

High performance computing experts came together recently at Stanford for their annual HPC Advisory Council Meeting to share strategies after what has been an interesting year in supercomputing thus far.
As always, there was a vast amount of material covering everything from interconnects to containerized compute. In the midst of this, The Next Platform noted an obvious and critical thread over the two days–how to best map infrastructure to software in order to reduce “computational back pressure” associated with new “data heavy” AI workloads.
In the “real world” back pressure results from a bottleneck as opposed to desired flow through a confined space. In such systems, back pressure is often caused by a tight bend or an unintended obstruction. Considering practical HPC, the huge data sets now needed for AI represent what we can think of as a metaphorical complex flow of matter through a system. High speed offload devices and interconnects accordingly represent a potential for developing “obstructions” or “tight bends”. If not carefully managed, back pressure will quickly result, and the entire system will fail to perform as expected or maybe even at all.
Better communication reduces pressure
With this back pressure in mind, DK Panda of Ohio State opened the Stanford event with an overview of what system designers at scale should architect around massive volumes of data, especially because AI workloads are now all the rage. For those that follow his research, he has been at the fore of solving communication and data bottlenecks for decades with projects like MVAPICH to name just one recent example.
Improvements in communication protocols like those Panda and others across the ever-broadening HPC spectrum have put forth are important so that large data sets can be moved into and out of ever-faster computing devices. At exascale levels, there is the potential to have billions of processing cores all on the go, with each of them trying to talk to both huge object stores and to each other simultaneously.
It’s like trying to shout to a friend across a packed stadium during the super bowl halftime show, which raises an important point. Despite the significant progress made in these protocols…
You need significantly better methods to communicate.
Take for example a data oriented capability supercomputer like SDSC Comet, which weighs in at 1,944 nodes, 212 switches and 4,377 network links. All of those numbers add up to 47,776 compute cores each trying to hit up 7.6PB of parallel storage for input and output while running at full bore. Even finding a single optimal path through this fabric is tough. Add congestion and latency, and it becomes a computational challenge in itself to navigate your data efficiently through the fabric.
Solving for this data movement challenge is the real sharp end of a very large wedge for any exascale capability. Get the network capabilities incorrect, or if you find that your protocols are too heavy and cumbersome, and that’s it. Game over. The talk elegantly stated:
“MPI runtime has many parameters”.
No kidding. Plus the real challenge is that so does absolutely everything else. We are at the point where multiple PhDs can be successfully completed on the topic of guiding the nuances of an array of MPI broadcast events alone. It is critical that this challenge is solved if we are to reach exascale capability for our real world workloads.
VMWare (who also spoke at the meeting) for example, now spin up Direct Path I/O and SR-IOV in their hypervisors as a matter of course. This theme of data driven compute continued throughout each of the presentations. The allure of a seamless and transparent data access with double digit nanosecond latency is the goal here. Carefully planned data access is driving the business requirement to stand up ever more impressive RDMA based Apache SPARK results. This shows it isn’t a simple academic exercise. There is a significant business need to operate on large data systems at scale. The interconnect and protocols are where the details and the core research currently lies in developing more successful, higher performing systems.
All of these issues are compounded by the needs of deep learning and just as seriously by other performance-driven needs like RDMA-based SPARK, for example.
