

The expression, the tail wags the dog, is used when a seemingly unimportant factor or infrequent event actually dominates the situation. It turns out that in modern datacenters, this is precisely the case – with relatively rare events determining overall performance.
As the world continues to undergo a digital transformation, one of the most pressing challenges faced by cloud and web service providers is building hyperscale datacenters to handle the growing pace of interactive and real-time requests, generated by the enormous growth of users and mobile apps. With the increasing scale and demand for services, IT organizations have turned to distributed platforms and microservices architectures for applications to deliver more sophisticated online services. These architectures result in a level of parallelism that makes response times much less predictable, and as it turns out seemingly minor events actually govern overall response times.
The need for datacenter workloads to respond rapidly isn’t new, and has been the primary focus of online transaction processing (OLTP) database vendors for decades. These OLTP workloads were dominated by North-South traffic, with client requests responded to by servers and were well-served by a relatively simple three-tier architectures. However with the explosive growth of social media and mobile apps, traffic patterns have dramatically shifted from North-South (between client and datacenter) to East-West (traffic within the datacenter). For example, a simple online search generates only a tiny amount of traffic between the client and datacenter. But to respond to this simple search generates a massive amount of traffic within the datacenter.
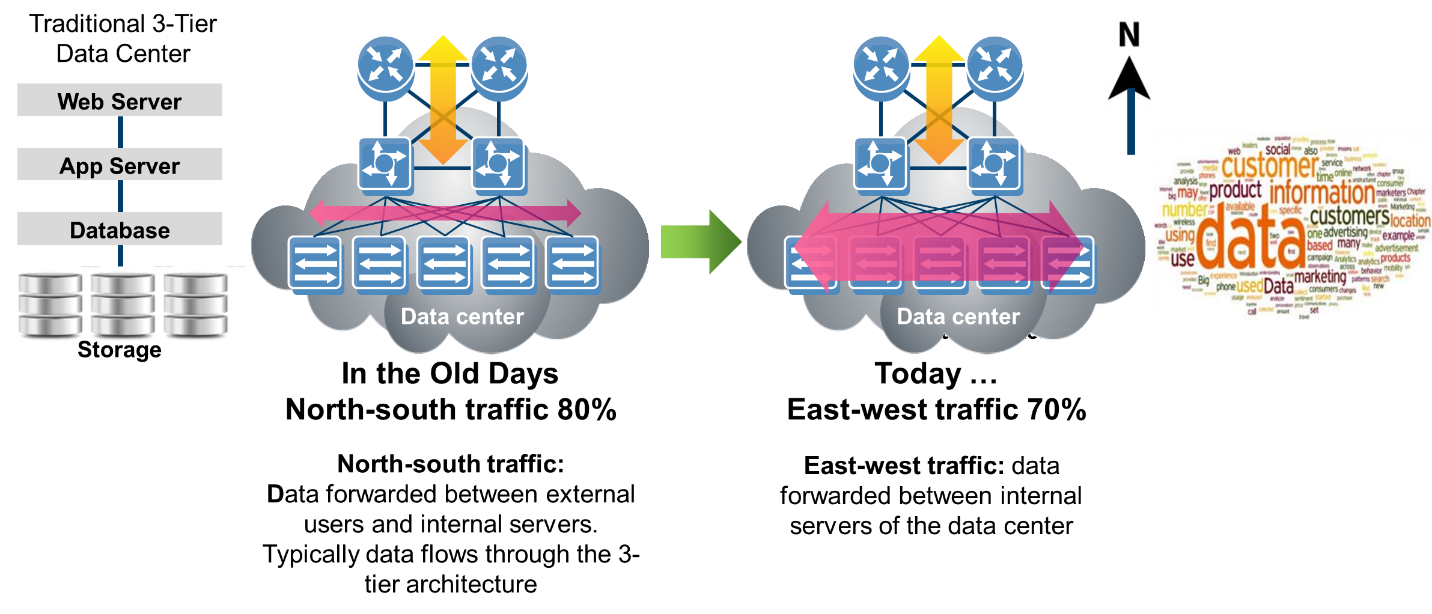
Much of this east-west traffic is related to the core advertising business model behind many of the largest social media and mobile apps. East-west traffic includes internal queries on the user demographics, browsing history, interests, and recent purchases, as well as the tremendous amount of traffic spawned by real-time auctions, which grants advertisers with the highest bids access to the eyeballs of customers that are most likely to click and ultimately buy products or services.
