
It is probably a myth that Bill Gates said “640 KB ought to be enough,” and whether or not he said it the truth is that it has never been enough. Ever since we first started building computers, no amount of memory has ever has been enough – and it never will be. Data is a gas, and it rapidly expands to fill any and all available space and then continues to apply direct and significant pressure to the walls of the container.
Granted, a lot of that gas is hot air. But that is another matter.
When you run out of memory you face two simple options. The first is for the application to fail, and fail hard because of the increased pressure. The other is to try to bail out any memory pages that you think you don’t currently need. It is basically the same as an overwhelmed bilge pump inside a rapidly sinking boat. Paging is rarely a good solution, but can maybe, if you are lucky, stop you from physically sinking. System paging has been with us for decades, and is first attributed to the Atlas system installed back in 1962 at the University of Manchester. Atlas then used four sets of physical magnetic drum storage that could be effectively used as a “virtual memory” store to page out up to 576 KB from the then slightly underwhelming 96 KB of active magnetic core system memory.
Today, many euphemisms are used for a system under active paging, from “the swap of death” to “thrashing” – no matter what the name, the direct and miserably deleterious effect on system performance is clear. Machines are not happy when they are under paging load, and neither are any of the users. Careful systems level programing has always been needed to “avoid the page,” and like our boating analogy we need to make sure that we manage any leaks intended or unintended throughout the voyage with care, before we find ourselves in an untenable situation that we can no longer bail ourselves out of.
In the early days of attempting to annotate the Human Genome, there was a lot of Perl. Probably too much Perl, but it was what was available, and it was good at munching on data. There was also too much data, way too much data for the mostly 32-bit machines and their 2 GB of memory that were readily available and even too much for the handful of 64-bit machines that budgets couldn’t allow to be outfitted with anything much past 4 GB of DRAM anyway. You could have the addressability of the bits, but you couldn’t afford the actual bits.
Tie-Dyed Files
Now considered a classic Perl anti-pattern, Tie::File was a simple hack to read entire files as if they were actually arrays, and once they were cast as “arrays” you could effectively program directly in code against them. Make indexes to them in real memory, read bits and pieces, and so forth. As an example, take this code that renders random jokes from a file full of jokes as an array of one line @jokes – the actual joke file was huge and never actually went into memory. We will intentionally leave any and all other potential Perl jokes as an exercise to the reader:
 You can also imagine the horror that happens to the physical memory and file system buffer caches that were underneath all of this – it wasn’t at all in anyway performant, but it was slightly more elegant than paging, and could get the job done in a hurry which during the time of pressure to deliver results quickly as huge chunks of human genome data piled up each day was a significantly better design goal.
You can also imagine the horror that happens to the physical memory and file system buffer caches that were underneath all of this – it wasn’t at all in anyway performant, but it was slightly more elegant than paging, and could get the job done in a hurry which during the time of pressure to deliver results quickly as huge chunks of human genome data piled up each day was a significantly better design goal.
So enough history. We think we have each proven that it has always been the case that the really big things you want never quite fit inside the box that you can afford. We have all been constantly looking to new ways to cheat our systems to make bigger, more expensive things fit inside our smaller cheaper things. It turns out, even after all this time disk based hash tables are actually still somewhat in vogue, recent examples are increasingly more sophisticated than the earlier Tie::File example. However, each do also have a similar use case and workload. Expensive commercial in-memory databases are just a way to buy an expensive box so that you can put your expensive big thing inside – not everyone can afford an expensive box, and sometimes the size of the physical box you actually need hasn’t even been invented yet.
Faced with a similar challenge, Luis Pedro Coelho, who is a computational biologist at the European Molecular Biology Laboratory, said of its ANN disk hash software: ”My usage is mostly to build the hashtable once and then reuse it many times. Several design choices reflect this bias and so does performance. Building the hash table can take a while. A big (roughly 1 billion entries) table takes almost 1 hour to build.” Remember this one billion number, turns out that although it sounds big, we will explain later that the problem can become a lot worse and quickly.
