
If everything had played out as planned, then the original “Aurora” supercomputer planned by Intel and built by Cray for Argonne National Laboratory under contract from the US Department of Energy would probably have been at or near the top of the Top 500 charts this week at the International Supercomputing 2018 conference in Frankfurt, Germany. The processor in this planned machine appears to have gone the way of all flesh, but the interconnect is still being developed and is due next year.
That original Aurora machine, unveiled in April 2015, was to be based on the fourth generation of Intel’s manycore Xeon Phi processors, code-named “Knights Hill,” with over 50,000 nodes in a cluster and performance ranging from 180 petaflops to 450 petaflops of double precision performance. The system was also to employ the second generation of Intel’s Omni-Path interconnect, known as the OPA 200 series, and as the kicker to the Omni-Path 100 series that wan at 100 Gb/sec, it was no stretch of the imagination to reckon that the next speed bump for Omni-Path was going to be 200 Gb/sec to be competitive with the Quantum InfiniBand ASICs and switches from rival Mellanox Technologies. There was an outside chance that 200 Gb/sec InfiniBand would be ready for the “Summit” and “Sierra” supercomputers built for the DOE for Oak Ridge National Laboratory and Lawrence Livermore National Laboratory, respectively, if the compute nodes could be ready by the summer of last year. But that didn’t happen, and so Mellanox, knowing it was under no pressure from Intel because Omni-Path 200 was delayed because Aurora was not coming to market as planned.
As we all know now, Argonne will be getting the first exascale system in the United States with the follow-on “Aurora A21” system, which will be delivered in 2021 using an as-yet unknown processor and interconnect, which we pondered based on some hints about its architecture that Argonne put out for people trying to get their applications onto the boxes when it first becomes available. We don’t understand exactly why Intel is being so cagey about the Aurora A21 architecture, and it might have more to do with it being not precisely settled than anything else. Hopefully talks by Al Gara, their chief exascale architect at Intel, at ISC will shed some light on the subject – as they usually do despite the best efforts of the PR handlers.
What we knew from the initial discussions Gara had on the Aurora machine three years ago was that it would have 7 PB of on-package, high bandwidth memory with an aggregate of more than 30 PB/sec of bandwidth across the more than 50,000 nodes in the system. Intel was going to put the Omni-Path 200 ports on the Knights Hill chip package, much as it did with Omni-Path 100 links on selected models of the “Knights Landing” Xeon Phi and “Skylake” Xeon SP processors. The Omni-Path 2 network for that original Aurora machine was being designed to deliver 2.5 PB/sec of aggregate node link bandwidth and more than 500 TB/sec of interconnect bisection bandwidth.
With ISC18 underway, Intel has decided to lift the curtain a little bit on Omni-Path 200, and Joe Yaworski, director of product marketing for high performance fabrics and networking at Intel, confirmed with The Next Platform that the next gen Intel interconnect would indeed be available at 200 Gb/sec speeds. (Well, yes.) But he also talked about a few other things about Omni-Path 200, which will be coming to market well before the Aurora A21 machine, which we think will have to be running at 400 Gb/sec or even 800 Gb/sec to be competitive with InfiniBand and Ethernet at the time in terms of raw bandwidth. (InfiniBand and Omni-Path both have a severe bandwidth advantage, with port to port hops well under 100 nanoseconds, compared to 350 nanoseconds to 450 nanoseconds for the typical Ethernet switch that is not a slow poke. The fastest Ethernet switches can maybe do 200 nanoseconds, like the Cisco Nexus 3500 operating in “warp” mode with some restrictions on how the data moves; it does 250 nanoseconds usually on a port to port hop.
A lot has changed since Intel bought the True Scale InfiniBand business from QLogic, which was the remaining competition to Mellanox, back in January 2012 for $125 million. The QLogic InfiniBand business was a good fit for Intel because the True Scale InfiniBand was created so a pair of 40 Gb/sec adapters could each be pinned to one processor in a two socket system and thereby keep traffic off the QuickPath Interconnect (QPI) bus that links those sockets together, adding latency. This was akin to getting 80 Gb/sec of networking into the server (albeit with two adapters instead of one) at a time when Mellanox was peddling 56 Gb/sec FDR InfiniBand that also spoke Ethernet protocols, but which actually had worse latency than the prior generation of 40 Gb/sec QDR InfiniBand. (We did an analysis of the adapter and switch latencies for Mellanox InfiniBand back in April 2015, and more recently talked about the relentless pace of InfiniBand bandwidth increases that the trade group that controls the InfiniBand spec has planned. Mellanox had 36 port switches during the EDR 100 Gb/sec generation, and with the Quantum HDR ASICs that provide 200 Gb/sec per port, it is increasing the radix, as they say in the switching racket, to 40 ports per device. The higher the radix, the lower the number of switches needed to cross-couple a set number of server nodes.