To manage this complex jumble of activities, hyperscale cloud and web providers have migrated to a microservices architecture, where each server performs small tasks and the ultimate customer facing response is assembled from all of these micro-activities. If any single server fails to respond to a micro-request, it is simply re-issued to another server able to perform the same microservice. This scale-out, microservices architecture results in massive multiplication of tasks within the datacenter. It is estimated that a single online query can generate hundreds or even thousands of requests within the datacenter.
This means that potentially thousands of tasks need to successfully complete before a response can be generated to the client. In this environment, the tail does indeed wag the dog. That is even if it is relatively infrequent to experience a long or “tail” latency response, with thousands of microservices executing simultaneously, the slow responder determines the overall response time of the customer facing service. Put another way, tail-latency is the weakest link in the chain, and it can dog performance.
This tyranny of the exceedingly rare is well described in a paper authored by Jeff Dean and Luiz André Barroso, both from search engine giant Google. In The Tail at Scale (Communications of the ACM, Vol. 56 No. 2, Pages 74-80), the authors describe how a relatively small number of performance outliers impacts a significant fraction of all requests in a large-scale distribution system. This is a critical observation, as most system architects focus on average latency when comparing networking, storage, and server architectures. The Google paper clearly demonstrates that system architects should focus not on average, but worst-case latency as the most important factor determining overall performance.
This observation gives credence to the idea that one should use the hardware-based accelerated Remote Direct Memory Access (RDMA) as implemented in Ethernet networks using the RoCE protocol, which delivers not just low average latency, but deterministically low latency. This deterministic latency is in contrast to software transport (for example, TCP/IP), which has both inferior average latency and, more importantly, regularly exhibits vastly inferior tail latency. These mega-latency events can be explained by software corner cases such as page faults, interrupt processing, operating system housekeeping tasks, and so on.
The paper details actual measurements of a Google service of the required to complete a request from a single root server that distributes a request through intermediate servers, to a very large number of leaf servers. The data is listed in Table 1 and shows the effect of large fan out on latency distributions.

The table shows that the 99th-percentile latency for a single random request to finish, measured at the root, is 10 milliseconds. However, the 99th-percentile latency for all requests to finish is 140 milliseconds, and the 99th-percentile latency for 95 percent of the requests finishing is 70 milliseconds, meaning that waiting for just the slowest 5 percent of the requests to complete is responsible for half of the 99th percentile latency.
These measurements clearly demonstrate the heavy toll that even a tiny fraction of poor response times has on overall system performance. The paper goes on to describe several techniques that can be used to improve latency; including detailing the performance gains available from Remote Direct Memory Access (RDMA) capable networking. Enabling higher bandwidth and lower latency, the use of RDMA eliminates bottlenecks and improves overall data center efficiency, while helping service providers to meet their service goals. Although the paper does not include measurements that validate this statement, internal lab testing are detailed below that clearly demonstrate RDMA’s superior latency characteristics.
Managing Data Transport Tail Latency with RDMA
Microsoft was among the first cloud service providers to understand the value that RDMA networking brings to hyperscale datacenters. This began with Windows Server 2012 and the innovative Storage Spaces Direct (S2D) file system, which was designed to run over RDMA. Since then, the solution has been deployed in Microsoft’s Azure public cloud, enabling 2X higher efficiency than TCP/IP. There are numerous publications that describe the value that RDMA-capable networks unleash in S2D, including: “To RDMA, or not to RDMA – that is the question” or “How Microsoft Enhanced the Azure Cloud Efficiency.”