It does however seems that very little changes, Coelho continues to describe the challenge elegantly: “The idea is very simple: it’s a basic hash table which is run on mmap()’ed memory so that it can be loaded from disk with a single system call. I’ve heard this type of system to be referred to as baked data; you build structures in memory that can be written from/to disk without any need for parsing/converting.”
This mmap use case still requires a fully populated and “precomputed hash”. You have to take the time up front to build the hash, it is worth it if you are revisiting the same data. However, what if you were to use rather clever silicon to compute the hash as you go? FPGAs are a nice architecture to attempt to pull this off. Can it be done?
FPGA: Tiny Compute, Big Data
Sang-Woo Jun, a CSAIL MIT graduate student and first author of a paper describing a device that was presented at the International Symposium on Computer Architecture meeting in Los Angeles, California explains how a personal computer can process huge graphs. Graphs are critically important in computer science, as they become larger, once again we are faced with the challenge of trying to fit them into DRAM. A canonical use case to test these systems is the Web Data Commons Hyperlink Graph, which has 3.5 billion nodes and 128 billion connecting lines. To process the WDC graph, required a server that contained 128 GB of DRAM.
The researchers achieved the same performance by with two of their devices with a total of 1 GB of DRAM and 1 TB of flash. By combining multiple devices, they could process up to 4 billion nodes and 128 billion connecting lines this would not fit inside a 1 GB server. They have clearly built a significantly more elegant version of the Tie::File Perl construct mousetrap. Why?
