
When Nvidia co-founder and chief executive officer Jensen Huang told the assembled multitudes at the keynote opening to the GPU Technology Conference that the new DGX-2 system, weighing in at 2 petaflops at half precision using the latest Tesla GPU accelerators, would cost $1.5 million when it became available in the third quarter, the audience paused for a few seconds, doing the human-speed math to try to reckon how that stacked up to the DGX-1 servers sporting eight Teslas.
This sounded like a pretty high price, even for such an impressive system – really a GPU cluster with some CPU assist for managing parameter settings for machine learning workloads and hooking to the outside world, thanks to the new NVSwitch memory fabric switch that was also announced today. Huang paused a bit, waiting for everyone to do the math, comparing how it would take a row of CPU-only servers based on Intel’s latest “Skylake” Xeon SP processors, costing around $3 million, to do the same work. Then Huang stopped pulling everyone’s leg and said that the DGX-2 system would cost only $399,000, which is a perfectly reasonable price for what amounts to two DGX-1 GPU compute trays interlinked with the NVSwitch with extremely high bandwidth ports and delivering a GPU complex with 512 GB of aggregate and shared HBM2 frame buffer memory and an upgraded CPU complex sporting two new Skylake chips and some other upgraded components.
The DGX-1 system, in both its “Pascal” and “Volta” incarnations, had the Xeon compute complex in one enclosure, linked by PCI-Express switches out to a separate chassis that included eight Tesla accelerators hooked to each other in a hybrid cube mesh, allowing them to access each other’s memory and act as a single virtual GPU to the CUDA software environment riding above it. With the DGX-2 system, a second GPU accelerator tray is added to the system, and both trays have six of the NVSwitch ASICs on their backplanes, which implement the crossbar of memory fabric switch and create very high bandwidth – we are talking about 300 GB/sec of bi-directional bandwidth for each GPU as it talks to the adjacent GPUs in each enclosure, and somewhat more bandwidth than that connecting out to the other side of the crossbar to the other eight GPUs, albeit this is shared rather than dedicated bandwidth.
The DGX-2 comes with the upgraded Volta Tesla V100 SXM3 accelerators, which now have their HBM2 memory stacks fully fleshed out, eight chips high, and sport the 32 GB of memory that many had been expecting last May when the Volta chips were first announced. This extra memory capacity is important for a slew of HPC and AI workloads, which have been trying to work in the 12 GB memory footprint of a “Kepler” accelerator or the 16 GB footprint of the Pascal SXM2 and prior Volta SXM2 accelerators. The PCI-Express versions of the Volta chips have all been upgraded to the full 32 GB of memory, too, and Ian Buck, vice president and general manager of accelerated computing at Nvidia, tells The Next Platform that in the DGX-1V systems, the pricing will remain the same when it is equipped with eight of the Volta GPU accelerators with only 16 GB each; so, there’s some free memory. Buck says that there might be a nominal charge for the higher memory capacity through the reseller channel partners also selling Volta-equipped systems, but that this is really up to partners. Nvidia is not charging them extra for the memory, apparently, but it will obviously have a big effect on performance. We are not sure if the extra memory will boost the memory bandwidth of the HBM2 memory complex; more devices does not necessarily add up to more bandwidth. That said, the 900 GB/sec of bandwidth that the 16 GB versions of Volta provided is still a lot, and it increased by 20 percent while the capacity didn’t change at all. This implies the bandwidth across that increased capacity in the Volta SXM3 device has not changed from the SXM2 version.
(Just a reminder: We went into the details of the Volta architecture here and did a price/performance analysis of the Tesla GPUs, from Kepler through Volta, there.)
