
NVM-Express has been creating a quiet revolution in servers for several years now, providing a way for flash storage to bypass the traditional storage stack and the limitations of interfaces such as SATA and SAS, and instead pipe data directly into and out of the CPU through the high-speed PCI Express bus.
The new problem has been how to scale your flash storage outside the confines of a single server without losing all the low latency benefits of NVM-Express. Sticking NVM-Express SSDs into a traditional storage array still gives you something of a boost over standard SSDs, but then you are back to accessing the drives storage via the traditional storage stack, with the network or fabric creating extra latency.
To get around this, the industry came up with the idea of extending the NVM-Express protocol across the network as well, leading to NVM-Express over Fabrics (NVMe-oF). Unless you have Fibre Channel and want to use NVMe over Fabrics using Fibre Channel (FC-NVMe), this depends on (and in fact requires) the use of Remote Direct Memory Access (RDMA), whereby data is transferred directly from the memory of one system to another using the host adapter or network interface card, a technology that was initially created for the compute jobs on HPC clusters running parallel simulations and models on InfiniBand networks. RDMA has subsequently been pulled into Ethernet adapters with a variant called RDMA over Converged Ethernet, or RoCE.
But this approach of using fabrics to link NVM-Express flash storage introduces a further problem, which is that in a traditional storage array, the actual drives are hidden away behind the controller, which handles functions such as RAID and presents the drives to the outside world as a set of logical volumes. Bypassing the controller using RDMA effectively kills this model and turn an enclosure full of NVM-Express SSDs into Just a Bunch of Disks (JBOD, or JBOF as we are talking flash media).
One company that found a way around this is a startup called Excelero, which developed software called NVMesh, designed to run on standard X86 server hardware in order to deliver a scale-out software defined storage platform focused on block storage.
We did a deep dive into Excelero’s NVMesh software last year, and to reiterate, NVMesh gets around the problem of RDMA bypassing the storage controller or CPU by effectively moving the functions that would be performed by the controller into the NVMesh client software that runs on the application server instead.
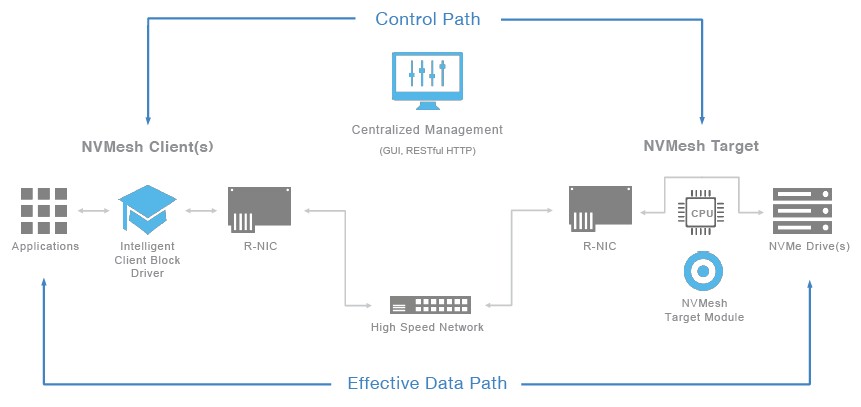
An NVMesh deployment thus comprises three components; the NVMesh client is installed on any server that needs to access the storage pool; an NVMesh Target Module runs on the storage servers; and a management module that provides for monitoring and configuration of the entire deployment. It should be noted that NVMesh also supports a converged deployment model, where the client and target module are installed on all nodes in a rack, so that a shared storage pool is created using the direct attached NVM-Express storage in a cluster of application servers.
All of this creates a scalable, distributed block storage platform that provides latency down to a claimed 5 microseconds, and has seen Excelero pick up a number of high profile customers and technology partners, such as NASA and General Electric.