The True Scale switch ASICs from QLogic had 36 ports, and could push 42 million packets per second, had a host fabric interface (HFI) message rate of 35 million messages per second, and a switch latency that ranged from 165 nanoseconds to 175 nanoseconds. With Omni-Path 100, the lanes on the chip were boosted from 10 Gb/sec to 25 Gb/sec, thus boosting the port speed to 100 Gb/sec, but more importantly, the switch port count jumped by 50 percent to 48 ports while at the same time the HFI message rate was increased by a factor of 4.6X to 160 million messages per second, the switch packet rate went up by 4.6X to 195 million packets per second, while the port-to-port latency dropped by around 40 percent to somewhere between 100 nanosecond and 110 nanoseconds.
Just for reference, here are the Omni-Path 100 products that were announced:
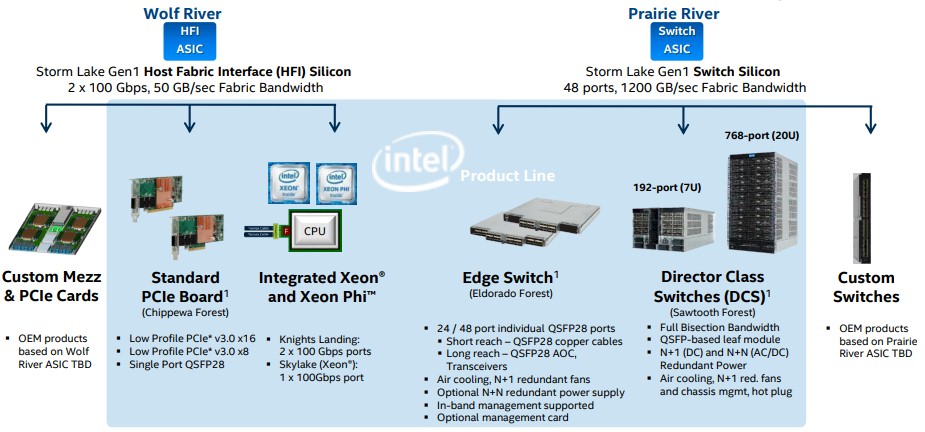
We did a deep dive on the Omni-Path 100 switches and adapters back in November 2015 when they first debuted, just to level set. Here was the basic argument comparing EDR InfiniBand to Omni-Path 100, which shows the effect of a higher radix switch:
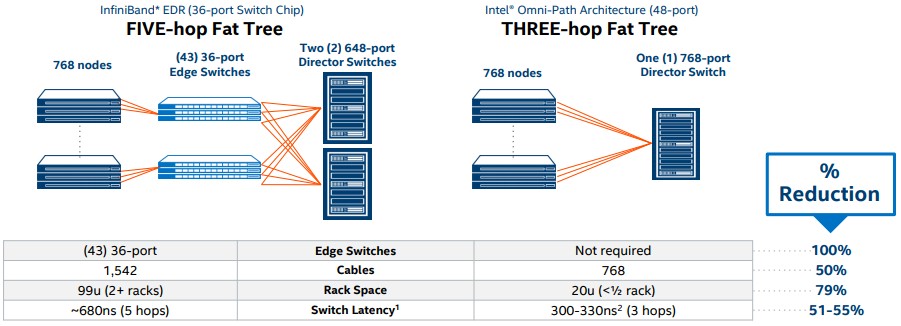
This is obviously a case tailor made to show the Intel advantage, but even if you have a leaf/spine configuration comprised of fixed port switches instead of director switches, the higher radix means fewer devices. If you only wanted to link 648 servers, you could just buy a single InfiniBand EDR switch from Mellanox and that would just be a game of who has the lower cost port between Intel and Mellanox. It always comes down to cases with networks, and you always have to do the math for those cases.
Suffice it to say, though, these Omni-Path products represented very big improvements on many fronts compared to the True Scale stuff, and with Omni-Path 200 Intel has some other big ones on the way – and changes that reflect the altered nature of what is called HPC these days.
“If you go back five years ago, it was all about HPC,” Yaworski explains. “Now it is about HPC and artificial intelligence, and as you move into the AI arena, things like message rate and bandwidth and collectives performance become very key. We have what we believe is a very good product today, but we have made some very significant improvements that will benefit HPC but also machine learning – especially training across multiple nodes at the reasonably large scale of hundreds to thousands of nodes. We also see an evolving programming model, with maybe 98 percent or 99 percent of HPC applications written around MPI. As we go forward and the size of clusters increases and the number of cores on the cluster goes up dramatically, particularly for exascale, the one-sided communications paradigm will become more important.”
