
It has taken time and a lot of changes in the industry, but HPC in the cloud might actually be something that can work not just technically, but as a business model that is reasonable and sustainable.
This was not the case when Joris Poort and Adam McKenzie were engineers at Boeing, designing the wing of the 787 Dreamliner aircraft. It is hard to believe, but at the time Boeing did not have enough capacity on its internal clusters to do the job fast, so over one weekend Poort and McKenzie scrounged thousands of servers from inside Boeing and did the wing design across them. With the modified wing design, Poort and McKenzie saved 150 pounds of weight from the wing, which may not sound like a lot on a plane that weighs 775,000 pounds empty. But that small weight change translated into $180 million in savings for the operators of the expected 787 Dreamliner fleet over the lifetime of the aircraft. The neat bit is that the design work to accomplish this would have taken three months on the in-house Boeing clusters, and the engineers did this in under 24 hours.
It would seem to be a no brainer, after that experience and the wide availability of on-demand compute on public clouds, that cloud HPC was going to be a disruptive business model. Boeing was not interested in starting up an HPC cloud, so in 2011 Poort and McKenzie started Rescale; eventually they moved the company from Seattle to San Francisco to be closer to the Silicon Valley set. Rescale has some pretty impressive initial backers were Richard Branson, Peter Thiel, Marc Andreessen, and Jeff Bezos, the latter of whom not only owns a large block of Amazon and therefore the Amazon Web Services but who is also an investor in SkyTap, which is a cloud native application development and testing cloud. Since then, Rescale has had two rounds of venture funding – the most recent being $32 million in early July – and has raised a total of $52.4 million, not including the seed money from those heavy hitters.
As you might expect, Rescale has done well with companies that need to do fluid mechanics, such as those in the aerospace and automotive industries, but now it is starting to expand into other markets. One upstart aerospace company that has adopted Rescale as its HPC platform is Boom, which is developing supersonic jets for business travel at a business class price. They were using a lot of wind tunnel time to do the design of the craft initially, and then they moved all of it to simulation code running on Rescale. Boom does not have on-premises hardware, and the company even does its flight simulators with the design models they create on the Rescale cloud – and airlines are buying these planes ahead of actual production based on these simulations.
The thing that separates Rescale from HPC in the cloud from the past is that it is not just compute capacity with fast networks and a modest HPC stack of MPI plus some libraries running on Linux instances. Rather, it is a platform overlay atop many different public clouds as well as on-premises gear that allows for HPC applications and their data to be deployed to the underlying resources that make sense given the time and money constraints. Rescale has ported and tuned over 250 applications to run atop of this ScaleX platform, and customers just pick them from a catalog and push them to a particular cloud and off they go. (Something that Poort and McKenzie surely wished they had back when designing the wings of the 787 Dreamliner.)
ScaleX takes input files and the applications that customers want to use and actually recommends which cloud (or clouds) to run simulations upon and what instances over what timeframe at what cost given the performance and availability of instances (with reserved, on-demand, or spot pricing). The idea is not only to eliminate on-premises capital expenses, but also to eliminate all of the guesswork about how to configure cloud capacity to run those applications. The jobs can be run on public clouds or even academic HPC facilities such as the Ohio Supercomputing Center, which is part of the ScaleX platform, and of course private on-premises HPC clusters. Rescale buys the raw cloud capacity and it provides its own service level agreements for this capacity, so there is a unified experience across this capacity, wherever it is actually located. Customers can do pay-per-use pricing for the application software in the ScaleX platform, or bring their own licenses if they have them. And, perhaps most importantly, the administrative tools allow for the setting up of users and groups and set capacity and spending limits on them to keep people from blowing the budget, and it also allows for the stitching together of complex workflows between applications for preprocessing, processing, and postprocessing work.
Of the 250 applications that are in the ScaleX catalog, about 80 percent of the time customers are running 30 of them across the Rescale base. Many of these applications are based on open source code, so this is not an issue, but not all of the applications in the HPC area have a pay-per-use license, which is an issue.
“We view this as a journey, and this HPC industry will be transformed in similar way that the record industry has undergone to become on demand,” Gabriel Broner, vice president and general manager of HPC at Rescale, tells The Next Platform. (Broner had the same title at SGI and then Hewlett Packard Enterprise after the latter bought the supercomputer maker two years ago; Broner has also ran the storage business at Microsoft, organized the engineering innovation at telecom switch maker Ericsson, and was an operating system architect at Cray.) “As more and more of these vendors offer pay per use, the others will be left behind if they do not convert. This is a destination, and we believe that the HPC industry will transform to on demand. We are at a transition point, to be honest. A few years ago, nobody offered pay per use for software, and at some point it will all switch.”
The world of cloud-only applications is still relatively small in the IT sector at large – despite how large Amazon Web Services, Microsoft Azure, Google Cloud Platform, and other public clouds have become – and it seems likely that, for the next several years at least, many companies will operate in a hybrid mode in HPC just as they are doing in IT at large. This is what Rescale thinks will happen, and we agree.