In the tests shown below, we used the Microsoft RDMA-enabled S2D file system to compare the latency when running over TCP/IP and RDMA. For RDMA transport we tested 100 Gb/sec Ethernet RoCE (short for RDMA over Converged Ethernet) networking technology. To run the benchmarks, we built a hyperconverged solution comprised of several components, including a four-node cluster, with each server equipped with a Mellanox ConnectX-5 100 Gb/sec Ethernet NIC supporting TCP/IP and RoCE and running Windows Server 2016 with S2D. For storage, we used four Micron 9100 NVM-Express SSDs (3.2TB each) per node. The cluster was connected using a 100 Gb/sec Mellanox Spectrum Ethernet switch and LinkX cables. We ran the VMFleet benchmark on the cluster.
In order to measure the workload latency, we accessed storage both sequentially and randomly using simple read and write services. Here we focus on one such measurement and compare the average and tail latencies of RoCE with TCP/IP. First, we compared the average latency of 80 VMs, each continuously performing file writes using TCP/IP and RoCE:
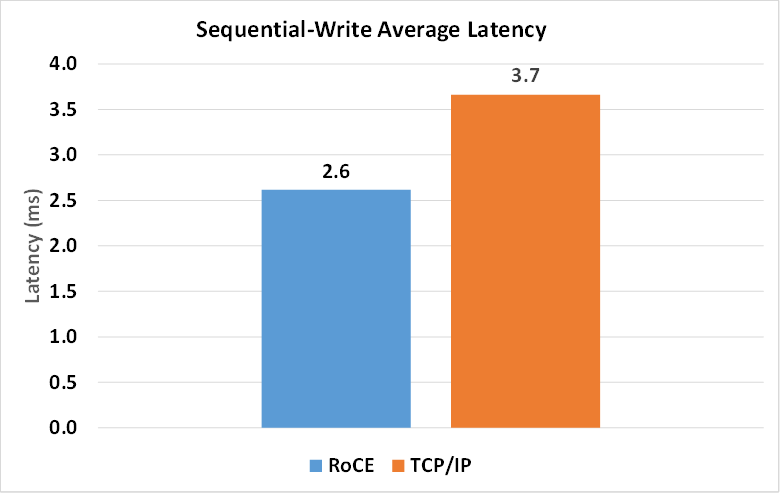
As can be seen, TCP/IP average latency is around 45 percent higher than for RoCE. On top of this, the offload of data transport tasks to the RoCE adapter frees up expensive CPU cycles to run application workloads. For many, these improvements in average latency and CPU utilization alone are sufficient and provide the motivation to move to RoCE-based networking.
But remember, the latency distribution – and specifically tail latency – is even more important to the overall performance of a modern distributed workload. To investigate this, we measured the 50th, 95th, 99th, and 99.99th percentile latency. Here, the results are even more dramatic with TCP/IP degrading the four-nines latency by 628 percent. So RoCE’s performance in tail latency is 14X larger than the benefit when comparing only average latency. On top of this massive improvement in tail latency, RoCE also delivers the hardware transport offload that frees up CPU cycles to run application workload processing.