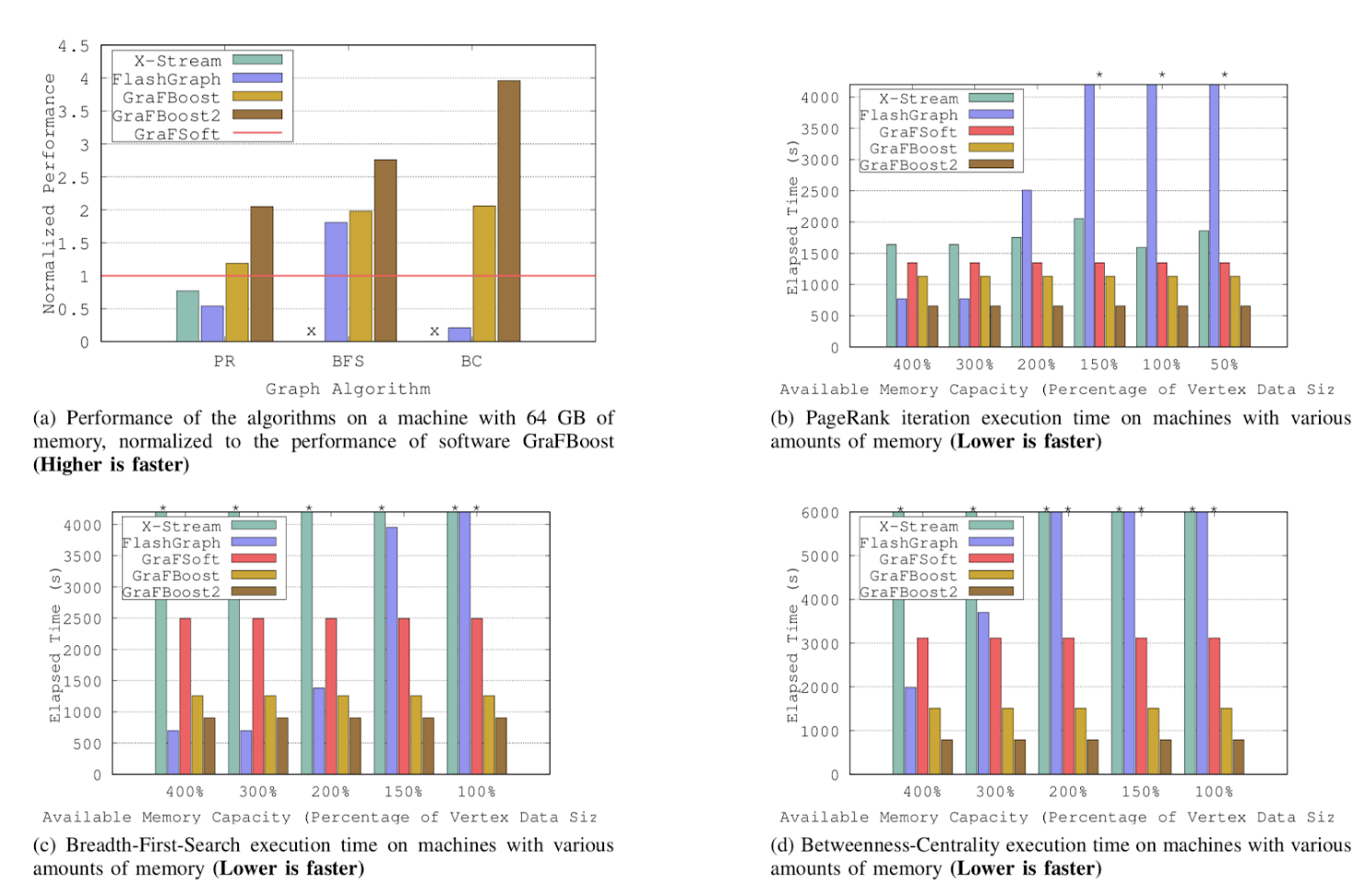
It is not only about the physical memory, in fact this new graph use case came out from earlier work from the group in 2016 where they constructed their initial prototype called BlueDBM. Blue DBM now on revision B shows both the FPGA core (on the left hand side, with the eight flash memory chips on the right with the giveaway 8X SATA controller sockets below in blue. They don’t just stop at that custom board however.

The custom flash card was developed in concert with both Quanta Computer and Xilinx, and partially funded by the National Science Foundation (CCF-1725303) and Samsung GRO grants in 2015 and 2017. Each flash card has 512 GB of NAND flash storage with a Xilinx Artix 7 chip, and plugs into a host FPGA development board via a FPGA Mezzanine Card (FMC) connector. The flash controller and error-correcting code (ECC) are implemented directly on the Artix 7 chip, providing the Virtex 7 FPGA chip on the VC707 with both logical and error-free direct access into the flash. The communication between the flash board and the Virtex 7 FPGA comes from a four-lane aurora channel, implemented on the GTX/GTP serial transceivers that come bundled with each FPGA.
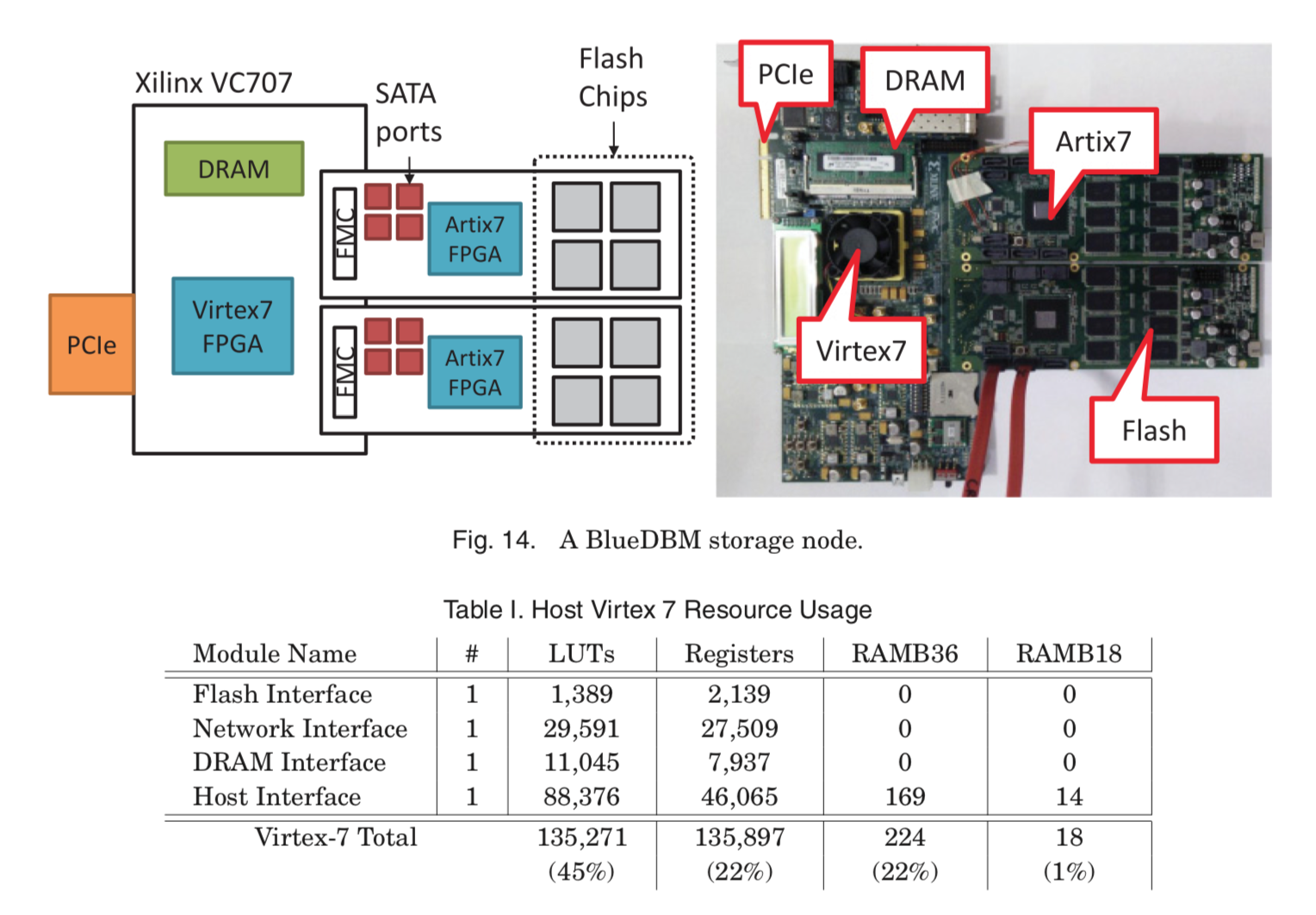
This channel can sustain up to 3.3GB/sec of bandwidth with 0.5 microsecond latency. Impressive for a small set of silicon pieces. The flash board also hosts the eight SATA connectors, four of which pin out the high-speed serial ports on the host Virtex 7 FPGA at 10 Gb/sec, and four more which pin out from the high-speed serial ports on the Artix 7 chip running at 6.6 Gb/sec. The architecture of the final system before it eventually bolts on to the PCI-Express interface of a host Linux system terminates by connecting to the Xilinx VC707 board.
