

We have talked at length about the complexity of software and systems in HPC, and many in the community agree that HPC and AI is hard work. Wouldn’t it be nice to have a simple one-click “add to basket” option for HPC software and services? Many have tried, with each iteration becoming slightly more seamless than the last. Large ISV software packages add cost and complexity to an already cluttered landscape full of options and systems. The now ubiquitous “app store” culture on mobile devices have left many confused as to why there isn’t such a thing in technical computing.
AWS came out with its Marketplace over six years ago in 2012, “an online store where customers can find, buy, and quickly deploy software that runs on AWS.” Problem solved. Not quite, turns out that HPC software took a little longer to become more fully baked into these marketplace ecosystems, however now searching the AWS offerings pops up over 253 packages tagged as “HPC” with everything from bundled TensorFlow to FPGA development kits to integrated GridEngine job schedulers and so on. There is now at least the potential for having “an app for that.” However, what if you need something a little more specialized, dedicated hardware low latency interconnects, or a more boutique, one on one conversation with your HPC cloud provider? Who do you call?
To fill that gap, Nimbix has been working to provide boutique HPC applications just a few years before the AWS marketplace starting back in 2010. Attracting a further $7.5 million in a Series B round in 2015 to expand a 3 megawatt datacenter with a bare metal as a service HPC offering, Nimbix was also early to market with dedicated hosted GPU and FPGA accelerators and Power8 systems over the years as it built out the partnership network. The drop down box alone for available HPC hardware represents a proverbial candy shop of acronym choices and selections not often seen outside of academic computing departments:

