

Big iron aficionados packed the room when ORNL’s Jack Wells gave the latest update on the upcoming 207 petaflops Summit supercomputer at the GPU Technology Conference (GTC18) this week.
In just eight years, the folks at Oak Ridge have pushed the high performance bar from the 18.5 teraflops Phoenix system to the 27 petaflops Titan. That’s a 1000X + improvement in eight years.
Summit will deliver 5X to 10X more performance than the existing Titan machine, but what is noteworthy is how Summit will do this. The system is set to have far fewer nodes (18,688 for Titan versus ~4,600 for Summit) and deliver that 5X to 10X more performance while only increasing power consumption from nine to 13 megawatts. For background, here around twenty or so in-depth articles on various aspects of Summit’s performance, architecture, and design philosophy in relation to the host of other DoE and NNSA machines set to come online in the near term.
As we have discussed before, obviously, the Summit nodes are much more powerful than Titan nodes. Each Summit node will host dual IBM Power9 22-core processors, running around 4.0 GHz. The nodes will also be equipped with 6 Nvidia Volta GPU accelerators, connected to the system via NVLink 2.0 (running at 300 GB/sec). Each node will have 512 GB DRAM, 96 GB High Bandwidth Memory (HBM), and a 1.6 TB NVMe card. Linking this all together will be the latest and greatest Mellanox Infiniband EDR 100 Gb/sec interconnect technology.
There has been speculation in the industry that tight supplies of Volta V100 GPUs have delayed node delivery to ORNL. We’re not sure if this is still true. Right now, ORNL has 1,080 accepted Summit nodes at their site, which is a little under a quarter of the entire system and a bit behind the schedule we expected to see.
Summit will be a whole new world for ORNL users in terms of scale, but also in terms of architecture. In order to prepare users for the Summit experience, their Center for Advanced & Accelerated Application Readiness (CAAR) has been busy training users and building documentation.
Users also have early access on the SummitDev (54 Power 8 Minsky nodes, NVLink1, Pascal GPUs) and Summit Phase 1 (1,080 full Summit nodes) systems. Their experiences have already provided some data points on just how well Summit performs vs. Titan on real world applications. Some of the highlights include:

Initial results with FLASH show that Summit with Power9 processors and V100 GPUs is 2.9X faster than FLASH with only Power9 CPUs. The FLASH runs below used 288 nuclear species, which is too large to run on Titan. QMCPACK: is a quantum mechanics based simulation of materials, which is useful for figuring how superconductors react under high temperature conditions. Initial runs of QMCPACK show it behaving well on configurations up to 64 Summit nodes using the latest version of the code without modification.

QMCPACK on Summit is radically faster than it was on Titan. Node to node comparisons show a nearly 50X speedup, which is pretty sporty indeed – and more than you’d think you’d see based on the hardware. The bulk of the improvement has to do with the new (and faster) memory hierarchy in Summit, plus the ability of the code to do much better memory placement and movement. According to ORNL, tuning the application for Power9 and V100 GPUs should give even better results.

If you are able to read the very blurry slide above (live events don’t always lend well to good slide shots), you’ll see that HACC performs 30X better on GPUs than it does on CPUs only. This will allow researchers to run models much more quickly, of course, but, maybe more importantly, the performance boost will let them run much more complex models.
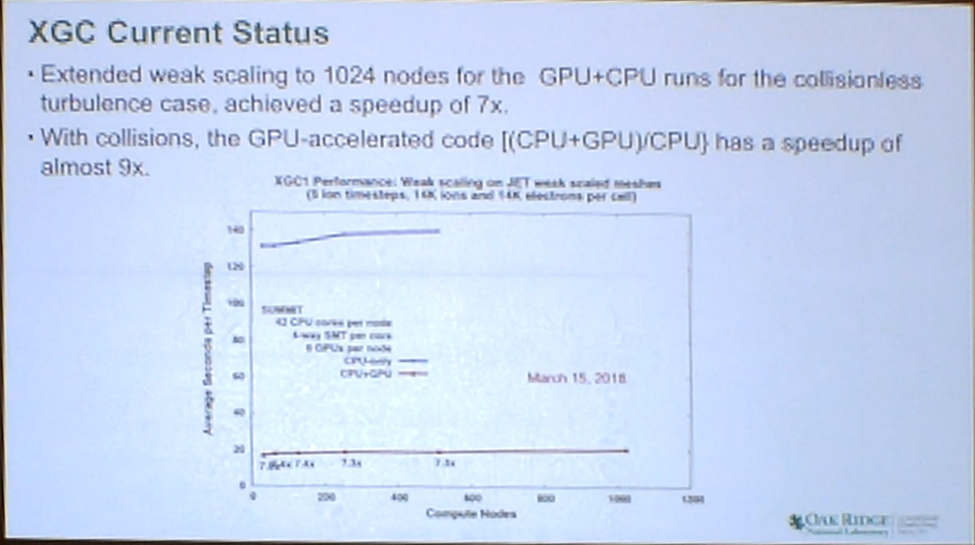
The ‘Particle Pusher’ part of the code was tested on Summit with a collision-less model, showing a 7x speed up for GPU+CPU vs. CPU only configurations. When tested with collisions, which adds significantly more work for the application, the speed up increases to 9x.
With 1,080 accepted nodes, Summit is roughly a quarter of the way to its full configuration. According to ORNL and IBM sources, the system should be complete and accepted in early summer, maybe just in time for the ISC18 Top500 list.
The successor to Summit is already on the drawing boards at ORNL, with an expected delivery in 2021-22 timeframe. If all goes to plan, the new system, named Frontier, should be the first true exascale system in the world, and certainly the first exascale system in the United States.


Software Evolution on ORNL’s Summit Supercomputer
Yesterday with the announcement of the forthcoming El Capitan supercomputer, which is set to be more powerful than the top 200 supercomputers combined, we got to thinking about a critical issue that is far less attention-capturing than big performance numbers. It has to do with exascale software scalability, functionality, modernization, …
Gordon Bell Prize Winners Leverage Machine Learning For Molecular Dynamics
For more than three decades, researchers have used a particular simulation method for molecular dynamics called Ab initio molecular dynamics, or AIMD, which has proven itself to be the method most accurate for analyzing how atoms and molecules move and interact over a fixed time period. In this time of …

Sky-High Hurdles, Clouded Judgements for IaaS at Exascale
Back in 2009, I was the editor of a mini-side publication from supercomputing magazine, HPCwire, called HPC in the Cloud. At that time, the concept was new enough to warrant a formal division between what HPC was and what it would eventually be–and its own dedicated coverage. The first ISC …
Be the first to comment