Here is the exploded view of the DGX-2 showing its components:

In this exploded view, item 1 is for the Volta V100 SXM3 units, and item 2 shows the Volta SXM3 board with eight of the units on it for one of the enclosures. The six NVSwitch ASICs are in the back of each enclosure (item 3). There is a second item 2 to the right of the image, which shows the twelve sets of port hubs for the NVSwitch fabric backplane. Item 4 is a set of eight 100 GB/sec EDR InfiniBand or 100 Gbsec Ethernet network interface cards (from Mellanox Technologies) for hooking the DGX-2 system out to the outside world, which offers a collective 1.6 Tb/sec of bandwidth. Item 5 is the PCI-Express switch complex, which is used to link the two GPU compute enclosures to the dual Xeon SP Platinum processors in the system (item 6), which are equipped with 1.5 TB of shared DRAM memory (item 7). The system is also equipped with a dual-port Ethernet controller that can run at 10 Gb/sec or 25 Gb/sec speeds for system management (item 8). That leaves item 9, which is a set of NVM-Express flash drives that have 30 TB of aggregate capacity and that can be expanded to 60 TB. The whole shebang costs $399,000.
The DGX-1V machine used two 20-core “Broadwell” Xeon E5-2698 v4 processors running at 2.2 GHz, and came with only 128 GB of main memory and four 1.82 TB flash drives (not NVM-Express capable) that had 7.28 TB of capacity. We do not yet know what processor is in the DGX-2, but it is probably a 24-core Skylake Xeon SP, which would be the Xeon SP-8168 running at 2.7 GHz and yields about 60 percent more integer throughout than the Broadwell chip and also allows for up to 1.5 TB per socket of main memory rather than the 768 GB per socket cap on other memory-restricted Xeon SP chips. This processor change alone contributes $5,328 at list price to the incremental cost of the DGX-2 system. Moving from 128 GB to 1.5 TB is much more expensive, probably somewhere around $35,000. Those eight InfiniBand cards probably costs somewhere around $8,000, and heaven only knows what the flash drive upgrade costs but depending on the type of flash used, that could cost somewhere around $30,000 to $40,000. Call it $30,000. So the incremental stuff in the box thus far adds somewhere around $80,000 to the cost. Adding a second tray of eight Volta GPUs is probably on the order of $110,000, we reckon, and that implies that the NVSwitch represents somewhere around $64,000 of the total cost of the DGX-2, which works out to around $4,000 per port running at 300 GB/sec of bi-directional bandwidth. That seems like a reasonable price, with a 100 Gb/sec port on an Ethernet switch running around $500 to $550 per port and delivering 12.5 GB/sec of bandwidth. The NVSwitch is delivering 24X the bandwidth and at that price we estimate above, at maybe 8X the cost.
Here is how the bang for the buck stacks up between the Pascal and Volta versions of the DGX-1 and the new Volta version of the DGX-2:
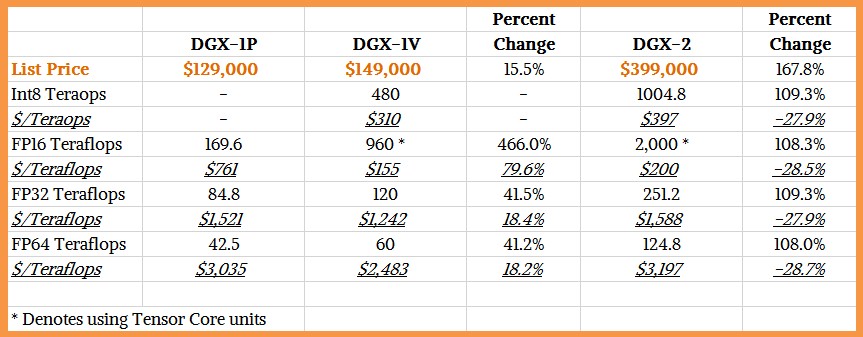
Compared to the DGX-1V (which is how we designate the Volta version) from last year, which did not have the slightly higher performance that was available in the Volta SXM2 units in the fall of 2017, the DGX-2 has a little more than twice the raw peak GPU performance, but at a price that is a bit more than twice as high. So technically, the price/performance got a little worse, not a little better. But the DGX-2, as we show above, has a lot more networking, memory, and flash storage in the Xeon part of the box, as well as the Xeon SP upgrade and the NVSwitch interconnect for the GPUs. So this is all good. A DGX-1V with the NVSwitch in it to boost bandwidth would also cost more, and so would upgrading the memory and the flash.
