

Analytics systems have been downing in data for years, and the edge is going to flood it unless the architecture changes. There is so much data that is going to be generated at the edge of the network that it can’t be practically moved back to the datacenter for processing in a timely enough fashion to be useful in a way that the gathering of the information was done in the first place.
That is the premise behind our expanding coverage of edge computing and what is evolving into a distributed, multi-tier data processing complex – you can’t really call it a datacenter any more.
A fundamental driver behind edge computing, which includes the Internet of Things but also many other forms of distributed compute. This fog of machinery is comprised of smartphones and tablets that the modern worker is carrying, of course, but also huge numbers of systems that are being infused with intelligence, from manufacturing machines and vehicles to ships, planes, offices, appliances and the buildings and infrastructures that make up the increasingly smart cities. Those connected systems – there are expected to be 20 billion or more smart connected devices in the world by 2020 – are extremely chatty individually and there is a cacophony of data coming off of them collectively.
Companies deal with much of that data today by sending it to public clouds or to on-premises systems to be cleaned, reduced, and analyzed various techniques, ranging from simple statistics to machine learning. However, that can be a costly process, both in terms of money and time. There’s a price that comes with sending so much data over the network and into the cloud, and then having the work done using tools available in Amazon Web Services, Microsoft Azure, Google Cloud Platform or any of the other public clouds that are available. There also is the issue of latency – it takes time to move the data into the cloud, and then to move the results back out. There is an increasing need for real-time or nearly real-time analytics of this data, particularly with use cases such as autonomous vehicles, where action needs to be taken immediately that are dependent on rapidly changing circumstances on the road.
All of that is fueling the need to find ways to enable the edge devices themselves to analyze the data and then act on the results locally, without having to send the data to a central datacenter or to the cloud.
A startup named SWIM, which just dropped out of stealth mode, has a plan to leverage the compute capabilities already at the edge to run analytics and machine learning, creating an environment where the data collected from such systems as smart traffic lights and intelligent manufacturing systems can be analyzed and acted upon at the edge. Those capabilities are incorporated into the company’s SWIM EDX stack, software that can be run on existing edge devices and take advantage of their compute power to run analytics on the data those devices generate.
“The current approach to doing edge-based data anything is one of buying hard disks, collect all the data, stick it on a hard disk, hope like hell that you have it all, and then pray that you can find some way to analyze it later,” SWIM chief technology officer Simon Crosby tells The Next Platform. “We’re saying that’s a total waste of time. You can get by without this terrible headache of monstrous big data stores and batch-style learning and analysis by doing it all on the fly, on CPUs and devices that you’re already on.”
Crosby has been around the block a time or two, and with Ian Pratt brought the Xen open source hypervisor out of Cambridge University to compete with VMware’s ESXi in the early days of X86 server virtualization. After selling XenSource to Citrix Systems, Crosby and Pratt more recently teamed up to found Bromium, which added a security layer to virtual compute. Now Crosby is taking on analytics at the edge.
Chris Sachs, SWIM co-founder and chief architect, and co-founder and chief executive officer Rusty Cumptson worked at Sensity Systems, an outdoor lighting infrastructure company that converted older lighting systems into connected LED systems that generate a lot of data; the company was bought by Verizon in 2016. The lighting data was sent to the cloud, but customers were increasingly asking for real-time analysis and use of that data. That led Sachs and Cumptson to leave Sensity and start SWIM about three years ago.