The underlying software stack is also fairly complex in order to support all the various moving parts:
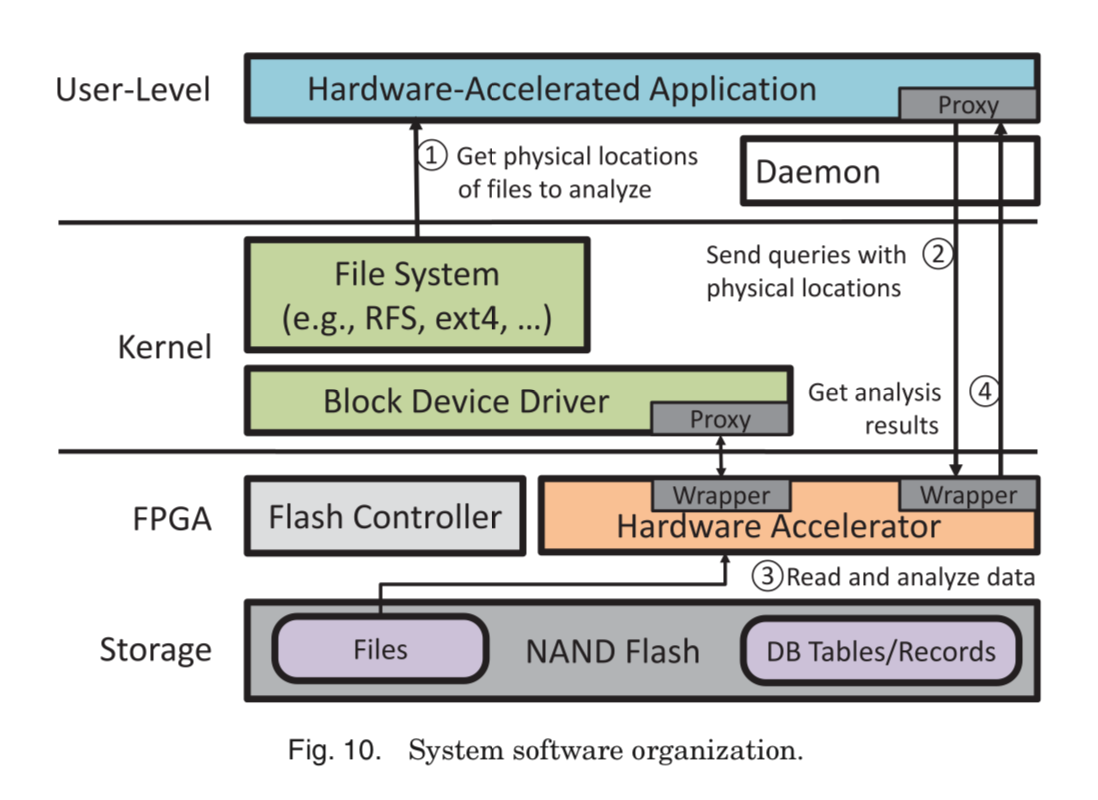
This essentially provides an accelerated block device driver that is eventually presented up to the operating system. What is different here is the hardware accelerator is between the actual flash and the database tables and records. So what they end up with is a board that can index data at high speed and try not get in the way of the data path. Jun et. al. continue to describe other potential use cases of this hybrid flash+FPGA+X86 chain to include content based image retrieval, flash based key value stores, accelerated SQL along with their multi-terabyte graph analysis that uses vertex value updates in the flash storage Jun et. al. presented at the ISCA meeting.
Are there other ways to do the same thing? Large memory public cloud instances with 4 TB of RAM can be rented for large sums of money by the hour, and such multi-terabyte in memory databases are frequently installed in large data-hungry enterprises such as healthcare and data analytics shops. However just the energy alone needed to run them, never mind the exceptional cost of this much raw silicon to provide large memory systems makes for a very compelling reason to rethink what how we do big data. At the other end of the scale, driven by extreme AI workloads we also recently covered the use of currently mostly non-existent but fascinating neuromorphic memory systems due to the inherently complex data parallel memory issues associated with many AI workloads.