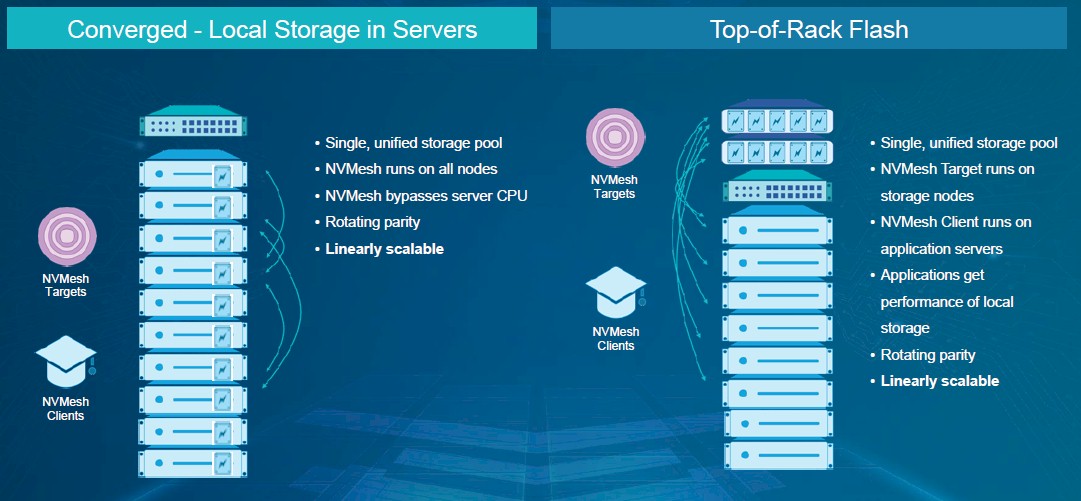
However, that impressive level of performance comes at a cost. The initial release of NVMesh only supported RAID 0,1, and 10 data protection, which took up half the storage capacity to provide redundancy. Using RDMA to access the NVME storage also restricted customers to using InfiniBand or Ethernet with support for RoCE v2, the latter of which would often mean investing in network adapters that supported this and also call for updates to the network infrastructure.
With feedback on this from customers, Excelero decided that NVMesh 2.0 should be more flexible and allow customers to trade a bit of performance in order to get a higher level of usable capacity. It has also been developed to offer a broader choice of networks and protocols, a move which the firm hopes will broaden the enterprise appeal of NVMesh beyond those early customers which simply demanded the lowest possible latency.
“We had customers that said ‘this is great, you have hands down the highest performing solution in the market. We love it.’ But just like you might love a Ferrari or a Bugatti, you don’t always need to go down to the track and race, sometimes you just need to go to the grocery store,” Josh Goldenhar, vice president for customer success at Excelero, tells The Next Platform.
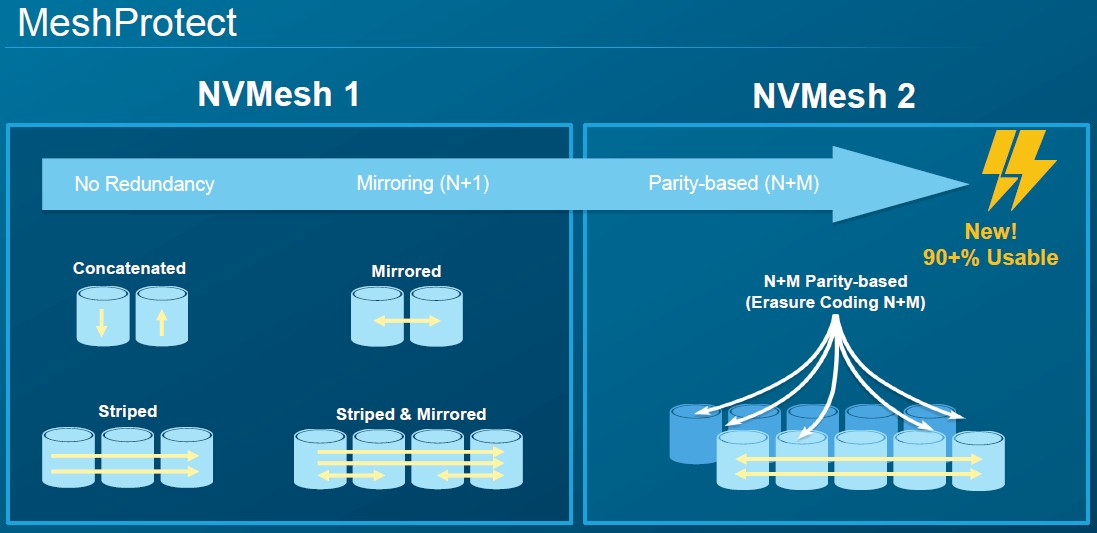
This new flexibility in NVMesh 2 starts with letting customers choose the level of protection they require, a feature Excelero has now dubbed MeshProtect, and which can allow up to 90 percent of the raw capacity to be available.
“MeshProtect before was RAID 0, RAID 1, and RAID 10, but now we’ve expanded that to be a distributed parity-based algorithm where you get to tune the amount of protection you want, so you can go anywhere from 4+1 all the way up to 10+2 or 11+1, so it’s a RAID 6-like algorithm, but it is distributed over the network,” Goldenhar explains. “If you want to call it erasure coding, that’s accurate, it is an erasure coding algorithm.”
As we noted earlier, NVMesh moves the functions that would be performed by the controller in a typical enterprise storage array into the client software running on the initiator system. This means that performance is able to scale linearly with capacity, Goldenhar claims.