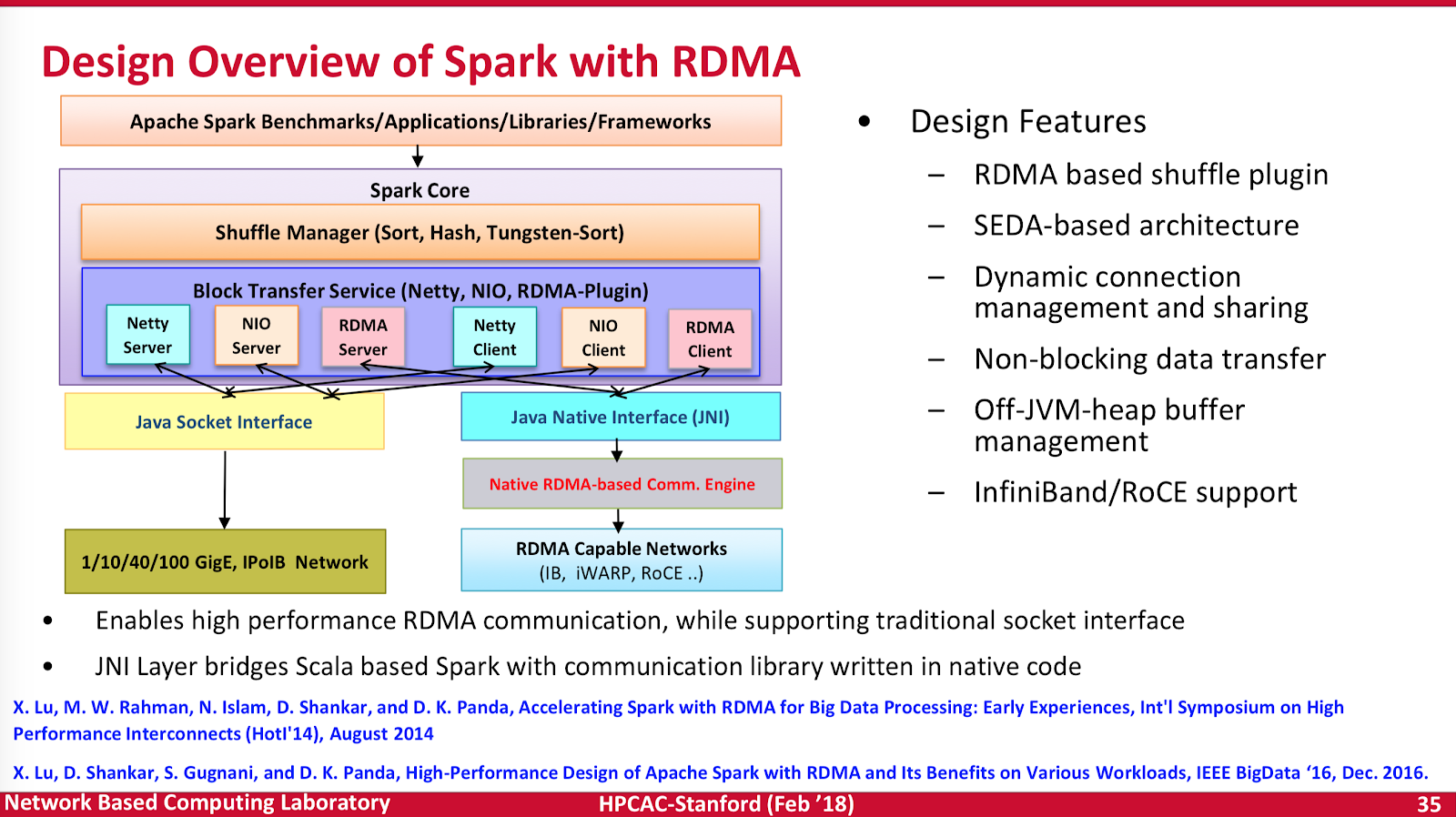
Meshing hyperscale and HPC
What used to be distinct “hyperscale” methods for data management and mobility are now being fully baked into the HPC ecosystem. Interestingly, Intersect360 also spoke at the event and they place AI in the hyperscale market. There’s nothing wrong with that, and they state that albeit similar to, AI is distinct from HPC due to low precision and intense parallelism. We agree, however, the lines sure are becoming extremely blurry, and there is an ever diminishing air gap between traditional “HPC” and “big data” approaches. It is ok to have blurry lines.
