

For more than a decade, datacenter system administrators have been trying to figure out how to get their increasingly complex infrastructure under control and to manage them in a way that allows them to keep up with, adapt to, and scale with the rapid changes that are the new norm. They can’t simply rely on shell scripts alone any longer to run the servers. Shell scripts don’t scale, certainly not enough to address the system configurations on the tens to hundreds of thousands of servers that can be found in modern datacenters.
In recent years, the rise of DevOps has been fueled by software that has enabled system admins to automate many of the functions tied to managing servers, from system configuration to program installation. Key among those are open source applications like Puppet, Chef, and Ansible, which is now part of Red Hat (which soon will be part of IBM), all of which have a slightly different metaphor for managing infrastructures, both on premises and now in public clouds and expanding out to the edge. As we’ve noted at The Next Platform, many of these applications, some more than ten years into their lives, are now morphing into configuration and deployment automation platforms.
Puppet essentially comes in two versions, open source Puppet and the commercial offerings from Puppet (the company), whose HPC evangelist, Paul Anderson, went to the recent SC18 conference in Dallas to remind attendees that Puppet – both the open source and commercial versions – can play important roles in HPC and in addressing what he called the “Iron Triangle” of demands of modern HPC administrators: high throughput, complex configurations, and risk minimization.

“There’s an expectation that you, as an admin, are going to keep your system high throughput,” Anderson said. “The jobs must run. The simulations must finish. At the same time, it’s your job to minimize risk. No downtime, no jobs failing. Additionally, you have to deal with configuration complexity. Teams are asking you to support new versions of software, external things like new versions of operating systems, new principal investigators are coming in and asking for things. You’re partnering with some new organizations and they’re demanding that you do something a little bit differently. So somehow you have to balance all of these things and it’s your classic kind of pick-to solution. So the classic way of dealing with this is to say, we’re not going to deal with the complexity of configuration. We are going to give you high throughput and we’re going to avoid this risk by having a static cluster that has a static stack and you will adjust how you do things to our way of running the cluster and if you do that, we can give you what you want.”
Such an approach doesn’t work anymore and often leads to groups within an organization pulling some money together and buying their own little cluster, arguing that the institutional infrastructure is too monolithic and static.
“If you kind of expand that out, each individual team may have low risk and each individual team may have very different complexity, but you just lost your throughput because a lot of these clusters are going to sit idle a lot of the time,” he said. “And if you want configuration complexity and high throughput, most likely you’re going to try to solve that in a classical way by having a really smart scheduler, a kind of handcrafted scheduling approach with your cue and you are going to have many, many, many golden images. You are going to do something like dynamic provisioning, where you are going do just-in-time. If you want all three parts of the Iron Triangle, you are going to end up doing a whole lot more work. It’s going to be a whole lot more stress.”
The rise of DevOps as well as the cloud and containers, is helping to address the issues in HPC, and Puppet plays a key role, Anderson said.
Puppet, the company, has been around since 2005 and the company has more than 500 employees. In addition, more than 40,000 organizations use Puppet, according to the Puppet site, so it has gained traction. The HPC site CERN, home of the Large Hadron Collider, has been using the open source technology since at least 2013, he noted. DevOps has evolved since the days of 2010, when version control (like Git), infrastructure as code (Puppet), and IaC pipeline tools (Hudson, later known as Jenkins) were coming to the forefront.