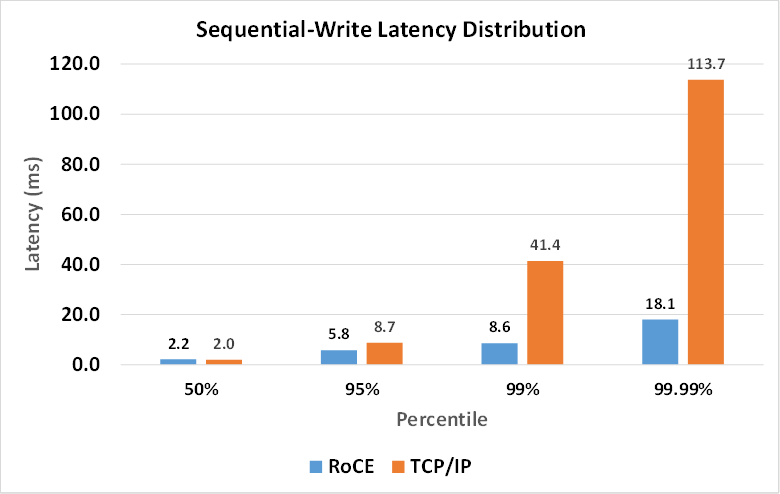
As these results show, RoCE delivers significant improvements in average latency of nearly 50 percent. But looking at only average latency masks the more important effect of tail latency, where RoCE delivers greater than 600 percent improvement in 99.99th percentile latency. The key benefit is the predictability of deterministic tail latency that results from offloading data transport from CPU to the NIC hardware RDMA engines. These results are well aligned with the data presented in the The Tail at Scale paper. The results also prove the superiority of the RDMA transport over TCP/IP, as RoCE delivers both significantly lower average latency and even more importantly lower tail latency – which ultimately determines performance in these distributed workloads.
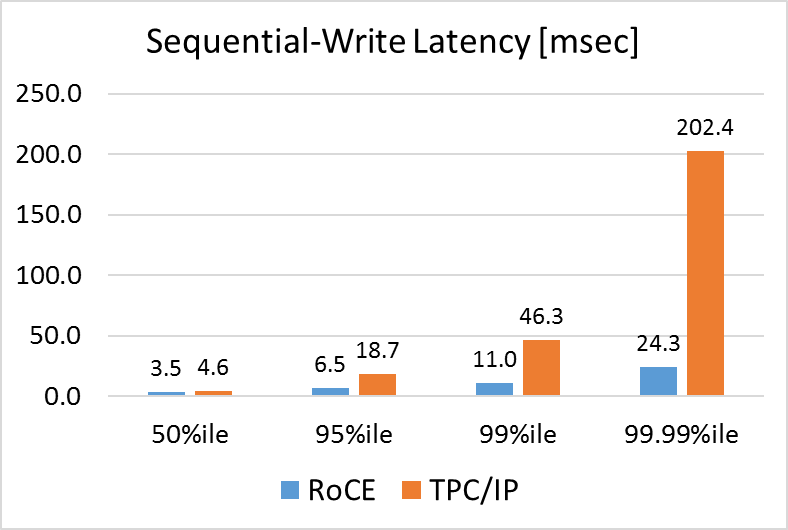
In the case of a sequential write, the pattern is the same as in a sequential read, however the TCP/IP results are much worse than RoCE. The reason is that in the case of writes the high availability technology in S2D requires the data to be stored in several servers. This enforces greater usage of the network compared to reads, such that the data may end up residing on the server’s local cache; therefore, the network isn’t as involved as in cases of write operations.