SWIM EDX focuses on the ideas of using digital twins and leverage the compute power of the systems they’re running on. The concept of digital twins has grown with the rise to the IoT and the cloud. Essentially such a twin is the digital representation of a physical system running at the edge. In SWIM’s EDX, the digital twins can not only analyze the data that’s coming in from their real-world counterparts in real-time, but also can learn from the data, detect patterns and make predictions about future states, and then adapt accordingly.
“SWIM EDX was designed first of all to be software, so you could drop that software onto existing devices,” Simon Aspinall, head of sale and chief marketing officer, explains. “Secondly, EDX is architected so all of the processes are run at the edge – the data ingest, the data analytics, even the learning and the predictions – and the ability to combine resources together for a compute, edge and data fabric so that you can effectively pool resources across all of the edge devices and use them to attack this problem of how you handle large volumes of data.”
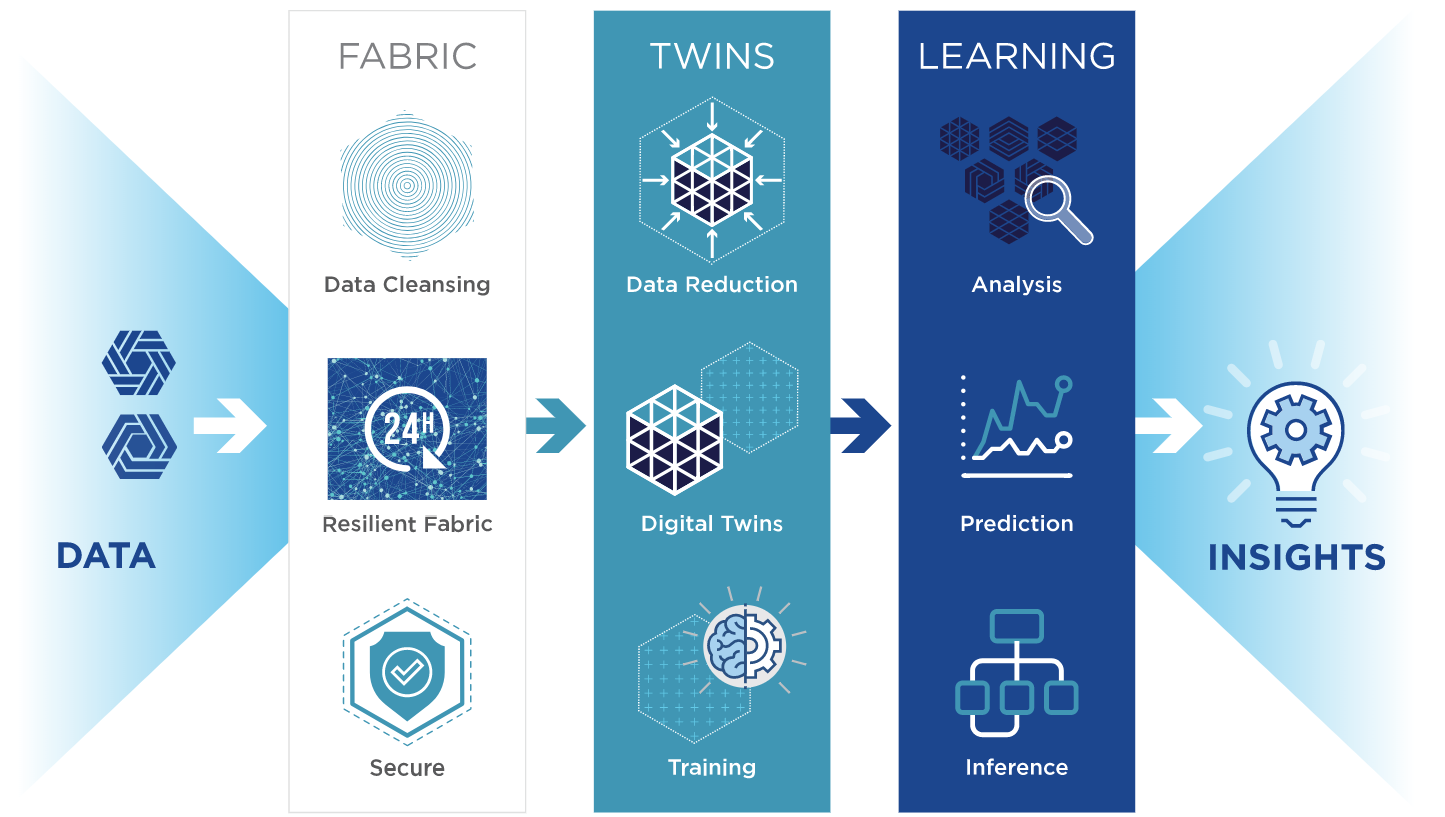
Crosby says the SWIM EDX software essentially finds whatever entities generate data and automatically builds a digital twin that “consumes the real-world data for its sibling. It consumes that real-world data, parses it, reduces it down to a very efficient form. But that digital twin is an object which is learning. It represents the face of the real world, so we don’t really need to keep the original data because the digital twin effectively represents the state of that thing. The original data can be discarded. You get this massive efficiency by transforming the data into the state of these twins, and then the twins perform whatever analysis and prediction is needed for the task at hand.”
The results from the analytics can then be used by subscribers, he said. For example, in a traffic analysis situation, the results are presented by an API that can be delivered from the cloud to the subscribers like Uber, Lyft, UPS, Waymo or insurance companies that can use them to direct traffic, alert drivers or set rates.
The EDX software is fairly lightweight – it can be used in something as small as a controller at a traffic intersection. But between that and the compute power already present in these devices, the results can be significant, according to SWIM. Crosby said that for a relatively small community like Palo Alto, Calif., moving the data collected in a smart city environment to AWS for collection and analysis could cost more than $5,000 a month; using SWIM, that number could be closer to $40 a month.
The company is outlining a range of use cases, including networking, where the software can run on routers, set-top boxes and WiFi controllers for network optimization and performance. Other use cases include logistics (asset tracking), traffic management (reporting real-time conditions and predictions) and smart cities (for smart meter, smart grids and smart lighting).
“Most of the data that is generated in the world is just thrown away,” Sachs says. “We have these ideas that we have big data and we can look at all this data and we analyze the data that we create. But really, we only analyze a sliver of 1 percent of the data that is generated by this automated, mechanical world that we’ve already built. But the data is complicated and it’s opaque and no two places in the world are alike. No two traffic intersections are alike, no two factories are alike, and even machines that are highly regular and mass-produced sit in different environments and operate in different ways, so in order to build on and learn from this data you have to have an automated way for dealing with the 99.9 percent that is generated in the world but is currently thrown away because they don’t know what to do with it.”


Lenovo Bundles VMware Stack At The Edge
Enterprises and tech vendors alike for the past few years have been talking about the growing importance of the edge in the increasingly distributed IT environment. It’s at the edge where more data is being generated and stored, and organizations are feeling the need to process, analyze and act on …

Supermicro Plants A Flag At The Edge
In a short time, the edge has become the crucial third leg holding up the IT stool, joining traditional on-premises datacenters and the public clouds. That is not surprising, given the increasingly distributed nature of the enterprise. The cloud, the proliferation of mobile devices, the Internet of Things (IoT), the …

The Edge Is The New Frontier For IT
The datacenter is becoming hyperdistributed and incorporating some multiple of capacity – 2X, 3X, 4X, or maybe 10X – outside of the traditional datacenter walls because applications and storage live increasingly at the edge. The edge is not just a new frontier for customers, who are being drawn out of …
Be the first to comment