

Back in the late 1970s and early 1980s, big iron in datacenters had to have water cooling, which was a pain in the neck in terms of the system and facilities engineering. And it was a big deal – and a big competitive threat – when former IBM System/360 architect Gene Amdahl – you know, the guy with the law named after him – left to start his own mainframe company and created a line of compatible mainframes that were strictly air cooled. It meant companies did not have to put in raised flooring in the datacenter to pipe water directly to the compute complexes to keep them from overheating.
Water cooling has come a long way since that time, and while air cooling of machinery has been a boon, allowing for simpler datacenters, in terms of thermal densities, we are getting back to the kind of heat buildup that forced water cooling on the datacenter to begin with. Here’s a fun comparison for you history buffs out there, who think we are only now dealing with thermal densities in the datacenter. The top end 3033-U16 mainframe, which came out in 1980, had a cycle time of 58 nanoseconds (17.25 MHz), 2.5 MIPS of performance, 64 KB of cache, and main memory that ranged from 4 MB to 8 MB, and it cost more than $75,000 a month just to lease the processor from IBM. But here’s the kicker. It burned 68 kilowatts. It was a big deal when IBM announced the 3081 later that year with twice the performance at 5 MIPS with a new processor that had a 26 nanosecond cycle time (38 MHz) and cut the power consumption to 23 kilowatts. But then IBM offered a two-way 3083 and a 4-way 3084, and the heat densities in the racks went right back up again. It took a lot of packaging and thermal engineering to do this.
Just like today. Only now we don’t have to do it the same way that IBM did almost four decades ago, but we can if we want to with derivative technologies. That, in a nutshell, is what Lenovo’s “Project Neptune” is all about. IBM was an innovator with the water-cooled supercomputers – or more precisely, returned to its roots. Clusters made of IBM’s Power6-based Power 575 servers, used at several HPC sites in the late 2000s, had direct cooling, right off the datacenter chillers, for processors and main memory. The 2.9 petaflops SuperMUC system at Leibniz Supercomputing Center in Germany used a warm water cooling system called Aquasar in its iDataplex compute nodes, and it is this experience and its follow-ons that Lenovo obtained when it bought IBM’s System x server business back in 2014.
Lenovo is working on a fourth generation, 26.7 petaflops SuperMUC-NG system, which will be stood up between now and Supercomputing 2018 in November and which will sport a next-generation water cooling system in what is expected to be a Top 10 system when its Linpack runs are done. This system will include Energy Aware Runtime (EAR) software, developed by Lenovo in conjunction with LRZ and the Barcelona Supercomputing Center in Spain, which will dynamically control the power consumption of the machine as applications are running, which Scott Tease, executive director of high performance computing at Lenovo, hints to The Next Platform could be open sourced at SC18. The upshot of the innovations that are coming with SuperMUC-NG – it has an adsorption chiller that takes waste heat and converts liquid to a gas and then back to a liquid again, creating cold water for cooling out of hot water and yes that sounds like magic – is that the cluster will burn 45 percent less energy than if it was built using conventional air-cooled servers.
Project Neptune is not about just commercializing the innovations that are coming in SuperMUC-NG, but is deploying a broad array of technologies in systems to bring the value of water cooling to them, helping companies cram more compute into the same or less space and save money on the electric bill as components are themselves getting bigger and hotter.
“We are taking a more holistic approach to cooling, and we don’t want people to think that this is only the domain of the big HPC sites,” Tease explains. “We actually believe that these water cooling technologies can be used anywhere, and they will be going mainstream in the next 18 months to 24 months as processors get hotter and we pack more stuff around them and memory and storage gets more intensive. Everything is leading to a time when we cannot use air cooling to get rid of the heat in these systems.”
As a case in point, Google’s TPU 3.0 accelerator for its TensorFlow machine learning stack is water cooled, and water cooling directly on machines is something Google has tried to avoid because of the incremental cost and hassle.
The question remains as to how pervasive water cooling will be for systems in the datacenter. Lenovo is pretty bullish about this, as are the many vendors who push such gear – CoolIT and Asetek are big ones in the HPC space – and who are watching the trends.
“Given the roadmaps that we are seeing, I think that the majority of anything that is dense, like a half-width or 1U server, is going to have to go with water cooling. It may not be the kind of water cooling where we bring in water cooling from the datacenter, like we did with mainframes back in the day or SuperMUC. We may hide it in the rack or in the system and you don’t have to plumb to it. It is getting too difficult to cool the server and too difficult to cool the room with these high performance machines without some sort of help.”
Lenovo (including that IBM System x business) is projected to sell its 20 millionth server later this fall, and has shipped a total of 24,000 liquid-cooled servers thus far. So it is a relatively small part of the historical base. But it is growing fast.
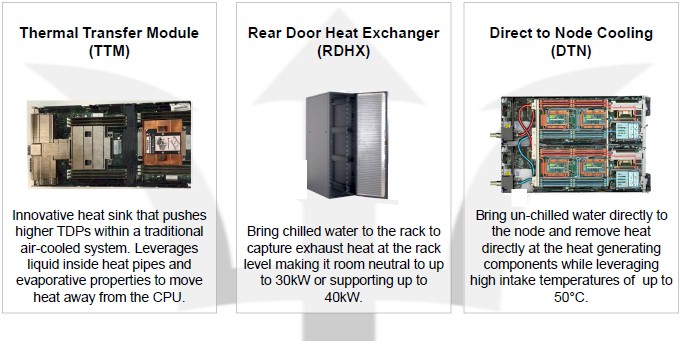
