

Getting processing closer to data is going to be one of the major themes in compute in the next decade, and we know this because for the past decade this is precisely what the big hyperscalers and cloud builders have been doing. They have already run up hard against the slowdown in Moore’s Law and they have been feverishly working to keep as much busy work off their systems and networks as possible to drive up their utilization and therefore lower their costs in a world where CPU and network capacity are increasingly precious.
As a dominant supplier of network interface cards to these makers of massive datacenters – and increasingly a company that sells switches to them as well – Mellanox Technology has a view into how the hyperscalers and cloud builders are architecting their systems for compute and storage and the networks that interconnect them. And as such, it has watched the rise of the smart network interface card, or SmartNIC, which takes the idea of offloading work from the server onto the network – something that Mellanox has pioneered and championed in the HPC space long since – to a whole new level. As a result of being the supplier to the hyperscalers, Mellanox has been able to commercialize these ideas for the rest of us.
Mellanox has been adding new capabilities to its ConnectX network adapters that have transformed them into SmartNICs while at the same time augmenting its NICs with even more intelligence through the marriage of its “BlueField” parallel Arm processors with ConnectX adapters. The upshot is that there is a lot more brains in the modern NIC – or at least some of them – than we might realize. But not all SmartNICs are created equal, and some of them should probably be called GeniusNICs and others DumbNICs. There is a lot of upselling to interface cards that have FPGAs or parallel processors embedded on them, which to be fair have their uses in the modern datacenter. But to get SmartNIC functionality does not always require such a beefy processor. In the long run, however, and for reasons that will be made clear, we think a lot of the work in virtualizing and gluing together compute and storage in the modern datacenter will be done by SmartNICs with big brains, and we know this because the hyperscalers and cloud builders have done this over their vast Clos networks that lash together a hundred thousand servers for many years already.
They have been living in the future that most datacenters have not got to yet, but undoubtedly will.
How Smart Does A NIC Have To Be?
Because of their offload capabilities, many network interface cards have plenty of brains already and so they are already technically a “smart NIC.” But Mellanox wants to draw some distinctions between NICs that have some intelligence and some that are geniuses.
You may not realize it, but the ASIC in the current ConnectX-5 adapter card, which is widely deployed by hyperscalers and cloud builders and that has given Mellanox 65 percent market share of network interface cards running at 25 Gb/sec or higher speeds, has six different processors built into it that were designed by Mellanox. They are not CPUs in the normal sense, but rather constitute a flow engine that allows the NIC to, for instance, look at fields in the incoming packets, look at the IP headers and the Layer 2 headers and look at the outer encapsulated tunnel packets for VXLAN and from that do flow identification and then finally take actions. These engines give the CoonectX-5 adapter a highly programmable data pipeline.
As such, Mellanox takes issue with other network interface card suppliers that contend that you need a beefy CPU or FPGA to do this kind of work. Mellanox disagrees and is trying to create a new category of network adapter, which it is calling a CloudNIC, that differentiates it from a full blown SmartNIC with an FPGA or CPU embedded on it for running heftier software.
“We think that many of these things people are talking about with SmartNICs you should get in a state-of-the-art CloudNIC,” Kevin Deierling, vice president of marketing at Mellanox. As a case in point, Deierling takes the example of offloading Open vSwitch, a virtual switch used to link virtual machines atop hypervisors to each other, to a network interface card. Here is the concept:
Open vSwitch was part of the software-defined networking stack pioneered by Nicira and acquired by VMware to make its NSX virtual networking stack. It provides flow lookups and load balancing across VMs and has protocol tunneling using GRE and VXLAN protocols, allows for live migration of VMs across those Clos networks, and has quality of service and traffic policing features. The only problem was that Open vSwitch was running on the CPU.
“We saw this same phenomenon with the very first generation of switches from Cisco Systems,” explains Deierling. “Cisco was doing all of the switching – and this was back at the beginning of time when the Earth was still cooling, but I remember it – on its routers and actually used MIPS processors to forward packets. Very quickly, Cisco realized that to make this efficient and to make it scalable, they needed custom ASICs, so they started making chips to forward packets. We have seen the exact same thing happening here with Open vSwitch over the past five years. It is an entirely software thing that steered the data between individual virtual machines and routed it, but the performance and scalability was so bad that companies like ourselves have actually implemented it in the NIC itself. We are doing it in our entry level ConnectX NIC, which has accelerated switching and packet processing.”
There are actually three different ways that Mellanox helps run Open vSwitch, if you want to get technical about it. First, you can run Open vSwitch unchanged in conjunction with the ConnectX-5 NICs, and that is an unaccelerated version. Second, you can use Open vSwitch over top of Data Plane Developer Kit (DPDK), which is just an efficient library running in user space so you are eliminating context switches and which gives you better performance but you are still using the CPU to do it. Or you can go all the way down to running OVS on the hardware with the eSwitch dataflow pipeline running atop of the Accelerated Switching and Packet processing (ASAP2) data flow engines. All of the software to run Open vSwitch that Mellanox is creating is being pushed upstream into the Linux kernel, so other NIC makers will be able to take advantage of it eventually.
