

The world of AI software is quickly evolving. New applications are coming on the scene on almost a daily basis, and now is a good time to try to get a handle on what people are really doing with machine learning and other AI techniques and where they might be headed.
In our first two articles trying to assess what is happening out there in the enterprise when it comes to AI – Lagging In AI? Don’t Worry, It’s Still Early and New AI Being Mostly Used To Solve Old Problems – we discussed how real-world users are approaching AI and how they are using AI to solve problems and optimize their organization. In this article, we are going to take a peek into the AI corner of the datacenter and see what companies are using in terms of hardware and software.
In our survey at OrionX.net, we presented users with a list of two dozen AI frameworks and asked if they were planning to use the framework, if they have already used it, or if they consider themselves an expert.
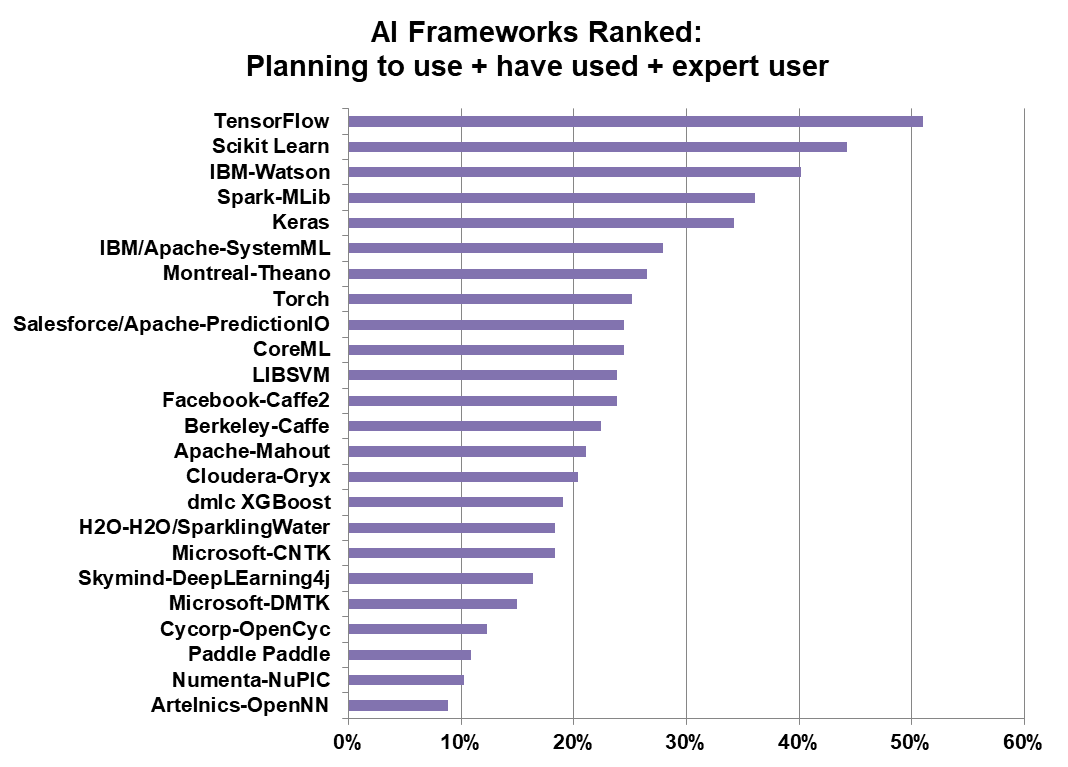
Very few professed to be an expert in any of the frameworks, with the average hovering around 2 percent. Scikit Learn and TensorFlow, the most popular frameworks, were the exception with 9 percent and 12 percent, claiming expert status respectively. However, as the chart below shows, customers are familiar with a large number of AI frameworks, although they don’t rate themselves as experts.
IBM Watson was the third most used AI framework, with Spark-MLib holding down fourth place. It was surprising to us to see that all 24 frameworks had fans and adherents. Usually when you present a list like this to users in a survey, you see four or five highly popular choices and the rest consigned to obscurity. This certainly isn’t the case when it comes to AI frameworks.
While these are all machine learning toolsets, they aren’t complete substitutes for each other, which means that one or two popular frameworks like TensorFlow and Sciket Learn won’t push the others into extinction.
AI Hardware: A Closer Look
So how big are these projects? And how big are the clusters they’re using for AI processing? Here’s what we found out.
The average data size for all of the AI projects the respondents are working on today is 442 TB, with the average size of their largest single project coming in at 235 TB. So it looks like the typical organization in our survey is doing some seriously large projects according to the average numbers below.