“A lot of organizations that were more focused on services – sort of born-in-the-cloud type companies, your Googles, your Facebooks, your Amazons your Netflixes – they were looking at this stuff and saying, ‘How can we use this to drive business value faster?’” Anderson said. “’How can we take customer input and put it into our products faster so that we can compete more effectively?’ Basically, this has been kind of permeating through the culture everywhere. So why Puppet? Why is Puppet a good fit for HPC?”
There are myriad reasons, he said, one being that Puppet is a declarative desired-state language. The admin states the configuration they need and lets the infrastructure figure out how to get it to them. It’s about resources that make up the desired state. The software figures out the desired configuration, can simulate changes before they are put into motion and enforced and ensures the deployed desired state is enforced automatically. All this can be compiled in a catalog.
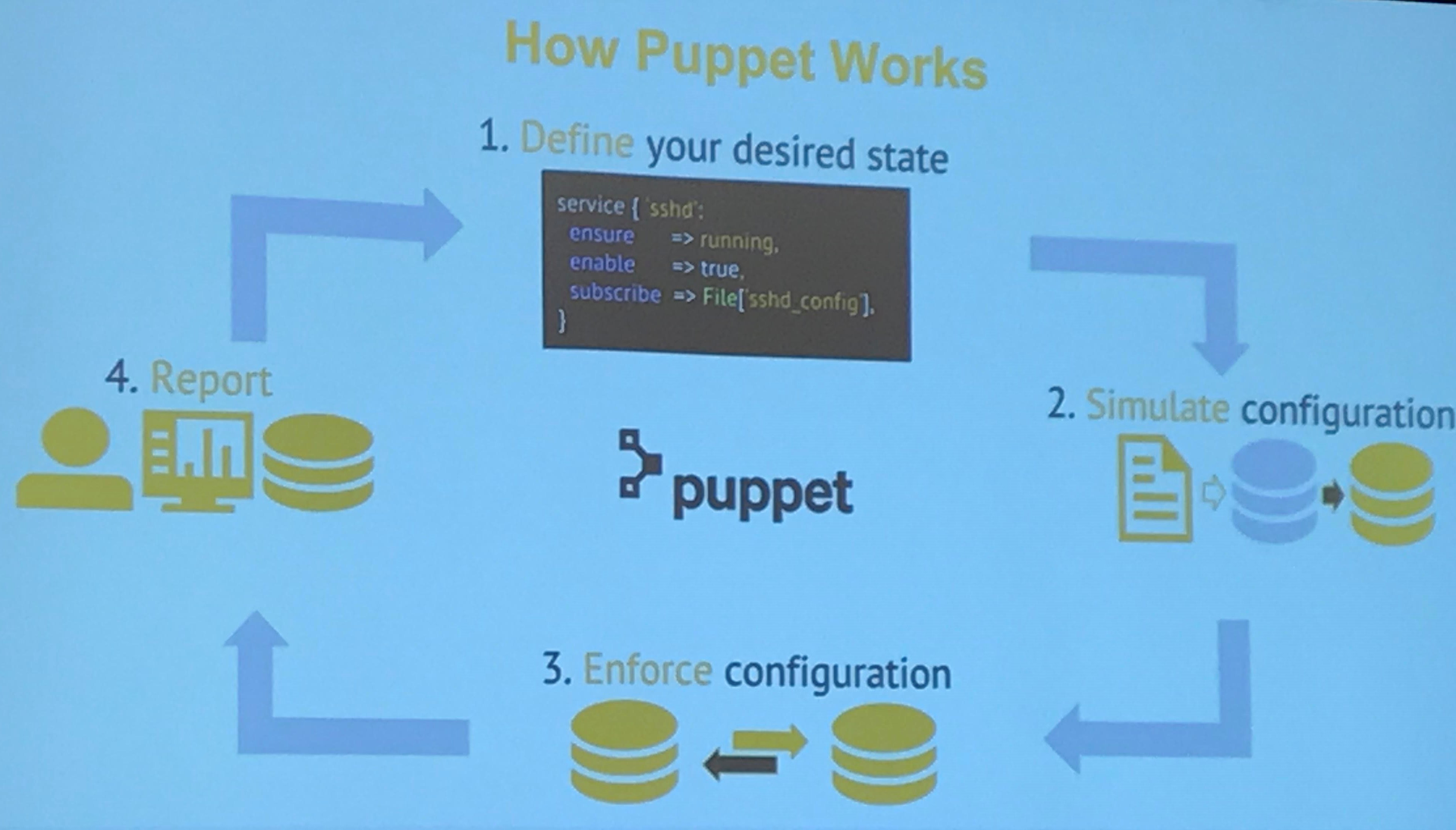
“You just say what you want,” Anderson explained. “Our abstraction layer takes care of it for you, so all of these resources you sort of compose them all together to create the ultimate configuration you’re interested in and we give you ultimately what you’re looking for. And so this leads to this concept called the catalog, which is the entirety of all the desired state for a node. It’s a mathematical construct called a directed acyclic graph.”
Conflicting configurations are cached, and everything can be represented visually in JSON for analytical and historical purposes.
Puppet can handle highly diverse HPC hardware environments, from compute nodes of different speeds to differences in storage nodes to the use of GPUs from Nvidia or AMD or FPGAs from Xilinx or Intel. Software is managed, whether it is computational fluid dynamics (CFD), bioinformatics, data analytics, or machine learning.
“Do you have a diversity of hardware?” he said. “Some of your systems on physical servers, some of them on virtual, perhaps? If so, do you want to install the appropriate vendor tooling? Do you want to install the right thing to manage the virtual machines? You can manage BIOS, RAM, CPU. Do you need to key off of the fact that the card is in the PCI port three versus four? Looking at your system as a state management problem as opposed to a sort of step-by-step recipe list of commands to run might be different.”
Anderson said organizations like NASA increasingly are doing on-demand HPC, using tools like OpenStack to create, grow and shrink virtual clusters, and Puppet can help manage these environments. In HPC, there is the “opportunity to do things on a master list mode so it scales a lot better. Older versions of Puppet do not scale very well at all. That’s what was cool in 2010. These days we have things like cache catalogs, tool chains, on-demand HPC orchestration, ephemeral nodes and containers.”


Expanding DevOps With Infrastructure As Code
The hyperscalers have taught us many lessons in the past two decades, and one of them is that everything that can be defined in software should be so that it can be controlled automatically and programmatically – and that goes double for hardware, which has required so much human babysitting …

Unified Memory: The Final Piece Of The GPU Programming Puzzle
Support for unified memory across CPUs and GPUs in accelerated computing systems is the final piece of a programming puzzle that we have been assembling for about ten years now. Unified memory has a profound impact on data management for GPU parallel programming, particularly in the areas of productivity and …
Burying The OpenMP Versus OpenACC Hatchet
I have been frequently asked when the OpenMP and OpenACC directive APIs for parallel programming will merge, or when will one of them (usually OpenMP) will replace the other. I doubt the two APIs will or can merge, and whether one replaces the other depends more on whether users abandon …
I’ve been using puppet for HPC deployments since 2012 or so. Works great and offers ease of mind, independent of the size of deployment.