There are three different technologies that Lenovo will be peddling under Project Neptune. The first is called a thermal transfer module, and this is basically an in-chassis water cooling system that puts a heat block on processors, main memory, or accelerators to simply move it from one part of the system that is hot to another area in the chassis that is cooler and can have the heat blown away by fans and cool air brought in to replace it by traditional datacenter cooling. Rear door heat exchangers are also part of the Neptune portfolio, and these bring chilled water to the back of the rack and have a heat exchanger to take the heat out of the rack and take it away through normal datacenter chillers, and these are good to maybe up to 40 kilowatts per rack. Beyond that, you are back to direct to node cooling, where warm water of up to 50 degrees Celsius (122 degrees Fahrenheit) is brought into the servers to cool them, and then interesting things like heating buildings and sidewalks or other approaches such as the adsoption chiller make use of the waste heat that comes out even hotter.
The thermal transfer module is the easy one, says Tease, and adds something like $10 to $20 in incremental cost to a server, and it allows them to run higher bin processors (think up to 240 watts instead of 165 watts) and work their fans a lot less hard because the heat is moved to larger heat sinks elsewhere in the system that radiate the energy better. If the fans kick down a notch or two, they burn less juice and they make a lot less noise. The example shown in the chart above shows a second processor, to the left, that has water cooling feeding into a larger heat sink. Normally, you cannot put one processor directly behind another one because the second processor would be getting preheated air across its heat sink, but the thermal transfer model can move that heat off the second processor and let the airflow from the sides of the server node, which is only going over main memory, do the cooling.
Rear door heat exchangers operate somewhat like the radiator on a car. Both the radiator and the rear door heat exchange suck heat off the device – an engine block or a rack of servers – and dump it. The car radiator circulates engine coolant (usually water or antifreeze fluid) around the engine block and pulls it back to the radiator where a fan can blow across the exchanger and get the heat out from under the hood. The rear door heat exchanger sucks the heat off the servers and blows it over an exchanger that is hooked into the datacenter chillers. The rear door heat exchanger may add a few thousand bucks to the cost of a server rack, says Tease, which works out to increasing the cost of a cluster by maybe 1 percent or 2 percent, tops. This is a fair tradeoff for datacenters that have chillers and that need to increase thermal densities in their racks and also reduce their electric bills. The MareNostrum 4 system at the BSC, which we just covered, has Lenovo’s RDHX units on the racks.
The direct to node cooling has a lot of copper in the chassis and a lot of piping within and across the racks, and this adds significantly to the cost of the cluster – maybe somewhere between 5 percent and 10 percent, according to Tease. But the efficiencies, as the SuperMUC-NG supercomputer will demonstrate, more than make up for the costs.
The effect on the power usage effectiveness (PUE) of the datacenter of these technologies is significant. (PUE is the ratio of the power of the datacenter divided by the power consumed by the compute, network, and storage.) For a normal air-cooled datacenter, PUE might be somewhere between 1.5 and 2.0, but adding rear door heat exchangers, which more efficiently get rid of heat, can drop the PUE to between 1.2 to 1.4. If you go with direct to node cooling, you can get the PUE under 1.1. Google and Facebook get the PUE of their datacenters down to around 1.1 without resorting to water cooling, by the way, but they are not dealing with the same compute densities we are talking about here except for their AI and HPC iron.
All of the three prongs on the Project Neptune trident are not the same length in terms of how they are expected to be adopted in the near term. Given the stresses that systems are under, the thermal transfer modules will be employed by about 80 percent of the machines that have water cooling, and the remaining 20 percent will be split between read door heat exchangers and direct to node cooling. Tease does not expect much enthusiasm for immersion cooling, which has been employed on a number of HPC systems as well as on quite a few cryptocurrency mining systems. But over time, it may yet come to that as chips can’t shrink fast enough and start getting bigger instead of smaller like they have been for decades.


The Next Wave Of AI Is Even Bigger
Artificial intelligence is a broad area, covering diverse fields such as image recognition, natural language processing (NLP), and robotics. AI technologies are also developing at what sometimes seems like a frenetic pace, so that it can be difficult to keep up to speed with everything that is happening. Unsurprisingly, many …
Dell, Lenovo Also Waiting For Their AI Server Waves
If the original equipment manufacturers of the world had software massive software divisions – like many of them tried to do a two decades ago as they tried to emulate IBM and then changed their minds a decade ago when they sold off their software and services businesses and pared …

Dallara Races To The Future Of HPC
When talking about auto racing, everything eventually boils down to speed. While front-of-mind that means how fast a car travels around a track or through a course, speed is becoming increasing essential throughout all areas of the racing environment, including the development, design, testing and production of the cars themselves. …
Lot of marginal assertions in there, tilted to make the exotic stuff look good…
Really, most of it boils down to “systems are becoming denser”. For instance, memory power is actually decreasing, as is power-per-performance of CPUs. But yeah, for more cores, you probably want more dimms and if you can stuff more into a rack, heat density increases substantially. Same for more IOPS or TB or GPU flops. Each component is getting dramatically more power-efficient.