Clearly ever more elegant and sophisticated methods to manage memory access both of the fast and large type are needed and maybe by using new low cost pipelined FPGA methods that are able to get memory even closer and better aligned to the underlying physical processors then coupled with the appropriate computer science to manage the ever present index challenge may finally provide new ways to beat the “It won’t fit. It is too slow” overarching issue we have all been faced with for decades.
Then maybe, just maybe, perhaps 640 PB ought to be enough. Maybe.

Apache Druid Takes Its Place In The Pantheon Of Databases
A decade ago, Fangjin “FJ” Yang was a software architect at startup Metamarkets, a company that was building a user-facing analytics engine that a lot of developers simultaneously could go to, click on a UI, and very quickly get answers to their questions. It was a good idea, but it …
Just How Bad Is CXL Memory Latency?
Conventional wisdom says that trying to attach system memory to the PCI-Express bus is a bad idea if you care at all about latency. The further the memory is from the CPU, the higher the latency gets, which is why memory DIMMs are usually crammed as close to the socket …
Microsoft Azure Blazes The Disaggregated Memory Trail With zNUMA
Dynamic allocation of resources inside of a system, within a cluster, and across clusters is a bin-packing nightmare for hyperscalers and cloud builders. No two workloads need the same ratios of compute, memory, storage, and network, and yet these service providers need to present the illusion of configuration flexibility and …
The quote “Data is like gas” is from Ray Kurzweil while being at Microsoft back in the day, right ?