

On the hardware side, the next frontier for deep learning innovation will be in getting the performance, efficiency, and accuracy needed for inference at scale.
But the newest battleground in software will be further optimization of neural networks—everything from quantization to pruning and beyond.
To date, what we have seen on the optimization end relies on algorithmic and software tweaks for existing networks. These are often taking weighty reference networks and trying to trim to size to reach the holy grail of power, performance, accuracy balance. While these compiler, quantization, and other efforts show notable speedups and efficiency gains, few things could compare to relatively simple generation of tight purpose built networks to get around all of that cutting.
One new company is showing how machine generated networks can rise above heavy code methods with the fringe benefit of being able to track how the network arrives at its conclusions on the flipside, shining light into the black box problem.
Canadian startup, Darwin AI, sees its role in the deep learning optimization ecosystem as complementary rather than competitive since there is not quite anything like what they do on the market. Formed by researchers at the University of Waterloo, the company is taking aim at companies ranging from financial services to autonomous vehicles—any vertical that is using reference networks and trying to squeeze fast, efficient inference out of trained models.
What Darwin is doing is different than with generative adversarial networks (GANs), something we expect will rise in popularity as use cases expand beyond image and video in the coming year. While there is the familiar element of generative synthesis, there is no argument from a rival network to argue about accuracy. Rather, Darwin uses machine learning techniques to probe a neural net as it is being trained to get a foundation to generate upon that delivers a specified accuracy and performance threshold. It pulls data from a training and test set and the software decides how to most efficiently implement it.
Darwin AI requires two datasets; training and test. The platform builds the new network from the training set and this runs against the test set to ensure accuracy and required performance thresholds are being met. As the company’s CEO, Sheldon Fernandez, tells The Next Platform, “In practice, a lot of people are not design neural networks from scratch. They take a popular reference network and train it for a narrow task that the original network wasn’t designed for. There are a lot of inherent inefficiencies doing things this way. We have been able to reduce network sizes over that approach by 98% or more, creating a way smaller network that infers much faster.”
As one might imagine, at least some of the efficiencies over other approaches comes via the fact that many deep learning shops use (or at least started with) a reference network (Inception V3, etc,) to build around. That comes with a lot of extraneous stuff that narrow inferencing doesn’t need. And one might also imagine Darwin is doing some kind of funky quantization or pruning. While there are some weight reductions inherent, Fernandez says these are not the keys to how it works—it is all tied in this ultra-efficient purpose-built network that makes natural connections between training data against a test set.
There is quite a bit to unpack here. The idea that their platform takes some training data and a test set and creates a machine-generated neural network of its own, especially when those generated models, while spit out in TensorFlow (with PyTorch being added within the year) don’t look much like any of the reference neural network architectures like CNNs or RNNs. Fernandez says it would take a skilled expert to work the network backwards to even see that it is actually structurally like a convolutional neural net, for instance.
Below is a chart highlighting how Darwin complements instead of competes in the deep learning optimization ecosystem.
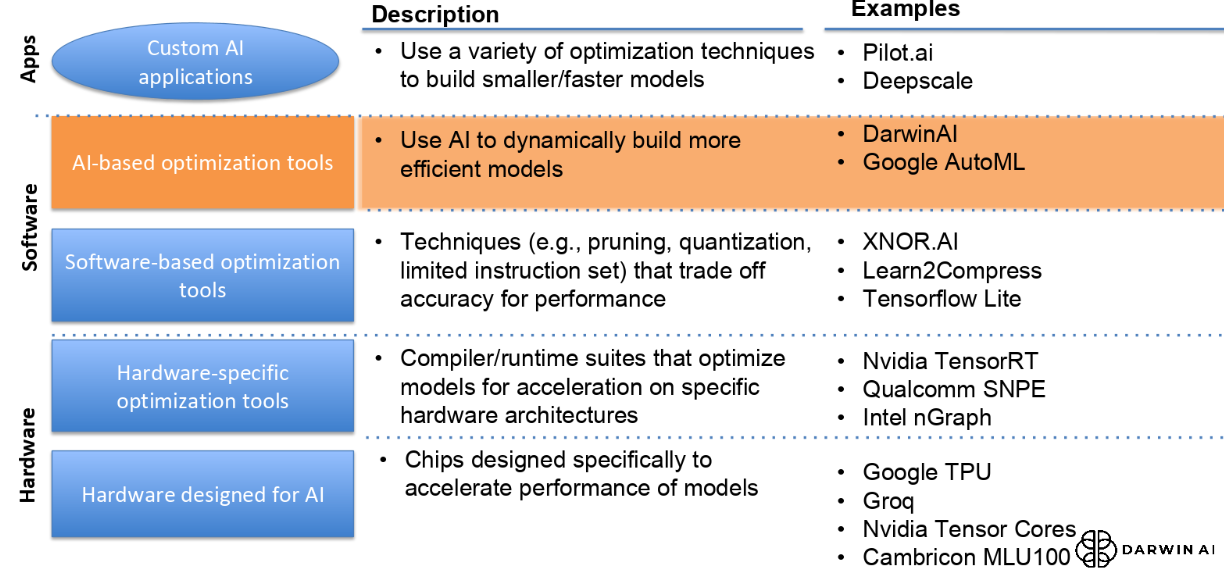
At the bottom are the hardware makers, all of whom are scrambling to line up efficient software tooling to support their training and inference chips, often with unique IP tuned to their architectures. Above them we see the growing set of toolmakers toiling away at what are essentially compilers for different deep learning stacks. Fernadez says Darwin complements their efforts are complementary since they can provide a tighter source code for the compilers to pull from and more efficient models. Above that are the many traditional software techniques; from binarization from XNOR to others that use pruning and precision weight reduction techniques to pare down networks. Google’s AutoML is different than what Darwin does because of the generative nature of the network creation and the additional explainer tooling. “We sit right below the various algorithmic approaches and above the traditional hardware and software acceleration approaches,” he adds.