It should not be very hard to argue for the DGX-2 over the DGX-1V for machine learning workloads, especially considering how the software stack has also been improved, as Huang showed off:
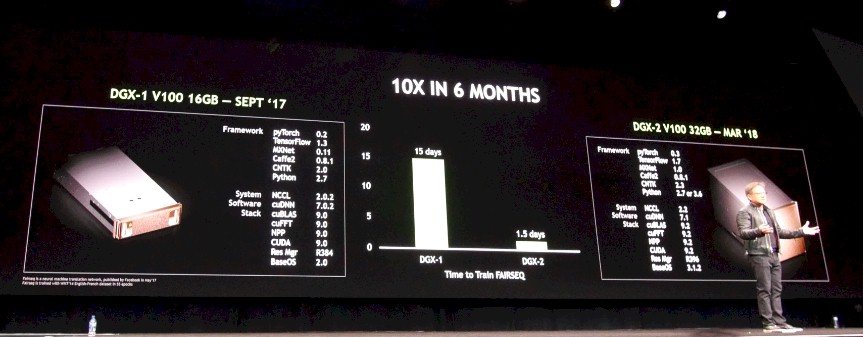
By moving to the new DGX-2 iron with the NVSwitch, adding the latest software stacks as shown above, which includes substantial improvements in the PyTorch framework, the Fairseq benchmark completed in 1.5 days on the DGX-2 compared to 15 days for the same test on the DGX-1V back in September 2017. That is a factor of 10X improvement in only six months, which is way ahead of Moore’s Law, as Huang pointed out. And, this single DGX-2 system can do the Fairseq training that it would take 300 two-socket Xeon servers, costing around $3 million, to accomplish, and do so in a 10 kilowatt envelope instead of the 180 kilowatt envelope of the row of X86 servers.
That is 1/8th the cost, 1/6th the space, and 1/18th the power of the CPU-only cluster to do the same work, according to Huang. These are the kinds of numbers that compel companies to change architectures, to be sure, but we do not think there are many serious companies doing machine learning training on CPUs. So that comparison might be moot. It certainly is not for HPC workloads, where CPUs still dominate, but the same kind of factors could come into play if applications can be ported to GPUs and make use of features such as NVSwitch.

Opening Up The Future “Venado” Grace-Hopper Supercomputer At Los Alamos
There are many interpretations of the word venado, which means deer or stag in Spanish, and this week it gets another one: A supercomputer based on future Nvidia CPU and GPU compute engines, and quite possibly if Los Alamos National Laboratory can convince Hewlett Packard Enterprise to support InfiniBand interconnects …
Arm’s v9 Architecture Explains Why Nvidia Needs To Buy It
Many of us have been wracking our brains why Nvidia would spend a fortune – a whopping $40 billion – to acquire Arm Holdings, a chip architecture licensing company that generates on the order of $2 billion in sales – since the deal was rumored back in July 2020. As …
The New General And New Purpose In Computing
The term “general purpose” in regards to compute is an evolving one. What looked like general purpose in the past looks like a limited ASIC by today’s standards, and this is as true for GPUs and FPGAs as it is for CPUs. There is much talk about the era of …
Hmmm
So what are some of the specific practical applications which would justify a 400K+ purchase (as in something that companies are actually doing right now that would continue to generate profits after this implementation) Just curious if someone would cite some real world examples. Otherwise this appears to be little more than a marketing stunt designed to continue to raise consumer perception of relative cost to justify leaving the sky high consumer GPU market in the stratosphere now that bitcoin mining is coming back down to earth…..
“this appears to be little more than a marketing stunt”
Uh, Nvidia’s data center business is booming. Here’s a quote from their last quarterly report:
“Revenue from Nvidia’s widely watched data center business, which counts Microsoft Corp’s (MSFT.O) Azure cloud business as its customer, more than doubled to $606 million.”
It is widely known that companies such as Google and Facebook are buying such systems by the truckload. In general, AI programs are the biggest target for their data center business.
A simple check of their website shows even their expensive stuff is in short supply such as the $9K Quadro GV100 which is limited to 5 per customer.