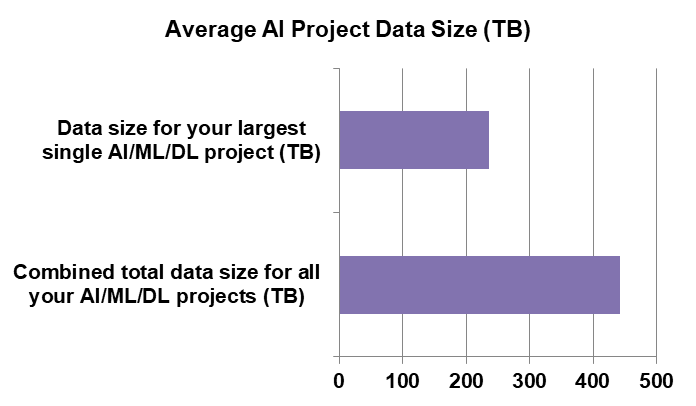
However, these stats are a bit deceiving. The real picture becomes clear when you look at the medians rather than the averages. The median combined total size of AI projects, in data terms, is only 17 TB, while their largest single project comes in at only 5 TB.

The explanation for such a wide range between the average and median numbers is that there are a small number of enormous projects that are skewing the numbers to a great degree. The AI trend is still in its infancy and there are very few organizations who have extremely large AI projects underway at this time.
This is borne out by looking at the average cluster size used by our respondents for their AI projects. As you can see in the chart, more than 60 percent of our respondents have clusters with fewer than 128 nodes and a large number are using clusters with fewer than 32 nodes. On the other hand, a small handful have more than 2,048 nodes and only 20 percent report that their clusters are between 512 and 1,024 nodes.
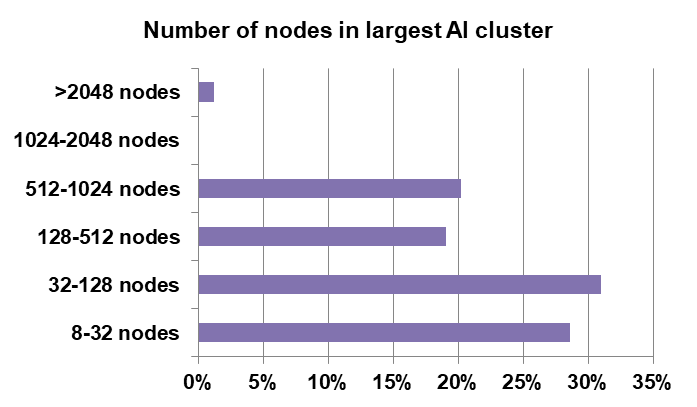
This is also confirmation that we’re relatively early into the AI Age. As we proceed further, we are likely to see rapid growth in the size of AI clusters.
Wide, Wide World of Accelerators
In the hardware section of the survey, we asked a few questions about compute accelerators like GPUs and FPGAs. As you know, these handy devices turbo-charge numeric processing and can radically accelerate deep learning tasks as well – particularly when it comes to machine learning training models. GPUs have become the accelerator of choice for most users, but we expect to see usage of purpose-built AI FPGAs increase over time as users become more familiar with them.
We asked customers how familiar they are with particular GPU and FPGA accelerators by presenting them with a long list of candidates and asking them if they were either familiar with the device or if they were currently using it.
The list below represents every accelerator we could find during the spring-summer of 2017. By now, there are probably even more accelerators on the horizon, or else bigger players have purchased more of the accelerators on our list.