“We distribute over every single client the ability to do mirroring, parity, and so on, and this has a lot of benefits. One, it makes us very, very scalable – as you scale out your clients and your back-end NVME and your networking, everything scales linearly, with no drop-off in performance as you scale.”
“Other systems that have controllers, where the controller is what does the data protection, that ends up being a bottleneck. That is why traditional all-flash arrays, such as from Dell XtremIO or Pure Storage FlashArray or Kaminario K2, the entire array has an upper-end limit of something like 700K IOPS, which is basically the equivalent of one NVME drive. They bottleneck because they have to do those data services, like protection, in that unit itself, and that becomes the bottleneck – you can only go as fast as your processing capability,” Goldenhar says.
Meanwhile, host connectivity in NVMesh 2 through MeshConnect has now been expanded to support Fibre Channel and standard TCP/IP links into the storage, enabling customers to use existing fabric connection technology. But this comes at the cost of losing some latency through not having RDMA support.
“For ease of use, people asked for TCP/IP. This also meant, even though we regard Mellanox to be a standard NIC, because you can just buy it off the shelf, we can’t change the fact that these are usually discrete, whereas if you buy a server from almost anybody these days you get 10 Gb/sec or 40 Gb/sec, some even give you 25 Gb/sec, but those Ethernet chips are not necessarily capable of RDMA, so to choose RDMA, you may need to put a discrete NIC in, which adds cost and you can argue adds complexity. Customers wanted us to use any NIC, and also they said they have a huge investment in Fibre Channel, so if you can find a way to not just cut out all our Fibre Channel hosts, do it,” Goldenhar says.
All this comes at the cost of losing some performance, but Excelero claims that using TCP/IP and Fibre Channel, customers should still expect to achieve tens to hundreds of thousands of IOPS on a per-host basis, at a quarter of the latency of all-flash arrays, with latency somewhere around the 200 microsecond range.
NVMesh 2 also introduces improved diagnostics, MeshInspect, now integrated into the management console. This offers insights into performance and capacity utilization, and is designed to help customers pinpoint where there may be an issue in their infrastructure that may be adding latency, whether this is in the servers, the NICs, the network switches or wherever.
Finally, Excelero is also providing reference architectures based on server hardware from enterprise vendors, including Lenovo, HPE, Dell, and Western Digital’s platform division.
“Everyone tells us they want software-defined everything and we want to use whatever server, but what they really mean is they want to use the server of their choice, and it usually boils down to them being a Dell shop or a Lenovo shop. They don’t want you to say you make an appliance, and really it’s a Supermicro box inside,” says Goldenhar.
NVMesh 2 is currently in the hands of beta customers and is set for general release in early January, according to Excelero. The firm claims that NVMesh plus servers and drives works out less expensive than purchasing an all-flash array at the same capacity, but with around 20 times less latency. Actual licensing is priced either by NVM-Express drives or NVM-Express ports in the servers, with pricing starting at $2,400 per NVM-Express drive.
Customers that have already used the existing NVMesh to their advantage include a soon-to-be announced AI software provider we have heard about, which uses Nvidia DGX-1 servers with Tesla GPUs to accelerate machine learning workloads. NVMesh enables the firm to use shared storage for their DGX nodes, instead of each working from its own local storage, according to Excelero. This is because the DGX-1 has SATA flash, which is limited by bandwidth, but the system has four 100 Gb/sec interfaces, all dual-port, so it actually has more network bandwidth to the NVMesh servers than it has local SATA bandwidth.
Another customer is Canada’s largest supercomputer centre, SciNet, which uses NVMesh serving as block storage underneath an IBM Spectrum Scale (GPFS) parallel file system, as both a burst buffer and for high-speed random access, Goldenhar said.


Mainstreaming Fast Flash Clusters For Fun And Profit
One of the common themes – and one could say even the main theme – of The Next Platform is that some of technologies developed by the high performance supercomputing centers (usually in conjunction with governments and academia), the hyperscalers, the big cloud builders, and a handful of big and …
Storage Is Going Have To Deal With Clouds And Edges
While on-premises datacenters are strategic to large enterprises, and will be for the foreseeable future, hybrid clouds and the edge are also an increasingly important part of the IT platform portfolio. But the road out of the datacenter and into the future with clouds and edges is not always an …

HPC In 2020: Acquisitions And Mergers As The New Normal
After a decade of vendor consolidation that saw some of the world’s biggest IT firms acquire first-class HPC providers such as SGI, Cray, and Sun Microsystems, as well as smaller players like Penguin Computing, WhamCloud, Appro, and Isilon, it is natural to wonder who is next. Or maybe, more to …
NVMEoF doesn’t require RDMA, this statement is not corret. One can use NVMe over fibre channel without RDMA. NVMEoFC is actually the best and cheapest way to transition to NVMe for companies with large FC SAN infrastructure.