Large numbers of software interfaces and stack complexity however continues to be the prominent challenge with each of these approaches. The problem here is there are huge numbers of pieces of moving hardware, network components, software APIs and interfaces. Every interface introduces a degree of latency and delay in the system. Not all protocols can be designed “at wire speed” due to the complexity of the methods. Compromises are needed, but also computational balance is required.
After digging into SPARK and big data, Panda looked to a more evolving workload — TensorFlow and how it might operate on RDMA-gRPC client / server architectures. gRPC is popular with folks like Netflix, and Square who need to stitch together multiple microservices within their environments. Here Panda shows there are up to 30-35% performance improvements to be had right out of the gate by careful tuning and component selection. Another key example of the merging of technologies from hyperscale providers with more traditional HPC approaches. Decreasing latency with FDR and swapping out IPoIB increases performance for small, medium and large messages. Both sigmoid net and CNN were shown to be accelerated with the resnet50 and Inception3 data sets.
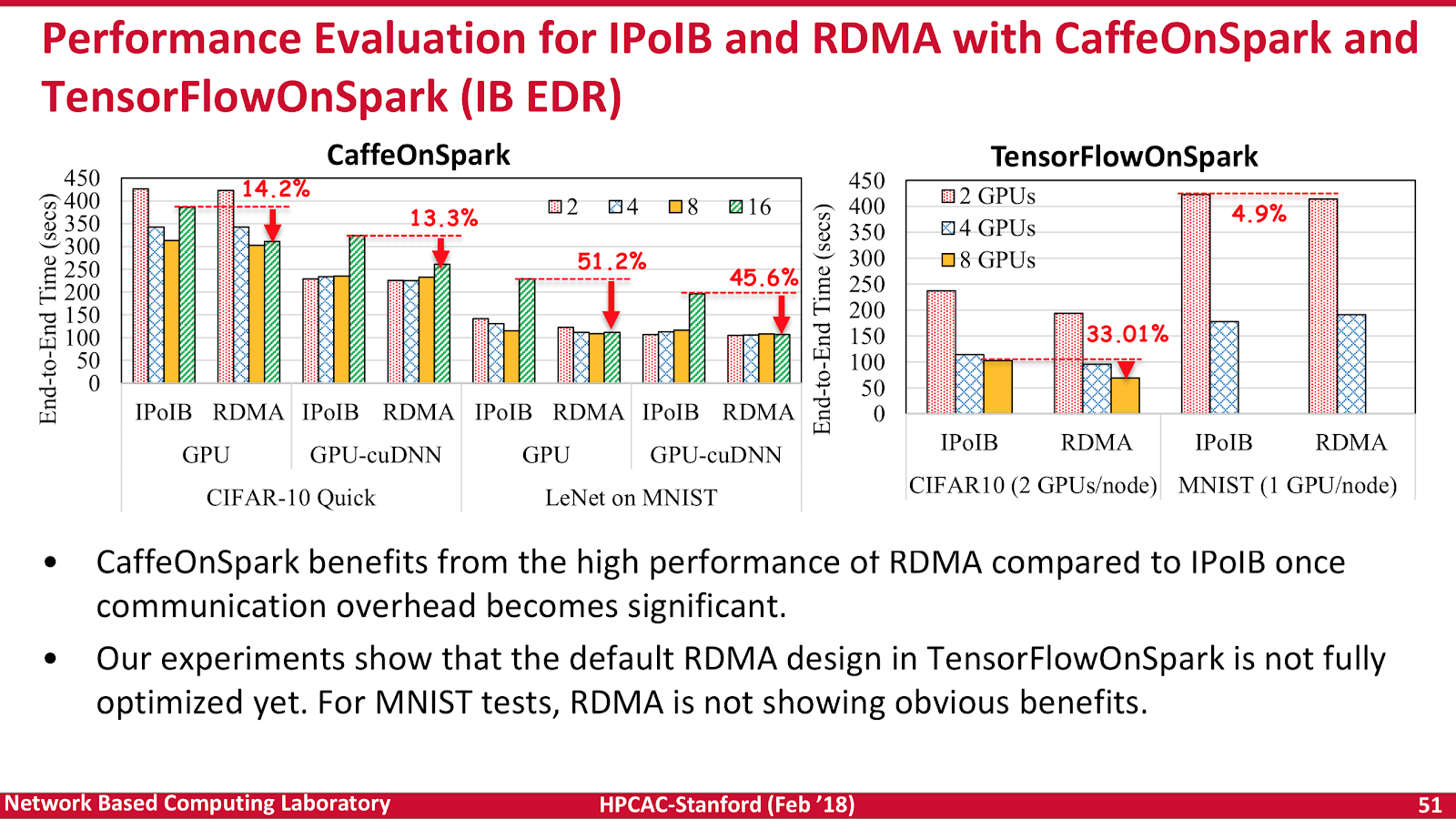
The default RDMA design in TensorFlowOnSpark is clearly faster than IPoIB, but also still warrants even further optimization. This gives great hope in the challenge of data migration onto large multi-GPU servers. These configurations are increasingly needed for AI and machine learning analysis pipelines. The lack of standards in these early neural network methods further compounds the issues, each framework is different, and there are a staggering number of knobs and dials to turn.