To support this exotic and eclectic hardware stack, JARVICE, the Nimbix software management and orchestration engine, has also been through a number of iterations. Recently Nimbix announced that it had now reached version 3.0, as they continue to push their end-to-end software and hardware integration agenda. JARVICE 3.0 is touted as a deep incorporation of Kubernetes container technology. In this specific incantation, JARVICE Services – their pre-built workflows – have also been expanded with additional APIs and Nimbix has broken JARVICE 3.0 away and is selling it as a standalone software product that can now orchestrate via the Kubernetes container controller both on premises gear and its own hosted platform. Looking at the solution stack, it is clear that software development has been consistent and continues to escalate as Nimbix tries to provide systems that are hard to find at other HPC cloud providers. Nimbix is attempting to scale the boutique through clever software. It is not easy.
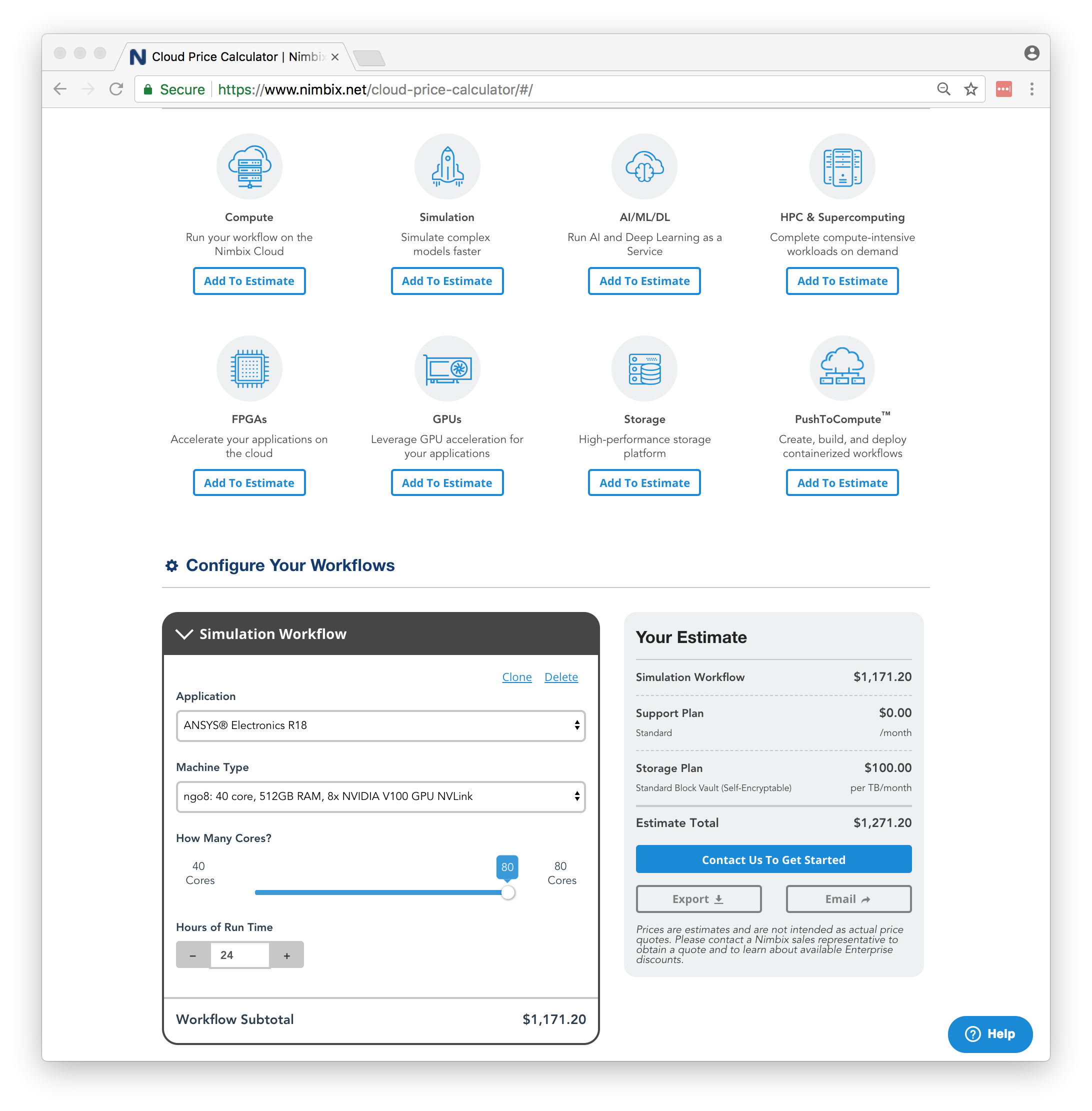 As an example of the hardware boutique, a system with eight “Volta” V100 accelerators linked by NVLink interconnects with 80 X86 cores and half a terabyte of DRAM on the host can be pre-configured with ANSYS software right from under a single “add to basket” interface. This is an extremely comfortable way to consume HPC software. However, you probably would not want to leave it in your basket for all that long, because at $1,171.20 a day that would all quickly add up, and eventually land you with a $427,488 bill at the end of the year. Which is quite a lot for a server, albeit a really nicely configured one.
As an example of the hardware boutique, a system with eight “Volta” V100 accelerators linked by NVLink interconnects with 80 X86 cores and half a terabyte of DRAM on the host can be pre-configured with ANSYS software right from under a single “add to basket” interface. This is an extremely comfortable way to consume HPC software. However, you probably would not want to leave it in your basket for all that long, because at $1,171.20 a day that would all quickly add up, and eventually land you with a $427,488 bill at the end of the year. Which is quite a lot for a server, albeit a really nicely configured one.
This has always been the challenge of cloud HPC: You have to know when and how to use the systems. The analogy of renting a car versus an outright purchase is key here. If your use case permits and you don’t need a vehicle every single day, hourly rentals are significantly less expensive than buying out an entire vehicle. However, you would never want to rent an entire vehicle for a whole year based on hourly rates. Basically, it is all about how to be able to get in to the cloud, do your work and get out, quickly closing off the instance. Cycle Computing, acquired last year by Microsoft, would for example exploit the AWS spot market to achieve phenomenal stunts of computing by allocating hundreds of thousands of CPU cores for a super-short period of time to then rapidly carry out vast numbers of molecular dynamics calculations and return you a bill for only a few thousand dollars. Now that Cycle is part of the massive Azure public cloud landscape that particular parlor trick now has the potential to have all sorts of interesting levels of resulting economy of scales.
In light of the Microsoft acquisition of Cycle, and recently Penguin Computing – which has been a long time HPC provider for both on-premises and cloud bare metal HPC – being picked up for $85 million by Smart Global Holdings, as well as more sophisticated boutique providers such as Joyent – founded way back in 2004, raising over $131 million, and eventually being snapped up in 2016 by Samsung – we pondered the path forward for Nimbix. To find out more, we asked co-founder and chief executive officer Steve Hebert what the Nimbix exit strategy looked like. Hebert was keen to point out that Nimbix was continuing to build the business and growing while also adding a classic “never say never” traditional C-level response about being bought or going public. Nimbix has also been keen to continue to build and defend its HPC cloud technology stack directly with recent patents covering both “dynamic creation and execution of containerized applications in cloud computing” and “reconfigurable cloud computing.”
Nimbix was also early to support containers before many others, and Hebert explained that Nimbix needed to use container technology very early on to even be able to exploit InfiniBand networking and other more dedicated HPC hardware. They do something different than other HPC container systems we have discussed in the past, in that the Nimbix stack is not multi-user like traditional supercomputing centers, that directly impacts their security posture in a good way due to the obvious isolation. One container per tenanted system. It is also clear there have been many developments in the cloud HPC space have taken place since we last spoke to Nimbix in 2016, when it was first eyeing up how to play in the now ubiquitous AI marketplace.