“At this point, 95 percent of HPC capacity is on premises, so what we really want to do is to enable these organizations to extend out to the cloud,” Broner explains. “And one of the things I hear all the time from people is that if they go to the cloud, they don’t want to be locked in to any particular cloud provider. But it is more than that. In some cases, HPC centers have lots of CPUs, but they don’t have GPUs. They can buy new systems with GPUs and go through that procurement, which could take many months, or they can use us to get GPUs today and only pay for the capacity they use.”
The move from on premises to cloud capacity for HPC workloads requires another shift in thought. For on premises clusters, jobs are submitted to the cluster, which has limited resources and usually more demand than supply, so the jobs have to be prioritized and queued up accordingly. You have to get in line. On public clouds, which have millions of servers and tens of millions of cores across CPUs and some GPUs, you don’t need a job scheduler is the same way. If you want 1,000 cores or 10,000 cores, you get them and the job runs as fast as the code can scale across those cores. This is a bit like heaven for HPC users. And not only can you submit your jobs at scale, you can work across the clouds and submit them to the appropriate architecture – virtualized or bare metal, new CPUs, new GPUs, or fast InfiniBand networks, skinny or fat memory, or cheap CPUs and cheap Ethernet. Whatever suits best. This is the big benefit of having a multicloud platform that includes on-premises gear, and it is hard to put a price on that kind of flexibility. But it is a big number, since it gives HPC shops agility and precision without huge capital outlay and vastly underutilized resources.
The funny bit is that as the core counts have gone up on processors, the need for sophisticated networking for certain classes of small HPC users is going down.
“We used to have a single core in a processor, and InfiniBand was very important for scale. But now we can get 56 or 64 cores in a node, and the need to go off the node is a lot less, so many customers can get by with Ethernet networking,” says Broner. “Customers like Boom are running their simulations on a public cloud using standard instances and Ethernet networking. So you can always optimize the right configuration for the job, and therefore always optimize the price/performance. When you are on-premises, you buy it and it takes ten years to get a system that is 100X more powerful at the same price. But when you use the cloud, you can always access the latest architecture.”
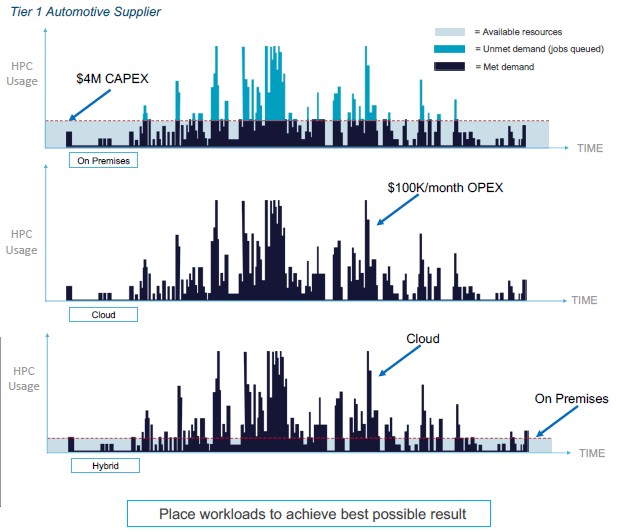
The trick to HPC in the cloud, says Broner, is to stop comparing the cost of configuring an on-premises cluster with a virtual one created in a public cloud. To put an end to that practice, let’s make it simple: The cloud is always more expensive to keep powered up 24×7 than an on-premises cluster in a like-for-like comparison. But that is not the point. HPC shops have to shift to thinking about running jobs, and how long they take and what they cost to complete in a reasonable timeframe. It is the area under the curve that matters, and a lot of on-premises clusters have idle time when they are doing nothing and peak demand that they can’t meet. These are both costs to the organization.
To balance this out requires the seamless movement of jobs between the public and private capacity, and that means hooking into popular job schedulers. (The cloud doesn’t need one, but local clusters certainly do because they do not have infinite capacity as public clouds appear to.) To that end, Rescale has integrated its ScaleX administrative console with the popular job schedulers in use out there in HPC Land, including the open source SLURM, IBM Platform LSF, Adaptive Computing Moab, and Altair PBS.
The numbers bear this out. The automotive customer above could build a $4 million cluster and not meet demand, or spend somewhere between $50,000 and $100,000 per month to go all-in on the cloud. The customer chose to use Rescale to span the clouds and ended up with an experience that felt like that had a $20 million cluster in-house designed for the peaks but for about the same money over the course of three years. If the customer had chosen to spend $2 million on a cluster and augmented with Rescale cloud capacity, our envelope math shows the hybrid approach would cost about $4.7 million, but the level of service would radically improve. There is overhead on top of this to cover Rescale and the on-site cluster administration. Rescale negotiates capacity deals with the big clouds, and the resulting price that end users see is “not that much more than what they would pay themselves,” according to Broner. Rescale overbids in the spot instance market to make sure people have capacity, but still has a better price from which it can make its own payroll.
The change in the software licensing landscape, the maturity of cloud computing, and a desire to be smarter about HPC is one reason why Rescale has hundreds of customers and its cores under management is growing at a 30 percent per month sequential rate. Success was as much about rescaling HPC for the cloud as it was rescaling the cloud for HPC. Once certain hardware started being expensive and scarce and software was available with utility prices, HPC has finally become practical on the cloud. And so, like the 787 Dreamliner that gave birth to Rescale, it is taking off.


Hypersonics Could Fuel Next Wave of HPC Investment
While the pandemic provided a funding boost to research supercomputing and life sciences HPC, the next wave of investments in HPC systems and simulation software might come from the rapidly evolving hypersonics space. We’ve had supersonic aircraft for decades but hypersonic—moving above Mach 5—is expected to explode into civil and …

The Cloud Versus HPC Cluster Cost Conundrum
The build versus buy argument for high performance computing clusters has gathered steam lately, in part because some of the critical missing pieces both performance and software ecosystem-wise are snapping into place. It has taken a number of years to get to the point where HPC in the cloud is …

Rescale’s Political Stance Boosts Cloud Based Supercomputing
If one had to make a guess about which of the big cloud infrastructure providers is sitting on eight million servers globally with a potential 1,400 petaflops of compute capacity, the list of companies is relatively short. That is, anyway, if the answer is wrapped around the notion that the …
Be the first to comment