In some ways, this sounds too good to be true—a machine learning platform that generates its own deep neural networks tailored just to the task or data at hand without losing accuracy (at most, they claim, it is a half-percent) while picking up efficiency and performance. Add to that a tool to tell you how it arrived at its conclusions (and thereby showing where training weaknesses exist) and it gets harder to ignore. These are still early days in terms of users and technical case has merit when we see that this is about a purpose-built model for very specific inference tasks via a generalizable platform.
If any of this functionality sounds at all familiar it is because the idea, originally coined “evolutionary synthesis” picked up some notice at the NIPS conference in both 2016 and 2017. The concept was detailed pre-startup by the co-founders of Darwin AI who detailed synaptic clustering for image classification—in essence, using a connected neuron-like approach to building networks around narrowly defined tasks or defined datasets. The natural extension of this, which is what Darwin AI is built on, is using that synaptic clustering to create an entire neural model—one that can be compiled into native TensorFlow (the original was done in Caffe and primed for GPUs for training).
All of this makes it sound black box, but in fact, the equally interesting side of what Darwin AI is doing is that they have an “explainer tool” that highlights how the trained and test data arrived at the decisions that come from inference. And this is quite noteworthy, especially in the autonomous driving space where they hope to play.
Using visualizations and data from the generated model, an autonomous driving company struggled to understand why cars turned right incorrectly. The explainer tool revealed that the training set caused the system to make a connection between the sun at a certain angle and right turns. This would have been difficult to diagnose with a standard neural network. The problem was revealed and corrected for without the expense of buying more training sets (these are enormously expensive at scale) and investing in the training hours.
“We see a lot of CNNs in autonomous driving for perception networks. They have stringent performance requirements for those—in about one hundred milliseconds a car has to decide which way to turn. Of that time, 30-40 milliseconds are devoted to inference of those perception networks. They can get that working faster these days but it takes a lot of low-level expertise to getting it running that quickly, weeks to months of optimization and perhaps even writing specific TensorFlow kernels for a specific GPU, for instance. We can approach those users, get their test data, and optimize and test a version much smaller and faster—around 8X for an autonomous truck use case while still keeping the same accuracy targets,” Fernandez explains.
The company is also targeting non-edge scenarios in security for rapid, efficient inference on video data. Financial services is another area where Fernandez says companies are looking for more capability without long development times. He points to an early use case with a UK bank for fraud detection. They had expensive, large cloud-based systems dedicated to this workload but Darwin helped them implement a neural network that was taught to look across a thousand pieces of metadata related to a transaction to find wrongdoing. They cut their cloud spend by 70-80% he says, simply by specializing a model and inference process around the custom create network. The explainer tool also helped them see key features of fraudulent transactions, revealing for instance that the Chrome browser was more commonly a flag for hacker activity.
For those that want to dig further, the “how it works” is embedded deeper in a recent paper that describes highly compact neural nets for traffic sign recognition. The project, muNet, a highly compact deep convolutional neural network based on “macroarchitecture design principles as well as microarchitecture optimization strategies. The resulting overall architecture of muNet is thus designed with as few parameters and computations as possible while maintaining recognition performance. The resulting muNet possesses a model size of just ~1MB and ~510,000 parameters (~27x fewer parameters than state-of-the-art) while still achieving a human performance level top-1 accuracy of 98.9% on the German traffic sign recognition benchmark. Furthermore, muNet requires just ∼10 million multiply-accumulate operations to perform inference. These experimental results show that highly compact, optimized deep neural network architectures can be designed for real-time traffic sign recognition that are well-suited for embedded scenarios.” The creation of the network in this case seems anything but hands free, but once running shows remarkable results.
We ask good questions about how things work here at The Next Platform and sometimes, due to companies keeping a lid on secret sauce, we can only get a fleeting glimpse into what is cooking. But this smells a lot like something that is going to find its place in the SDKs of hardware developers in the near term, along with integration inside some notable compiler and pruning packages.
The company, which has $3 million fresh in its pocket to move into enterprise and edge, is still evaluating pricing models with current thinking around an enterprise license and another variable one based on usage.

Dude this is seriously flawed approach as it relies heavily on how representative the test data set is you don’t have any clue on how well the network generalized or just memorized the test data then. Do these guys actually understand that the general reason why people take a deeper network trained on something else to a narrow task because it has likely been able to learn some kind of generalization and only needs a small specialization on top as the network as it is to deep for the small training set on that narrow task.
I respectfully dissent with “OranjeeGeneral’s” comment “Dude, this is seriously flawed…”
Respectfully, after being peer-reviewed by my global team of AI Experts and SMEs (Subject Matter Experts) what DarwinAI is doing is a paradigm shift into a bold new world that is NOT the traditional AI and neural network architecture modality.
Sorry OranjeeGeneral, you can not see the future coming. Try learning something new. Respectfully.