

At the height of the Hadoop era there were countless storage and analytics startups based on the Hadoop Distributed File System (HDFS), several of which were backed by venture capital firm Andreessen Horowitz, which was committed to the Hadoop and open source-driven big data startup cause when that was all the rage in 2010 until around 2014 or so.
Many of those big data companies with Hadoop roots were acquired, morphed from analytics to AI, or fell out of the public eye but some efforts persisted, including the UC Berkeley AMPLab Tachyon project persisted. Now productized as Alluxio the small company kept plugging away to gain a larger user base, more funding from their original investors, and a product that has managed to evolve with the times.
We talked to Alluxio back in 2016 but since then the platform has continued to evolve—and has stitched together a who’s who of extreme scale system owners, including most of the world’s top web companies.
Alibaba Cloud uses Alluxio as a fast data access layer on top of its open storage service. Baidu uses it for running SQL queries across geographically distribued databases at petabyte scale. Tencent uses Alluxio along with Spark to serve tailored news to users and China’s Uber-like DiDi uses Alluxio to tie together data from three large datacenters that feed near real-time data to the app users for route estimations and other mission-critical tasks.
As Haoyan Li, co-founder and CEO of Alluxio tells The Next Platform, the company’s data platform supports real time analytics and machine learning at scale while still catering to its initial HDFS-rooted set.
“Our architecture is based on the industry trend to separate compute and storage. With that, the data becomes siloed and bottleneck becomes the network. Alluxio is deployed in the middle of this to manage all the storage resources—DRAM, NVMe, SSD, etc—and we can intelligently move the data between compute and storage systems so that the hot data stays close to the data driven applications via policies. We also have the data locality needed to improve both read and write performance no matter what the underlying hardware.”
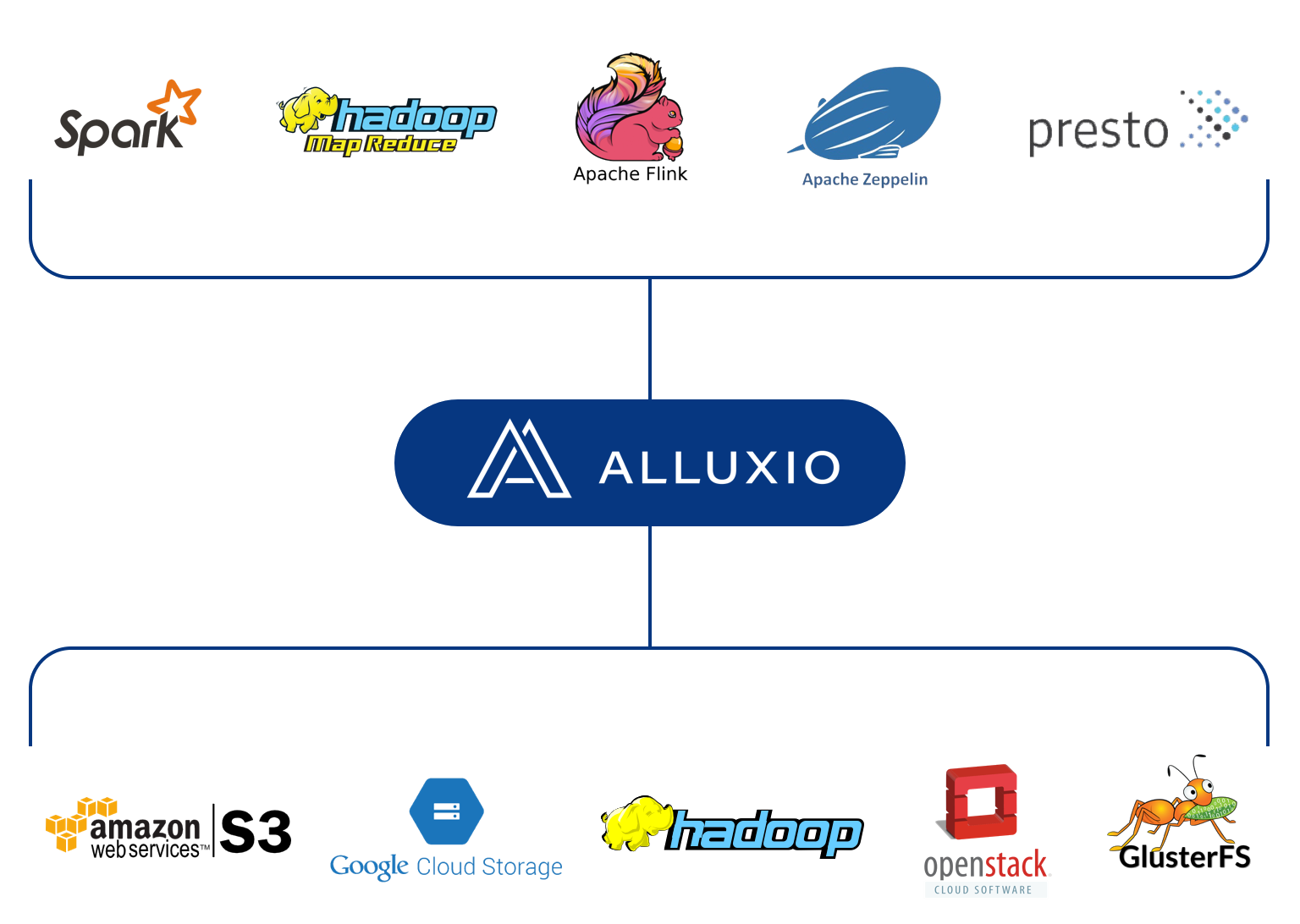
As highlighted above, Alluxio sits between the compute and storage with the ability to push and pull to and from both sets of clusters. “What we support today is far beyond what we did within the original Hadoop ecosystem from an analytical workload perspective. We still support the traditional things there but also newer data driven applications including Presto, Caffe, and TensorFlow, among others,” Li says.
We have a detailed explainer of how the platform works but Li says in essence, the messy state of siloed state has continued to get worse in the last few years. By virtualizing the data and presenting a unified API with a global namespace, users can start to dig out, even with petabyte-class problems in datacenters distributed worldwide.
