

Containerization as a concept of isolating application processes while sharing the same operating system (OS) kernel has been around since the beginning of this century. It started its journey from as early as Jails from the FreeBSD era. Jails heavily leveraged the chroot environment but expanded capabilities to include a virtualized path to other system attributes such as storage, interconnects and users. Solaris Zones and AIX Workload Partitions also fall into a similar category.
Since then, the advent and advancement in technologies such as cgroups, systemd and user-namespaces greatly improved the security and isolation of containers when compared to their initial implementations. The next step was to abstract the complexity involved in containerization by adding user-friendly features such as templates, libraries and language bindings. LXC, an OS container meant to run multiple services, accomplished this task.
In the late 2000s, Docker, an application container that was meant to run a single service, took it one step further by creating an entire ecosystem of developer tools and registries for container images, improving the user experience of containers and making containerization technology accessible to novice Linux users. This led to widespread adoption. The evolving nature of this domain led to the creation of a standardization process called Open Container Initiative in 2015.
Containerization drastically improves the “time to results” metric of many applications by eliminating several roadblocks in the path to production. These roadblocks arise from issues pertaining to portability, reproducibility, dependency hell, isolation, configurability and security. For example, applications in fast-paced growth areas, such as high performance computing (HPC) which include verticals and workloads like molecular dynamics, computational fluid dynamics, MIMD Lattice Computation codes, life sciences and deep learning (DL), are very complicated to build and run optimally, due to very frequent updates to the application codes, its dependencies and supporting libraries.
Container images include the applications themselves and their development environments, which aids developers in porting their applications from their desktops to datacenters. This also helps with version control, making it easier to understand which versions of the software package and dependencies lead to a particular result. This, in turn, helps to manage dependency hell, which refers to the entire application failing if one of its dependencies fails. Another real-world example is collaboration between researchers, where containers help with reproducibility of the results. In short, instead of spending time debugging the software environment, researchers can focus on the science.
Containers are orders of magnitude faster to spin up than virtual machines (VM) since they do not have a hypervisor providing a virtual hardware layer and a guest OS on top of the host OS as an independent entity. For a majority of HPC and DL applications, an un-tuned full VM may experience performance degradation when compared to bare metal. The overhead and performance degradation of a container when compared to an equivalent fully subscribed bare metal workload performance is nonexistent. All of these features have promoted the deep proliferation of container technologies.
Why Singularity
Despite providing a considerable abstraction over the complexity of the container ecosystems that came before it, there are some limitations to Docker that are specific to the HPC and DL space where performance at scale matters. At the outset, the hardware (compute, storage and networking) and software stack architectures that support traditional HPC workloads are very similar to deep learning workloads. The challenges faced by both domains are also quite similar. For deep learning, even though the state of the practice is at a single node level, given the scale at which the available dataset sizes are growing and technological updates to models and algorithms (model parallelism, evolutionary algorithms), it’s imperative that most – if not all – parts of the data science workflow (finalize the model, training, hyper parameter tuning, deploying the model/inferencing) have the ability to scale. Containerization provides the solution here for build once (known optimal configuration) and run at scale.
The first limitation for Docker is the daemon, which needs to run in the background to maintain the Docker engine on every node in the datacenter. This daemon needs root privileges that can be a security concern. These concerns can be remedied through several extra checks that need to be put in place by the sys admins. These are well detailed in the Docker security page. Some of the checks are obvious, such as enabling SELinux along with disallowing users to mount directories outside the docker context, limiting the binding options to some trusted user-defined paths, and checking to make sure that all files written to the file system retain the appropriate user’s ownership rights. However, all this comes with the cost of limiting the useable features in docker.
Typical HPC and DL codes can scale to tens of thousands of core counts, and the compute nodes are fully subscribed. The second gap in Docker today is lack of support for the software stack that aids in this scaling, such as MPI, schedulers and resource managers (Slurm, torque, PBS pro). Native support for graphics processing units (GPUs) is another major concern. Docker containers can be orchestrated through frameworks such as Kubernetes or Docker swarm. However, the scheduling capabilities of Kubernetes as compared to well-established resource managers and schedulers, such as Slurm or torque, are in its infancy. Kubernetes was traditionally aimed at micro services, which could be apt when we consider deep learning inferencing. But for deep learning training, where large scale batch scheduling jobs are involved, it falls short.