Unfortunately, as with everything, for some specific workloads the magic RDMA sauce isn’t quite enough. For example, application of RDMA to MNIST didn’t immediately show any obvious benefits. More work is needed in this area, and once again, one size is unlikely to fit all use cases or workloads. However, the key takeaway was that deploying EDR IB and using RDMA protocols (if your application can muster it), rather than IP over IB is where a lot of the magic currently happens, especially now high GPU count servers are becoming somewhat of a standard unit of issue.
Time to start
A critical issue with orchestrated and containerized workloads now becomes how fast can you physically make your “cloud” actually start up? Until your layered system is fully initialized, no “real” work can happen. This is becoming an increasingly new challenge in HPC as we deploy more efficient workload containerization technologies such as Singularity. Starting your compute container and accessing a shared object store is a new area where additional “back pressure” is now introduced. The “thundering herd” issue of many 10’s of 1,000’s of virtualized workloads all starting at once on 1,000’s of machines can put immense pressure on the storage system performance.
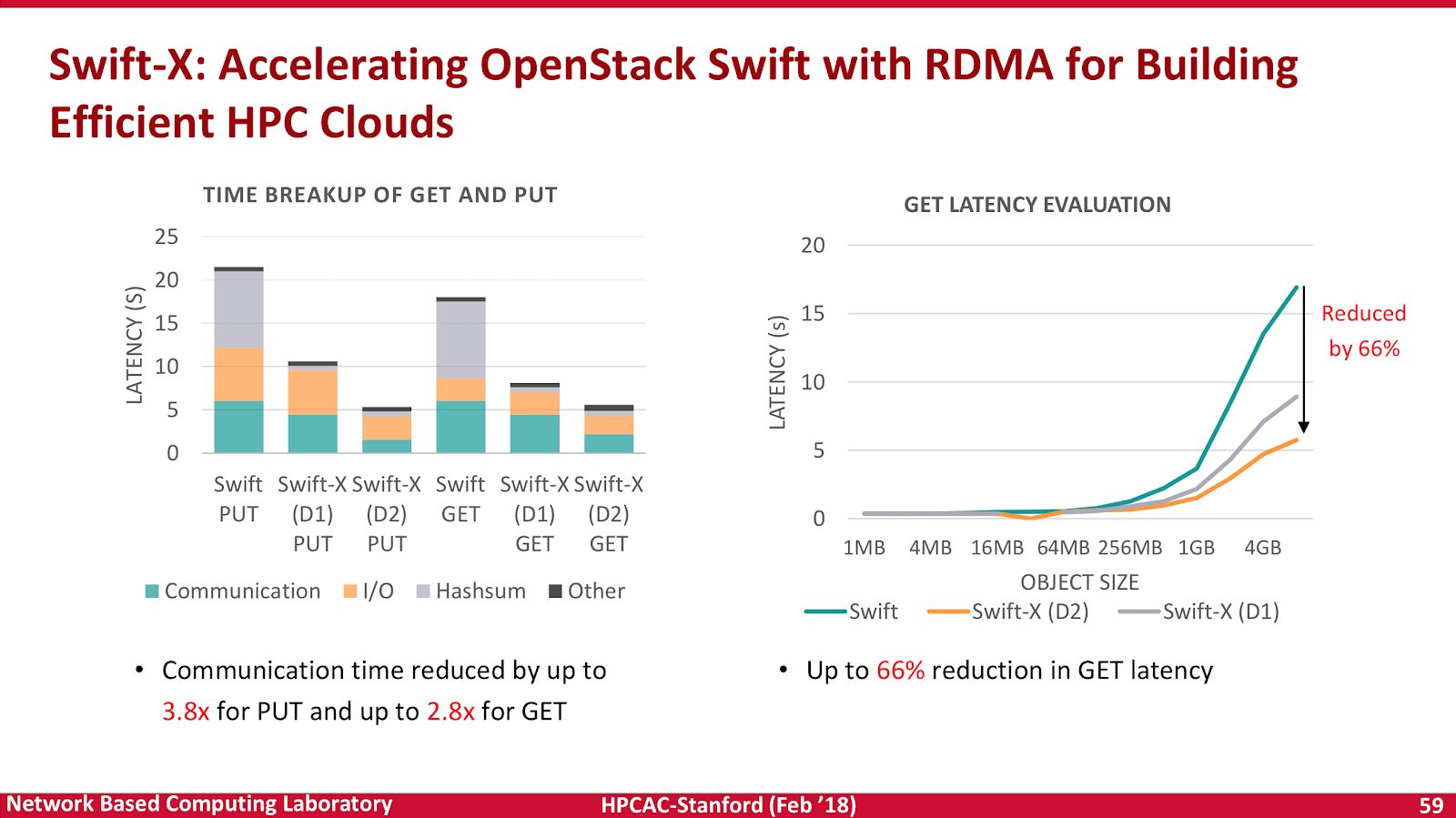
Our trusty RDMA technology enters once again, showing a 66% reduction in GET latencies. Swift-X, an eventually consistent object store was used as the underlying platform. Panda and team notes (as have many before) that data proxy servers are a bottleneck for large scale deployments, and that object upload/download operations are network intensive. Solving for these issues, has a knock on effect of solving for a number of data mobility issues in your HPC cloud.