Alluxio has made some key improvements to keep pace with machine learning and AI (something new since we last spoke to Li in 2016) including location-aware data management tools provide a wide range of policy-based control within hybrid cloud environments and within cloud availability zones. Optimizations for object storage, and each major cloud provider, close semantic differences with the Hadoop Distributed File System (HDFS) and ease application portability between cloud platforms. The new Filesystem in Userspace (FUSE) interface enables machine learning frameworks to access cloud data as if it were in a local file system.
The team has bolstered its appeal to developers with richer data metrics and a one-click integration check for third party applications such as Hive, MapReduce, Spark, and more. Alluxio says centralized configuration settings can be applied at the master and propagated automatically through the cluster. Different client applications, such as Spark jobs, can initialize their configuration by retrieving the default from the master. Improved journaling and snapshot provide guaranteed data consistency, faster restart, and disaster recovery support.
“Innovative companies are looking for new ways to interact with data in a complex ecosystem with a wide variety of application frameworks, heterogeneous storage systems, and hybrid cloud environments,” said Haoyuan Li, co-founder and CEO of Alluxio. “Alluxio is innovating rapidly and leveraging the open source model to give developers new capabilities to extract value from their data and build new services as enterprises navigate the digital transformation.”

Automagically Moving Legacy Hadoop To The Cloud
Always on the lookout for the kernel of a new platform, we chronicled the steady rise and sharp fall of Hadoop as the go-to open source analytics platform. In fact, we watched it morph into a relational database of sorts only to end up being cheap storage for unstructured data. …

Getting Hadoop to Jump Through AI/ML Hoops
Just a decade ago, the enterprise IT push was to make Hadoop the platform for storage and analytics. At that time, cloud hesitancy was still looming for large on-prem organizations. Hadoop, no matter how that ecosystem played out over the years, became a major source of investment with the idea …

The Endless Pursuit Of Scale At LinkedIn
There is nothing at all wrong with legacy application and system software as long as it can deliver scalability, reliability, and performance. Changing from one software stack to another is so difficult and so risky — the proverbial changing of the front two tires on the car while going down …
Be the first to comment