Accelerating Open vSwitch does not mean taking place of higher level networking software. “Here is what is neat about this,” says Deierling. “We are accelerating the data plane, so when an individual packet comes in that we have never seen before, we throw it to software, and that means all of the intelligence and policy decisions are still being done in the CPU. So we are not taking away the value that VMware, Red Hat, and others are adding. The SDN controller is still the intelligent policy decision maker, and if it looks like a DDOS, they can be dropped and if it looks real, it can be sent through the load balancer. We accelerate the data plane, but the intelligence is still in the software layer. The challenge here has been to make that 100 percent software compatible, but we do that. So if you have got the accelerator in the ConnectX, you just get way better performance and efficiency.”
We are talking about pushing over 100 million packets per second with 64 byte packet sizes, all with no overhead whatsoever on the server CPU and its hypervisor.
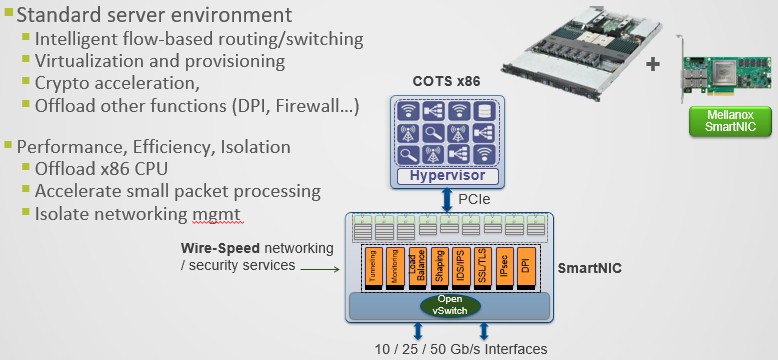
But that is only a CloudNIC, what Mellanox thinks should be the kind of functionality that something between a basic NIC, with no brains, and a SmartNIC, with lots of brains, should have. Here is how Mellanox carves up the NIC space, and as the dominant supplier of adapters, it gets to draw some of the distinctions:
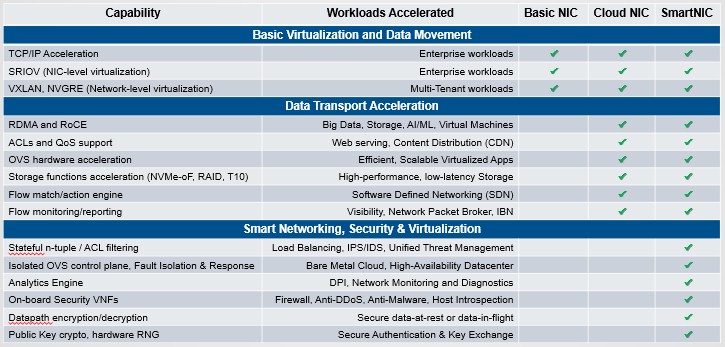
The basic NIC has acceleration for TCP/IP, SR-IOV, VXLAN, and GRE and not much else. The CloudNIC, as Mellanox is defining it, added on remote direct memory access to bypass the kernel to do memory transfers between machines as well as Open vSwitch and storage acceleration as well as flow matching and monitoring. The full-on SmartNIC, which could be implemented with a CPU or an FPGA on the adapter card, runs more complex software stacks. In the case of the Innova FPGA accelerated cards from Mellanox, they can be configured to run IPsec security protocols, and with the BlueField accelerated cards, NVM-Express over Fabrics and distributed storage software can run on the cards, just to name two examples.
What it really comes down to is weighing a specialized ASIC on network adapters against those that have been goosed by FPGAs, which has been done for more than a decade, or CPUs, which is more common these days and which is displacing FPGAs for a lot of workloads.
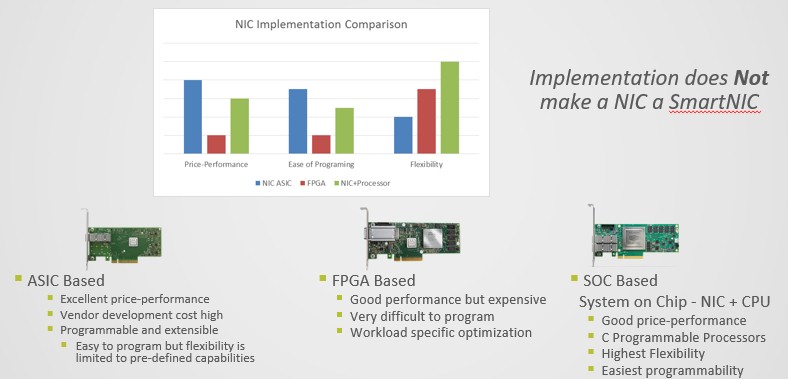
There is an interplay between performance, price, ease of programming, and flexibility that underpins the various ways to build a CloudNIC or a SmartNIC. The ASIC approach, as used with the ConnectX-5 adapters, has good price/performance and has some programmability and extensibility, but they are relatively expensive for Mellanox to develop. The FPGA-enhanced Innova cards have good performance, but FPGAs are expensive and they are difficult to program. Thus, they are really only appropriate for fixed functions that do not change much. With the adjunct CPUs like the BlueField chip, the software runs in C or C++ and is easily tweaked and changed, and by a much larger pool of programmers than is available with FPGAs. This has good price/performance – not as good as the ASIC – but a very high degree of flexibility and programmability. It is reasonable to expect for FPGAs to fall out of favor for a lot of accelerated workloads on SmartNICs and for CPUs to ascend. FPGAs are almost always a stopgap measure either down to an ASIC or up to a CPU.
