

FPGAs might not have carved out a niche in the deep learning training space the way some might have expected but the low power, high frequency needs of AI inference fit the curve of reprogrammable hardware quite well.
However, now that the focus on new architectures for inference versus training, FPGAs have to work to keep ahead of custom hardware for the job that rely on high level programming tools to negate some of the complexity. At this point it is still too early to tell how general purpose CPUs, GPUs, FPGAs, or custom chips will appeal to the widest base of inferencing users, but with cloud-based FPGAs at the ready now and an evolving set of high-level tools available for experimentation, FPGAs are staking a big claim in inference.
With all of this in mind, FPGA maker Xilinx has released a few details of the Xilinx Deep Neural Network Inference device, called xDNN at Hot Chips with more information and benchmarks coming the first of October at the company’s developer conference (Next Platform will be there, by the way). It is interesting to note that just a few years ago, neural network training processors were the star of the architecture show but with GPUs proving ultra-stiff competition over custom ASICs and other general purpose hardware, the battle royale is now in inference’s court.
The xDNN configurable overlay processor maps a range of neural network frameworks onto the VU9P Virtex UltraScale+ FPGA with options to beef up memory, work with custom applications, and tap into a compiler and runtime primed for this on either Amazon’s cloud with the F1 instance or in-house.
As Director of Datacenter and IP at Xilinx, Rahul Nimaiyar told us at Hot Chips last week, the FPGA inference story is based on a firm hardware foundation. FPGAs are data parallel and support data reuse as well as compression and sparsity by nature and with the xDNN processor’s 2D array of MACs, flexible on-chip memory access with high bandwidth and several ways to get to it, data movement is more efficient. xDNN also supports flexible data types (i.e., FP32/FP16 and INT 16/8/4/2, etc.).