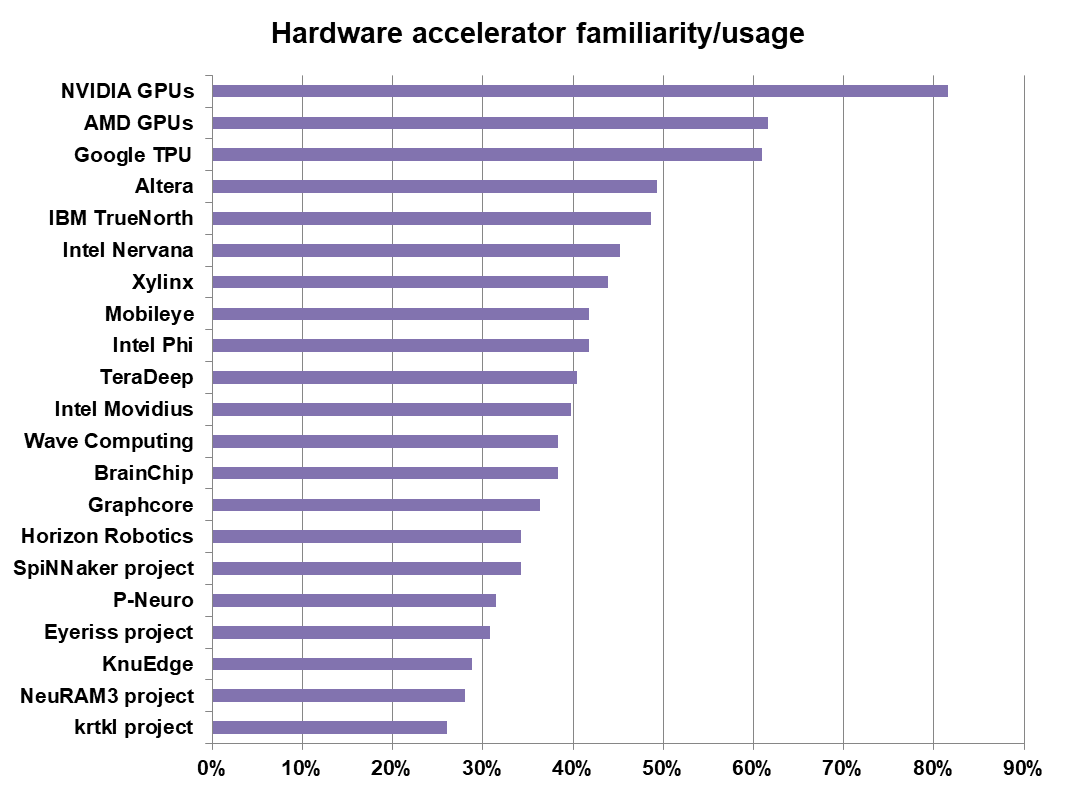
It is no surprise to see that 80 percent of our respondents were either using or familiar with Nvidia GPU accelerators. AMD GPUs and Google TPUs are nearly tied for familiarity/usage at just over 60 percent, with Intel’s Altera FPGAs coming in fourth. Intel, in fact, has a number of entries on the list due to its purchasing FPGA tech companies right and left (Altera and Movidius, to be specific).
One thing we didn’t expect was for respondents to be highly familiar or using the lesser known technologies on our list. Even the least well known/used hardware on the list, from Krtkl, a small designer of embedded FPGAs and the like, was recognized by 25 percent of our survey base.
The Bottom Line
This is the third in our series of articles about the OrionX.net AI survey. In the first story, our data showed that while most all of our survey respondents had AI projects underway, very few (about 7 percent) were actually in production. In the second article we found that the large majority of real world AI initiatives are aimed at advancing and streamlining typical applications like predictive maintenance and analyzing big data. While image, voice, and video AI analysis seems to get the lion’s share of press attention, most customers are using AI to analyze numbers and text.
Finally, in this third article, we learned that while there are a few very large AI projects (at least judging by our 300+ survey respondents) the median project is pretty small in terms of data (about 5TB). We also found that real-world customers are dialed in when it comes to AI accelerators such as GPUs and FPGAs, they know both big and small players in this market. We also again confirm our hypothesis that it is very early in the evolution of AI and that the real growth in this exciting market segment is yet to come.
Dan Olds is an authority on technology trends and customer sentiment and is a frequently quoted expert in industry and business publications such as The Wall Street Journal, Bloomberg News, Computerworld, eWeek, CIO, and PCWorld. In addition to server, storage, and network technologies, Dan closely follows the Big Data, Cloud, and HPC markets. He co-hosts the popular Radio Free HPC podcast, and is the go-to person for the coverage and analysis of the supercomputing industry’s Student Cluster Challenge. Olds is founder and principal analyst at Gabriel Consulting Group (GCG), a boutique IT research and consulting firm whose activities are now part of the OrionX.net offerings. Dan began his career at Sequent Computer, an early pioneer in highly scalable business systems. He was the inaugural lead for the successful server consolidation program at Sun Microsystems, and was at IBM in the strategically important mainframe and Power systems groups. He is a graduate of the University of Chicago Booth School of Business with a focus on finance and marketing.

New AI Being Mostly Used To Solve Old Problems
In the first article outlining some of the results from our AI survey, we discussed how most customers are just beginning their journey into AI and that very few have actual AI applications in production. In this article, we are going to talk about the whats and whys behind AI. …
Lagging In AI? Don’t Worry, It’s Still Early
Without splitting a lot of hairs on definitions, it is safe to say that machine learning in its myriad forms is absolutely shaking up data processing. The techniques for training neural networks to chew through mountains of labeled data and make inferences against new data are set to transform every …
Google is offering the TPUs at about 1/2 the cost of using Nvidia with AWS. But this was the TPU 2.0. Be curious if we see the cost further reduce. Suggest Google is now 2 generations ahead of Nvidia.
It all comes down the cost of getting some work done. When Google moved their TTS using a neural network at 16k samples a second and offering at a competitive price to using the old and very low computational method.