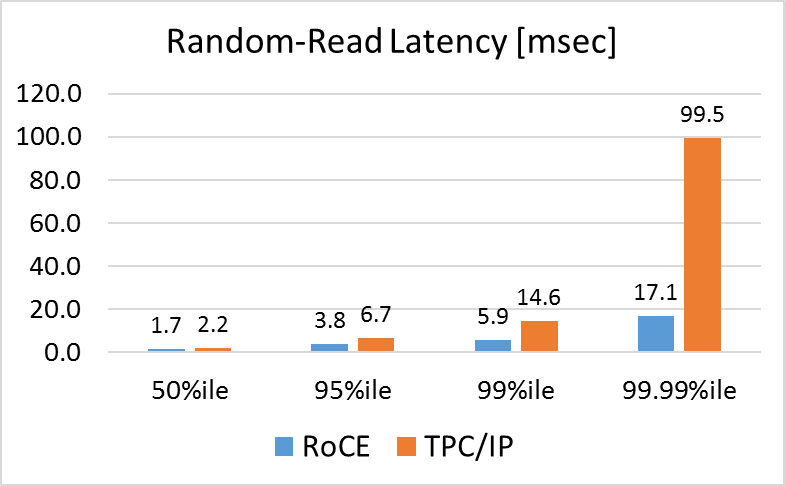
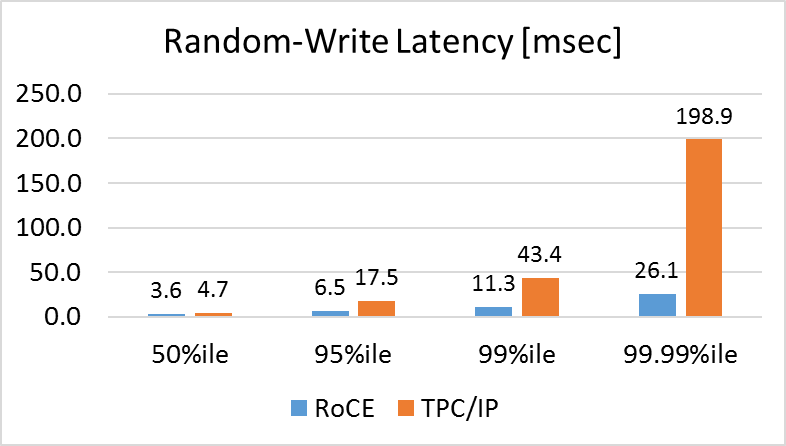
Similar results are measured in both random reads and random writes; in both cases, the results are, of course, significantly worse in cases of TCP/IP, due to heavier usage of the network, but much less in cases of RoCE, due to the fact that the transport is offloaded to the NIC.
Building a next generation datacenter that needs to analyze huge amounts of data requires using a scale-out architecture. In order to provide a consistent response to interactive users or to maximize the overall datacenter efficiency, high performance networking must be used. Compared to plain vanilla TCP/IP, RDMA-capable networks like Ethernet with RoCE are proven to provide superior performance and thus will help cloud and web service providers – and enterprises that seek to emulate them – to achieve their business and operational goals.
Kevin Deierling is vice president of marketing at Mellanox Technologies.


Hyperscalers Set The Pace For 800G Ethernet
The hyperscalers and the largest public clouds have been on the front end of each successive network bandwidth wave for more than a decade, and it only stands to reason that they, rather than the IEEE, would want to drive the standards for faster Ethernet networks. That is why the …
Spectrum-4 Ethernet Leaps To 800G With Nvidia Circuits
When Nvidia announced a deal to buy Mellanox Technologies for $6.9 billion in March 2019, everyone spent a lot of time thinking about the synergies between the two companies and how networking was going to become an increasingly important part of the distributed systems that run HPC and AI workloads. …

Switching Back Into A Higher Gear
If you want to get a sense of what is happening in the high-end of the Ethernet switch and routing market, it is Arista Networks, formerly an upstart and now just one of the bigger vendors taking on the hegemony of Cisco Systems in networking in the datacenter and now …
The interconnect needs in 2018 are vastly different from what they were in 1990. The limitations of the star serial “push” approach (now known generally as switched networks), with control planes that constrain the flow of data rather than promote it, are increasingly evident, and are now constricting the path forward.
The solution requires a complete rethinking of the data transfer problem, resulting in a new and better interconnect, based on a completely different set of concepts. More on this topic is discussed in the following whitepaper: http://lightfleet.com/wp-content/uploads/a-new-way-to-interconnect-computers.pdf
Please note that the Lightfleet high-performance interconnect, is highly deterministic, with no data skew, no jitter, no, dropped packets, and it can multicast just as easily as it can unicast.
Really interesting and easy to digest write-up. Do you know if anyone has looked at the energy efficiency of these two methods?
Tolly Group evaluated energy usage for Lightfleet. You may wanted to review the Tolly Group report on multicast performance at Lightfleet.