
No matter what language or techniques are being applied, there are enough similarities between data science approaches that some broad parallels can be drawn. Independent of language and model specifics, generalizations can be teased out of data science methods to provide a reference point for the many ways to solve similar problems.
Before tackling a complex data science problem developers often check GitHub and other repositories for ideas or snippets to avoid recreating wheels. However, according to IBM researcher Ioana Baldini much can be overlooked when casting such a wide net. The key is to build an ontology of data science methodologies, tie those to real code, and connect the dots via annotations and other code information for many problem sets that are not language or model specific.
This is exactly what Baldini’s team developed, which may sound simple in theory (building an ontology of data science methods) but was actually quite complex, especially since the ontology had to automatically classify code based on relatively limited information.
The in-depth details can be found here, but in essence, the Baldini and team have developed an automatic system for gathering information from code execution (how data flows, what functions are being called, etc.) which is paired with the annotations on those functions from the code libraries. This is then matched against the ontology the team developed to establish how the code fits into different data science concepts so it is clear that no matter what language is being used, it is obvious that an approach uses clustering, for instance.
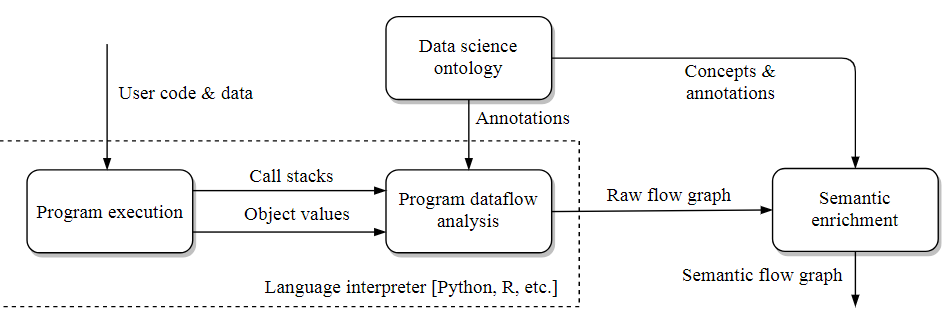
More specifically, if work is going clustering in Python it is clear to the automated system that it is doing it one way whereas R has another and problem solvers can see two ways to approach the problem clearly and automatically.
“We focus on knowledge workers who write short, semantically rich scripts, without the endless layers of abstraction found in large codebases. In data science, the code tends to be much shorter, the control flow more linear, and the underlying concepts better define than in large-scale industrial software,” Baldini explains.
“Our system is fully automated inasmuch as it expects no special input from end users. It does depend on annotations of commonly used software packages. While that requires some human effort, it is negligible compared to the usual effort of creating, maintaining, and documenting software packages.”
The IBM researchers are in the prototyping phase of the project and will eventually move this into open source status. By keeping it community driven and maintained, it is possible to keep a current ontology—something that is getting more complex with the growing number of data science problems and approaches. More details here.

Be the first to comment