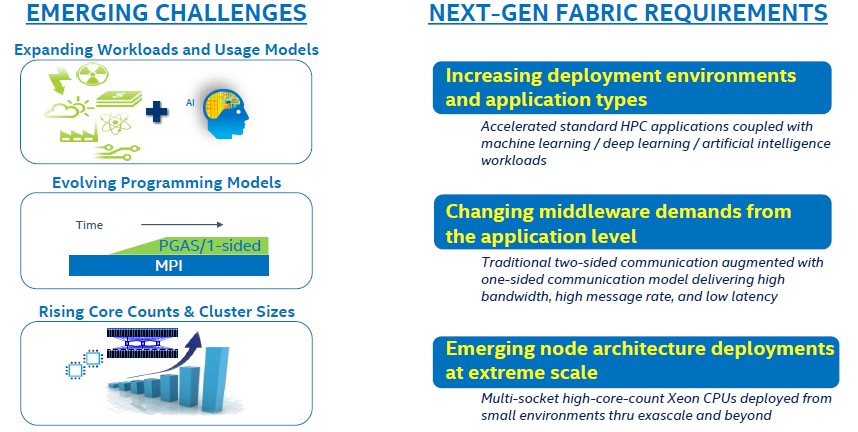
The interesting thing in the chart above is that it says “multi-socket high core count Xeon CPUs” with no mention of the Xeon Phi many core processor. (Hmmm.)
The first thing that will improve aside from the doubling of the bandwidth will be the higher radix switch – meaning it will have more ports per ASIC. The trick here is how much wiring you can cram around the crossbar on the ASIC, given the chip implementation process and its thermals when the transistors are etched and the speed at which the SerDes on the ASIC need to run and how many you can cram on there. Yaworski is not about to give out the details, but it is logical to try to get to 56 ports or maybe even 64 ports in the jump from Omni-Path 100 to Omni-Path 200. Our guess is that another 33 percent on the port count to 64 ports is possible; a 17 percent jump to 56 ports just does not seem all that impressive, and does not get Intel to exascale without the network consuming to much money in a cluster. (40 percent of the budget is not acceptable, and even 25 percent is pushing it, we think.) What we can tell you is that with the Omni-Path 200, Intel is going to make use of “a novel implementation” of crossbar wiring that Intel acquired when it bought the “Gemini” and “Aries” interconnects from the supercomputer maker back in April 2012. (Yes, that was more than six years ago.)
In terms of messaging rates, we poked and said that there was no way that Intel could boost it a full order of magnitude – the last jump was half that – and Yaworski said this: “We are not going to be able to get a full order of magnitude, but we are going to be close.” So there you have it. As for latency, don’t expect a big jump down on the port to port hops – anything below 100 nanoseconds is hard to come by – but the focus Intel will have with Omni-Path 200 is to have consistently low latency even as machines scale up. Intel is particularly concerned with the latency of collective operations running on clusters, and may be embedding them on the ASICs as Mellanox has been doing. The goal is to get machines with 250,000 or more cores – exascale machines will possibly have tens of millions of cores – to provide consistent and low latency on such operations. To ensure this, the Omni-Path 200 will have finer-grained quality of service (QoS) controls, with multiple layers and pre-emption to make sure the network doesn’t get jittery for the highest priority applications.
As for absolute scale, the largest Omni-Path 100 networks have around 8,000 nodes in them, according to Yaworski, and the architecture was qualified to handle up to 16,000 nodes. Omni-Path 200 is designed to go to tens of thousands of nodes – the original Aurora system would have had more than 50,000 nodes this year – and to hit exascale performance levels. We have a hard time believing that 200 Gb/sec will be enough bandwidth in a world where Ethernet providers are building 400 Gb/sec devices and looking ahead to 800 Gb/sec and faster switch ports.
“We believe that we will have an extensible architecture for switches that we can carry forward,” says Yaworski.
Intel’s plan is to start deliveries of Omni-Path 200 devices to key partners in early 2019, and then roll it out to key customers shortly after that. As for pricing, Yaworski says that for Omni-Path 100, Intel wanted to deliver a port running at 100 Gb/sec for the same price as Mellanox was charging for 56 Gb/sec FDR InfiniBand ports. When pushed about where the 100 Gb/sec ports are in terms of price these days, Yaworski says that in typical deals, depending on the size of the cluster, customers pay on the order of $1,000 to $1,500 per port. The average Ethernet port running at 100 Gb/sec in the first quarter, across all switch radix sizes and latencies, was $516 as we reported earlier this month. The difference is the latency, which is about one fifth of that on an Ethernet switch. We don’t know yet how far Mellanox and Intel will push down the prices with the 200 Gb/sec generations of their respective InfiniBand and Omni-Path interconnects.


Datacenter And Xilinx Power Through In Q4 And Beyond For AMD
Imagine, if you will, how troublesome AMD’s chip business would be at the end of 2022 had it not decided way back in 2015 to re-enter the datacenter with its Epyc processors. And imagine further how 2022 might have turned out – and how 2023 might be – if it …
Intel Fields A 10 Nanometer Server Chip That Competes
At long last, Intel is finally shipping a Xeon SP processor that is based on a 10 nanometer chip manufacturing process and it is finally able to do a better job competing on the technical and economic merits of its Xeon SP processors as architected rather than playing the total …

For CPU Makers and OEMs Alike, It’s A Platform View
Dell took a look at the two weeks between the rollouts by AMD and Intel of their latest server processors and, after some debate, decided to unveil its entire portfolio of new and enhanced systems – featuring the new chips from both vendors – at the launch of AMD’s latest …
Be the first to comment