes Service, making the technology available in GitHub. SAP is making Knative available in its SAP Cloud Platform and as part of the software company’s Kyma project.
For its part, Red Hat – which is expected to become part of IBM after Big Blue’s $34 billion acquisition closes next year – will add support for Knative in its OpenShift Kubernetes platform to help customers build and run serverless applications and integrate with the company’s OpenShift Server Mesh based on the Istio and Kiali projects. Red Hat also will use Strimzi, which is designed to make it easier to run Apache Kafka on OpenShift or Kubernetes. That’s done through Red Hat AMQ Streams for eventing and Camel-K, an integration framework based on Apache Camel through which multiple event sources can be used to trigger serverless applications. Knative in OpenShift will be available in a development preview early next year.

IBM Starts Walking The Hybrid Cloud And AI Talking
If Big Blue is going to talk the hybrid cloud and AI talk, as it seems to do incessantly, then the company has to walk it. And perhaps the most interesting thing that was said as part of the company’s discussion of its first quarter 2023 financial results was its …
VMware Bets On Enterprises Wanting Kubernetes And Virtualization Mashup
For more than two decades, VMware has made its money sensing the direction that enterprise IT is going and getting there before they do with products to addressing their needs. It would be hard to find something more fortunate than delivering enterprise-grade virtualization for X86 servers as the Great Recession …

Quantum Computing Providers Pick Their Dance Partners
Toward the end of 2019, a flurry of announcements by some of the most prominent IT companies suggests that collaborations will become increasingly important in the quantum computing space as the players jockey for position in the nascent market. The companies in question include some of the biggest in the …
Be the first to comment