The Next Platform also asked Leo Reiter, chief technology officer at Nimbix, exactly how all of this works. “From an evolution perspective, we now have five years of increasingly complex deployments of real-world containerized workloads,” Reiter explained. “We did HPC in the cloud before people really understood it.” This subtle jump on the market has enabled them time to spend on continual development of the Nimbix software stack. The dedicated hardware that runs containers on bare metal instead of virtual machines, which Nimbix is keen to point out eliminates the “hypervisor tax” associated with other public clouds and data center infrastructures. Other players in this space feel very similar about this tax, and we have covered bare metal application providers in the past and consider them to be part of the missing middle for cloud based HPC.
Reiter continued to explain that they take a “one customer at a time” approach to onboarding. They clearly operate at the high end, much more boutique space of HPC and cloud. Each engagement with their customers and domain experts results in another packaged software appliance that can then be integrated into the overall JARVICE offering. Now on version 3.0 and also being able to use that console as a bridge between other local computing platforms ought in theory, be able to add even further flexibility for their consumers of more complex integrated HPC apps.
From an economy of scale perspective what Nimbix is doing here is rather smart. It leverages relationships with the ISVs and customers to then be able to meet in the middle and then reuse software that was configured for a specific purpose. As more new customers arrive, there is an ever more likely chance that their problem has been cast before, so lather, rinse, repeat can be employed to reproduce that package in an existing environment.
With HPC center staff being ever more conflicted and pulled in directions to install and manage a vast array of software packages, having a system where it is already there and proven is extremely compelling. What Nimbix calls its App Marketplace has all the high-end software you would find at any leading HPC center all in a box and it is ready to go. Nimbix also states: “New applications are added all the time and many other cloud applications can be integrated with the Nimbix Cloud, just ask.” This “just ask” approach further reflects a more direct interaction with their customer base that is hard or impossible to find at other large public cloud providers.
One question we asked was focused on specific metrics for what it really costs for Nimbix to provide this integrated software and hardware stack and then be able to present such a platform to their customers. We wanted to understand what it really saves you on your run time, employee, and compute costs. There’s more to it than just the standard cloud play economics here. There is the potential to leverage significant people investments and experience gains that a boutique hardware and software provider such as Nimbix can bring to the table as a fully integrated cost per flops. Especially once all the integration is calculated and included as savings to be passed on to their customers.
Unfortunately, Hebert could not quite put his fingers on the exact answer. Hebert is not alone here, those intangible and yet important costs are extremely hard to understand and quantify fully. Any advanced service provider – be it a large national project such as XSEDE or a local academic HPC center – will always struggle to explain its specific net present value in terms of hard, cold cash. The conversation inevitably always turns to the inherent value of the integration of the offering and how it enriches research activities rather than one of pure finances, which is also a good answer.
It’s not always about the money, but the time to result, and the quality of the environment that is provided to the ever more burdened research and data scientist. As a company providing consumable HPC services, especially with the number of software permutations and options on the table, Nimbix will have to at some point understand its scaling function. Both from an economy of scale, and also to watch that their smaller datacenter costs are not consumed by the massive purchasing power and brute force of the global hyperscalers. Boutique simply doesn’t scale, but from where we sit, Nimbix is currently making good choices with software integration and package reuse in an attempt to avoid the inevitable “mythical man month” issues that comes with large vertical and horizontal scaling.


On The Spearpoint Of FPGA And The Cloud
Sometimes markets need a particular technology and they are impatient for it, and sometimes technologies get ahead of the immediate needs of customers and their creators have to hang on until the time is right. So it is with FPGAs in the cloud, which is actually the confluence of two …

Time in the Sun Coming for Cloud FPGAs
Keeping an eye on how the largest cloud providers choose to invest in hardware is always interesting but it does not often shed much light on how emerging workloads are driving new investments. As an Amazon, Google, Microsoft, or other cloud, bringing the best in breed processor is simply a …

Pulling All the Levers For HPC In The Cloud
The acquisitions last year of Nimbix, Visual BI, and Ideal GRP by Atos signaled a more aggressive push by the European HPC vendor into the cloud and tech services space and coincided with a plan to expand beyond its legacy business and into such new growth areas. The pickup of …
Be the first to comment