What does this mean? Basically, it means your cloud will start faster. Much faster. This also means you will get your science and workloads to complete faster. It’s a good thing, we need more of this.
Yet again once we dig into this, the core performance improvements are due to improved and carefully orchestrated paths to the underlying data store. This is another key takeaway trend. If you can map the memory and storage more efficiently, then everything in your resulting pipeline also miraculously becomes more highly performing.
Integration is a critical issue here, the entire stack from I/O request to interfacing with objects is changing. Relying on a monolithic shared file store and traditional fstat(), fopen(), fread() style NFS operations isn’t going to cut it.
This careful attention to understanding “back pressure” by balancing the data path, the algorithms and the object store by looking at how to optimally locate RDMA I/O requests are each attempting to alleviate huge challenges in data localization and compute. These challenges become more important as we increase computing element count. Borrowing technologies and merging ideas between sectors such as web scale and HPC are where the truly significant gains are going to be realized.
In summary
To succeed in modern advanced AI, and for that matter, real-time analytics or rapidly spun-up cloud environments, it is not enough to just know the algorithms, but also to design frictionless pipelines and communication systems that do not create back pressure in your underlying network and systems.
However, the heavily constricted width of the pipeline of qualified engineers and scientists available today that can actually do any or all of this work is where the real world “back pressure” currently lies.

Be the first to comment