Most of the issues mentioned above have been addressed by a new container platform called Singularity, which was developed at Lawrence Berkeley National Lab specifically for high performance computing (HPC) and DL workloads. The core concept of singularity is that the user context is always maintained at the time of container launch. There is no daemon process. Instead, singularity is an executable. Singularity containers run in user space, which makes the permissions of the user identical inside and outside the container.
In default mode, to modify the container, root credentials would be needed. This doesn’t mean the singularity is immune from security concerns. The singularity binary is a setuid executable and possesses root privileges at various points in its execution while the container is being instantiated. Once instantiated, the permissions are switched to user space. Setuid-root programs make it difficult to provide a secure environment. To address this, there is an option to set the container to a non-suid mode. This forces the directories to exist in the image for every bind mountpoint, disables mounting of image files and enforces use of only unpackaged image directories, allowing users to build a singularity container in unprivileged mode.
High performance interconnects, such as InfiniBand and Intel Omni-Path Architecture (Intel OPA), are very prevalent in the HPC space and are very applicable to DL workloads where the applications benefit from the high bandwidth and low latency characteristics of these technologies. Singularity has native support for OpenMPI by utilizing a hybrid MPI container approach where OpenMPI exists both inside and outside the container. This makes executing the container at scale as simple as running “mpirun … singularity <executable command>” instead of “mpirun … <executable>”.
Once mpirun is executed, an orted process is forked. The orted process launches Singularity, which in turn launches and instantiates the container environment. The MPI application within the container is linked to the OpenMPI runtime libraries within the container. These runtime libraries communicate back to the orted process via a universal process management interface. This workflow would be natively supported by any of the traditional workload managers, such as slurm.
Similar to the support for InfiniBand and Intel OPA devices, Singularity can support any PCIe-attached device within the compute node, such as accelerators (GPUs). Singularity can find the relevant NVIDIA libraries and drivers on the host via the ld.so.cache file, and will automatically bind those libraries into a location within the container when the –nv flag is used. The nvliblist.conf file needs to be used to specify which NVIDIA libraries to search for on the host system when the –nv option is invoked. There is a container registry for singularity similar to docker hub. Additonally, a well-defined process exists for converting existing docker containers seamlessly into singularity containers.
Singularity, like any containerization technology, is not bereft of certain universal challenges. Driver conflicts and path mismatches are some of the preliminary hindrances – especially the driver versions for external-facing PCIe devices, such as OFED for Mellanox, IFS for Intel OPA and CUDA for NVIDIA GPUS, since these are kernel dependent. Production and final deployment environment constraints need to be considered when the containers are being built to ease a few of these issues. For applications which are MPI parallelized, if mpirun is called from within the container, an sshd wrapper needs to be used to route the traffic to the outside world. Some of the much needed features which are anticipated from singularity include monitoring performance of containers, checkpoint-restart capability and improved security.
Singularity Performance at Scale
Our research team embarked on a mission to containerize HPC and DL applications for our internal use cases. A few representative studies from the HPC Innovation Lab are shown here. Figure 1 illustrates the performance of the LS-DYNA application, a finite element analysis code in the manufacturing domain. The application here is using the Car2car dataset, which simulates a two-vehicle collision. Each compute node has 36 cores, and the application is scaled out to 576 compute cores or 16 nodes of Dell EMC PowerEdge C6420 Server. The percentage points at the top of each data point in the figure represent the difference in performance between a complete bare metal run versus a containerized run through singularity. The relative performance difference is under 2%, which is within the run-to-run variation.
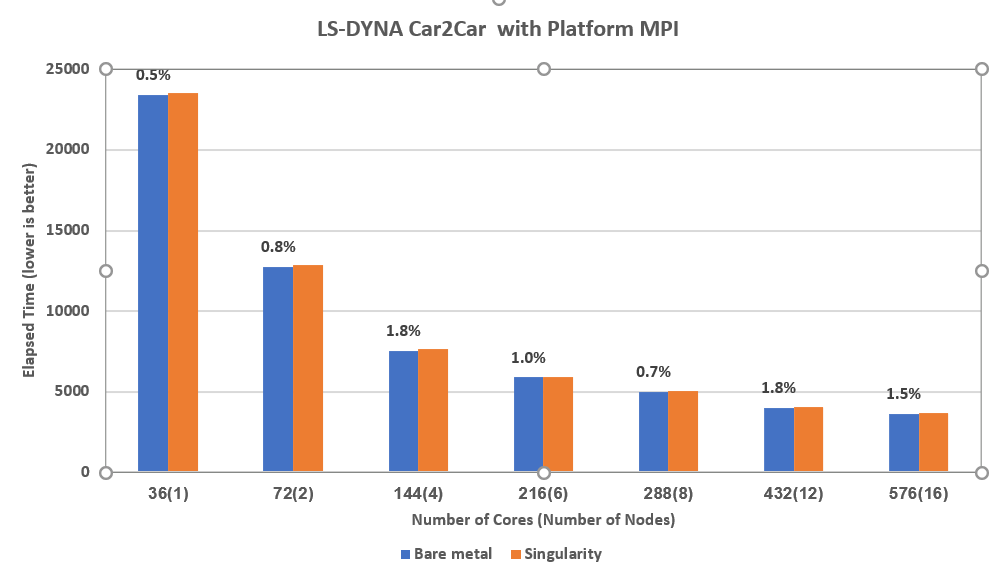
Figure 1 Baremetal vs container at scale for LS Dyna
This behavior is repeated in the deep learning domain as shown in Figure 2. Here, we use 8 x Dell EMC PowerEdge C4140 Servers populated with four NVIDIA Tesla V100s each, interconnected with Mellanox EDR to scale a Resnet50 model through Horovod’s MPI overlay for Tensorflow. The dataset used here is from Imagenet 2012. The performance comparison between a bare metal versus a containerized version of the framework at 32 Tesla V100 is still under 2%, showing negligible performance delta between the two.

Figure 2 Baremetal vs Singularity at scale for Tensorflow+Horovod
Conclusion
Containerization has been a solution for applications that pose challenges to compile and run optimally at scale. It has been a vehicle for collaboration and sharing best practices. Both high performance computing and deep learning workloads can benefit greatly from containerization. Links to some related articles are listed below.
Nishanth Dandapanthula is a systems engineering manager in the HPC and AI Solutions Engineering group at Dell EMC. The Next Platform commissioned this piece based on the uniqueness of the benchmarks and results and its relevance to our reader base.




Be the first to comment