Networking, Offloading And Virtualizing Like A Hyperscaler
Once true SmartNICs based on CPUs are introduced into the systems and networks – they really are a bridge between the two – all kinds of interesting things start to become possible, and they are embodied in something that Mellanox is calling the Cloud Scale Architecture.
Some applications are SAN-aware, such as Oracle databases or distributed file systems such as Hadoop. Oracle runs atop SANs with Fibre Channel switching in the storage, but now the database is being ported to Ethernet and NVM-Express over Fabrics – the combination of the NVM-Express protocol and RDMA over Converged Ethernet (RoCE) direct memory access for extreme low latency between nodes. You can do the same thing with distributed file systems. But most applications actually use local storage and are not SAN-aware. So you end up with poor utilization and you end up overprovisioning every single node. The vision with Cloud Scale Architecture is to have all of the remote storage resources in a cluster appear if they were local to each server. Just like the hyperscalers and cloud builders do under the covers in their datacenters, even if they do not expose it to customers that way.
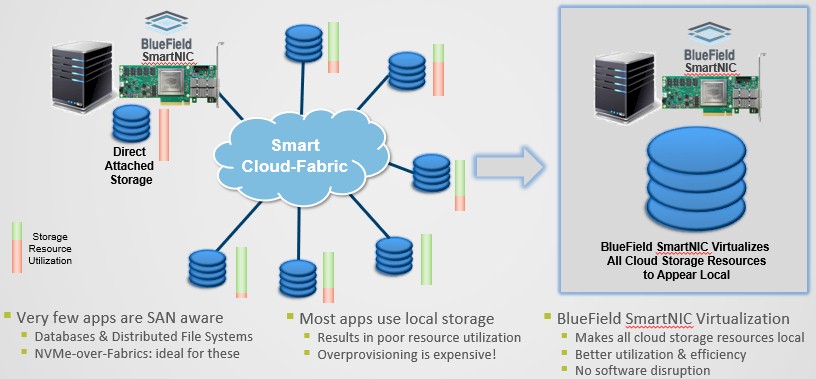
With the BlueField processors in the SmartNICs, the flash storage across the cluster can be virtualized and run across a Spectrum-based Ethernet Storage Fabric, with the BlueField processor doing that virtualization of the storage plus other functions such as compression, de-duplication, and erasure coding. It really is not that much software to accomplish this, says Deierling, but with the way that Mellanox and its partners are building it, this storage virtualization – which essentially mimics exactly what EMC does when it builds a VMAX storage appliance from a cluster of X86 servers and InfiniBand networks – will be available to everyone and not just something the hyperscalers and cloud builders keep to themselves.
Here is the fun bit, as Deierling explains: “This is going to extend beyond storage, which is the natural place to start, and virtualize other devices such as GPUs. Now you can have a server look like it has 20, 30, or 40 GPUs attached to it to do machine learning or data analytics. Ultimately, all resources in the cloud will appear as if they are local. So instead of building custom appliances, we will see servers with a single GPU in them and some flash and other devices and then have them all connected and virtualized in the cloud. Some workloads will need a lot of GPUs, and others will not, and they will be linked to workloads over the network with SmartNICs.”
The future is going to be a whole lot easier.

Defying Supply Constraints, Nvidia Turns In Its Best Quarter Ever
To one way of thinking about it, this is the best of times among the worst of times for Nvidia. Despite a global pandemic that has caused disruption in IT operations as well as spending among enterprises large and small and that has disrupted supply chains all over the IT …
Can Nvidia Be The Biggest Chip Maker In The Datacenter?
Next year, with the launch of the “Grace” Arm server processors, Nvidia will have all of the compute and networking bases it cares about in the datacenter covered, and it will be selling its technology at a rapid pace. Nvidia already has a larger datacenter business than AMD has – …

Microsoft Does The Math On Azure Datacenter Switch Failures
As supercomputer centers have long known and as hyperscalers and cloud builders eventually learned, the larger the cluster, the greater the chance that one of the many components in the system will fail at any particular time. And when you operate one of the largest public clouds on Earth, as …
Good thing is that the P4 language brings those “Ease of Programming” bars much closer to each other. Network architects can now design their networks (NICs and switches) using a common, open standard, community supported language. With that, the ability of FPGAs to adopt new, never-seen-before features suddenly transforms to hardware lifespan and thus it directly affects the price in the long run.