xDNN is a configurable overlay processor, which means it gets mapped onto the FPGA without need to reprogram after. Xilinx has also provided a DNN specific instruction set (convolutions, max pool, etc.) and can work with any network or image size and can also compile and run new networks. In other words, it can work with TensorFlow without requiring reprogramming or changing the FPGA.
The Virtex hardware can be tricked out with several types of memory; from the basic distributed RAM that sits next to the DSP blocks to UltraRAM, High Bandwidth Memory, and external DDR4. This allows for optimization for efficiency or performance.
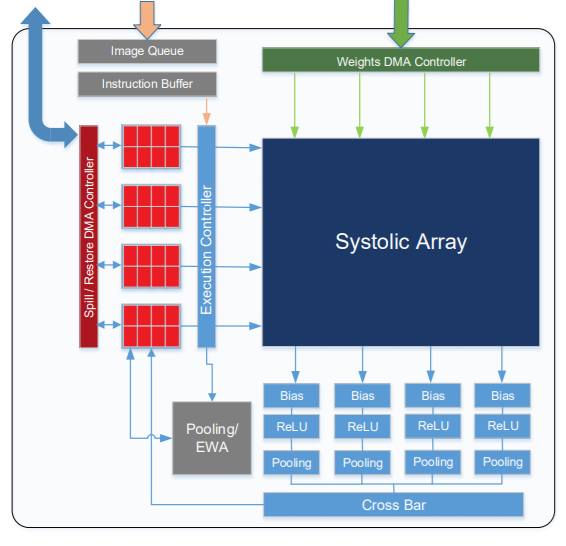
Above is a zoom of one of the channel parallel systolic arrays showing the distributed weight buffers (recall that how an architecture accesses weights are key to efficient inference). The processing elements are mapped onto the DSP blocks along with the weights, which are held in fast but low-capacity distributed RAM next to the processing. In other words, these distributed RAMs are weight caches.
xDNN’s “Tensor Memory” sits next to the systolic array and hold input and output feature maps. This is also channel parallel so each of those rows in that array are associated with a row of memory. This means xDNN can multitask, computing on the array while also bringing in a new network layer if needed, for instance.
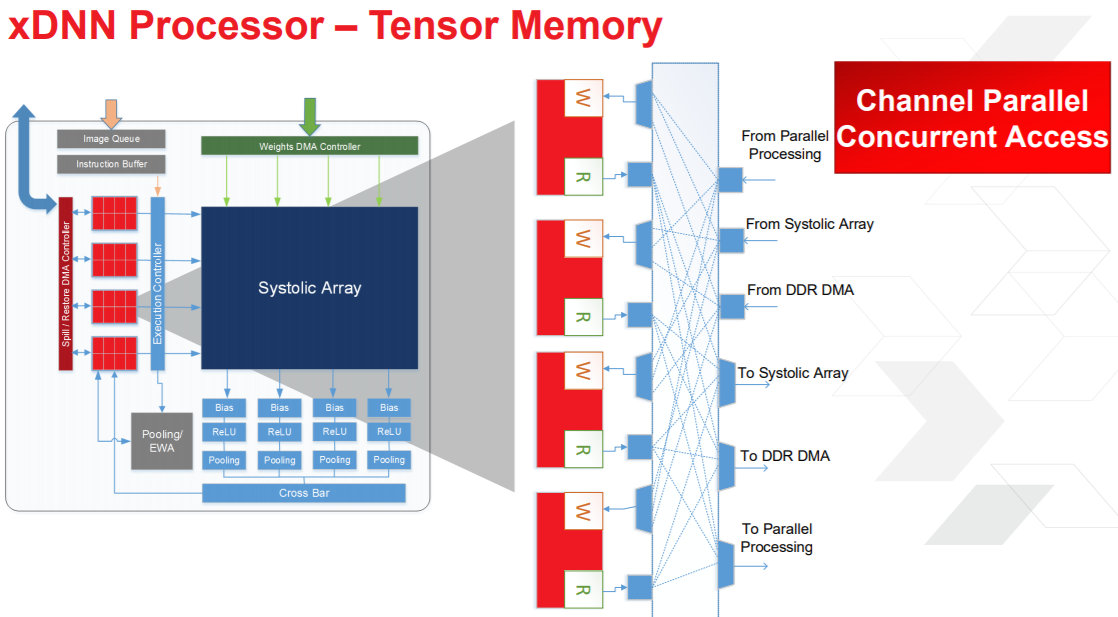
As with other inference chips, there is as much on-chip memory as can be efficiently squeezed on to keep the activations on chip—a tough balancing act for efficiency, but as benchmarks show below, the configuration Xilinx strikes appears to work.
Hardware aside, the real key from an ease of use angle, especially for those experimenting with F1 for deep learning and newer to the finer points of FPGA programming is the compiler and runtime.
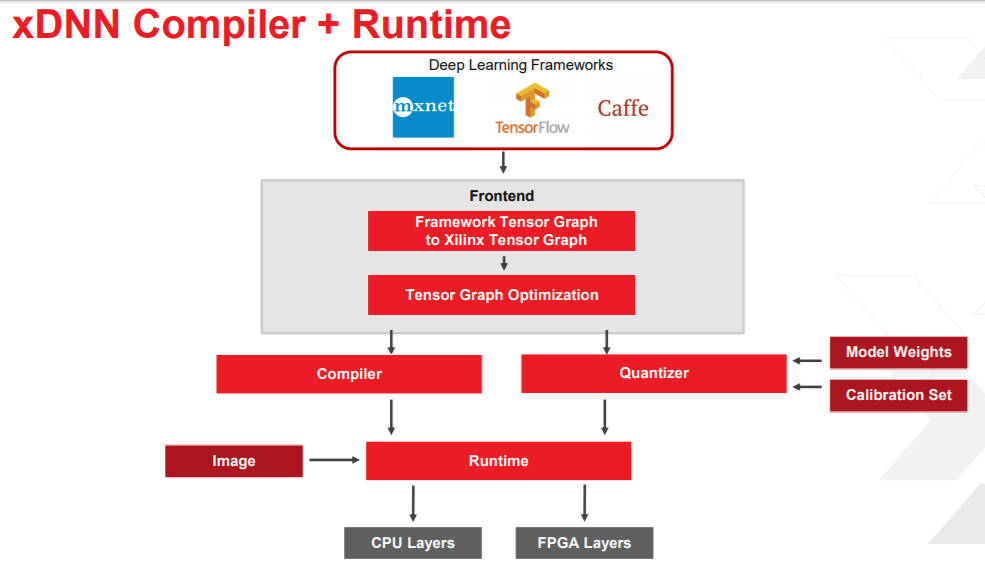
There is more info on the ML suite of tools Xilinx has developed for users, but in essence, this is an API that allows connectivity to the frameworks and makes it easier to get a trained model and weights in Tensorflow, for instance, convert that to a Xilinx graph, roll it through some optimizations before it hits the compiler, which generates all the necessary instruction sets to run that network on xDNN. Xilinx also has a quantizer so it is possible to feed trained weights to that with a few calibration sets to find the range and get quantized weights back in a hurry.
“In short, this is doing a lot of graph partitioning. There is a lot of pre- and post-processing that happens and we use subgraphs to let us run different parts of the graph on different codes or even part of the code on the host CPU,” Nimaiyar explains. He adds that Xilinx has abstracted other elements that lead to efficient inference, including fusing of operations (once activations are accessed they can be executed as pipeline operators without going back to Tensor Memory), instruction-level parallelism, and automatic intra-layer tiling for when feature map sizes exceed on-chip memory, which means xDNN can work on any feature map size.

The sparse benchmark below previews Xilinx’s own revelation of the architecture and product release happening at the Xilinx Developer Forum but so far, a 60-80% cross-framework efficiency figure is compelling enough to warrant a detailed follow up, which we will certainly do in October when we see more information about xDNN.


FPGA Inroads to Convolutional Neural Networks
At The Next FPGA Platform event in January there were several conversations about what roles reconfigurable hardware will play in the future of deep learning. While inference was definitely the target of most of what was discussed, there is ample opportunity across the spectrum for acceleration but that changes with …
Xilinx Keeps Pushing Programmable Logic As It Awaits AMD Takeover
The top brass at FPGA maker Xilinx are not hosting calls with Wall Street because of the pending $35 billion acquisition of the company by AMD, so we are left to get our own insight out of the financial report and accompanying statement that Xilinx has released for its latest …

Covering All The Compute Bases In A Heterogeneous Datacenter
Intel has spent more than three decades evolving from the dominant provider of CPUs for personal computers to the dominant supplier of processors for servers in the datacenter. While Intel has argued that Moore’s Law is not dead – that the pace of innovation with transistors and therefore semiconductors has …
21 000 GOPS / 75 watt (best case) => 280 GOPS / watt
Compate to a to an RTX 8000:
500 000 GOPS / 250 watt => 2000 GOPS /watt.
GPU:s appear way more efficient on paper (they’re essentially ASIC:s with optimized memory buses)
It’s that simple. If unsure, go GPU route. If your task is data-parallel, go GPU route. FPGAs are much more flexible in what you can implement efficiently on them, but also much more expensive both in terms of hw price and development costs.