

Neural networks live on data and rely on computational firepower to help them take in that data, train on it and learn from it. The challenge increasingly is ensuring there is enough computational power to keep up with the massive amounts of data that is being generated today and the rising demands from modern neural networks for speed and accuracy in consuming the data and training on datasets that continue to grow in size.
These challenges can be seen playing out in the fast-growing autonomous vehicle market, where pure-play companies like Waymo – born from Google’s self-driving car initiative – are competing with tech vendors like Uber and Lyft and traditional car makes like Ford and GM to create the software and algorithms to make autonomous cars as reality.
But before this can happen, there has to be the computational power in place to train the neural networks on a large scale that will drive the machine learning capabilities that will allow the vehicles to drive without human intervention in any kind of weather, night or day, and in any environment – the highway or city streets – all the while recognizing everything from a pedestrian and another vehicle to buildings, traffic signs and intersection lights.
This is going to take more than a single system driven by GPUs or CPUs, according to Adam Grzywaczewski, deep learning solution architect at Nvidia. It’s going to take clusters of systems to deliver the kind of compute power needed to address the needs of increasingly hungry neural networks that are being used in a broad range of industries. The self-driving car space is a good example of the need for distributed neural network training at scale. The graphic below illustrates the need for more computational power.

“To achieve this level of performance, neural networks need to be trained on representative datasets that include examples of all possible driving, weather, and situational conditions,” Grzywaczewski says. “In practice this translates into petabytes of training data. Moreover, the neural networks themselves need to be complex enough (have sufficient number of parameters) to learn from such vast datasets without forgetting past experience. In this scenario, as you increase the dataset size by a factor of n, the computational requirements increase by a factor of n2, creating a complex engineering challenge. Training on a single GPU could take years—if not decades—to complete, depending on the network architecture. And the challenge extends beyond hardware, to networking, storage and algorithm considerations.”
GPUs, with their parallel computing capabilities, are a workhorse in the training and inference of neural networks, and Nvidia has made machine learning and deep learning a central part of its strategy going forward, and self-driving cars a key growth area. Such efforts mirror initiatives underway with rival chip makers, such as Intel and its work to expand the capabilities of its x86-based CPUs. Nvidia offers its DGX-1 appliances based on its Volta GPUs, which the company says gives it the computational performance of the world’s fastest supercomputers from 2010. However, while that isn’t enough to address the needs of neural networks in the autonomous vehicle space, the DGX-1 can be the foundational building block for clustered solutions that can meet those needs.
Running through calculations, Grzywaczewski made estimates about everything from the size of the average fleet of self-driving cars for a company like Waymo and amount of data after preprocessing that needs to run through the neural network to the size of the engineering team needed to support the effort, the amount of training on a single eight-GPU DGX-1 Volta system and the number of such systems needed to hit the training time target of seven days.
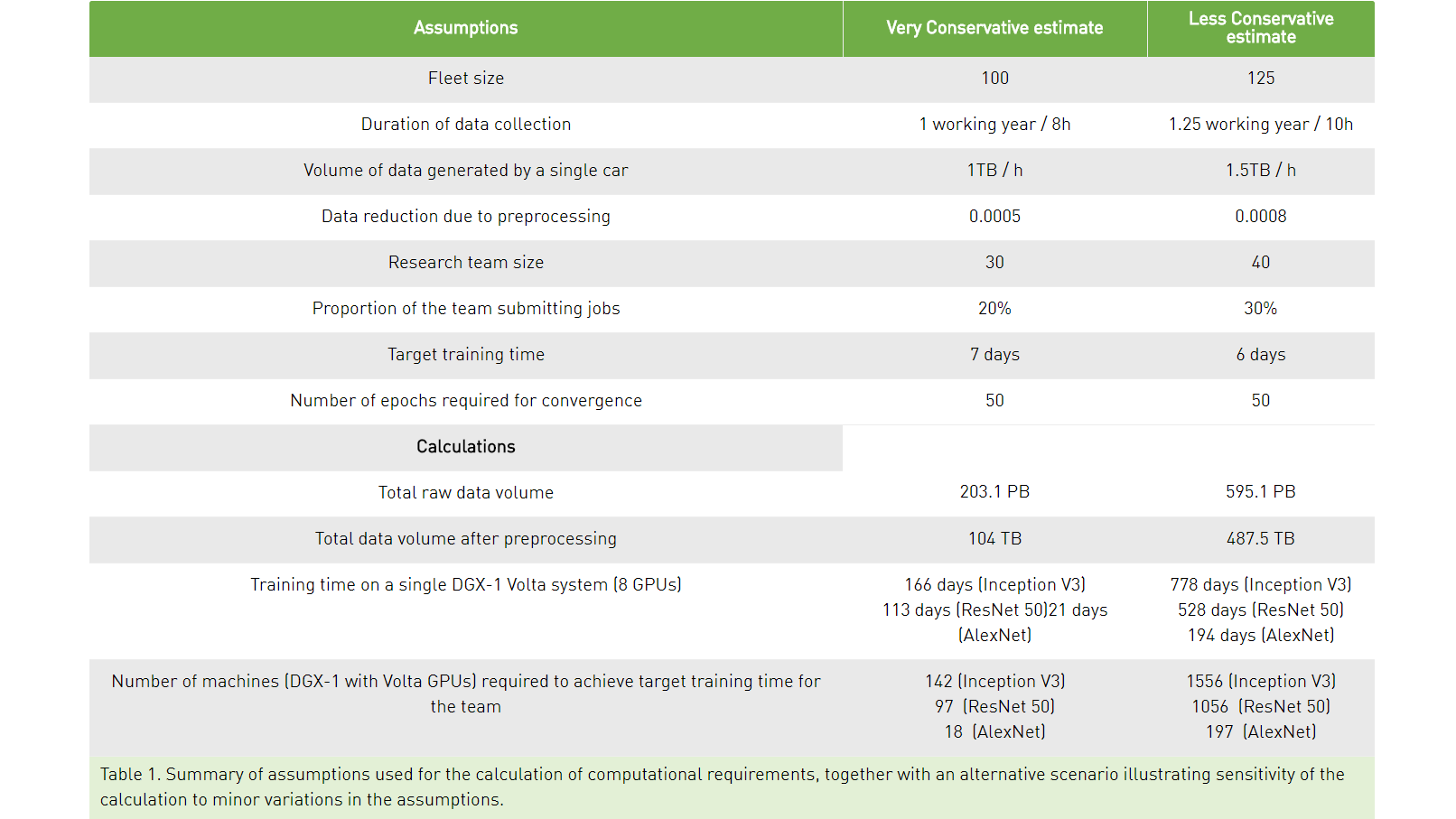
Also of note is that scaling means more than just adding more GPUs. For example, without the right networking, the additional chips won’t be able to drive the performance scaling that’s needed for these modern neural networks. Not surprisingly, Grzywaczewski points to Nvidia’s NVLink and its 300 GB/s bidirectional bandwidth for faster communications within a single multi-GPU system, as shown below:
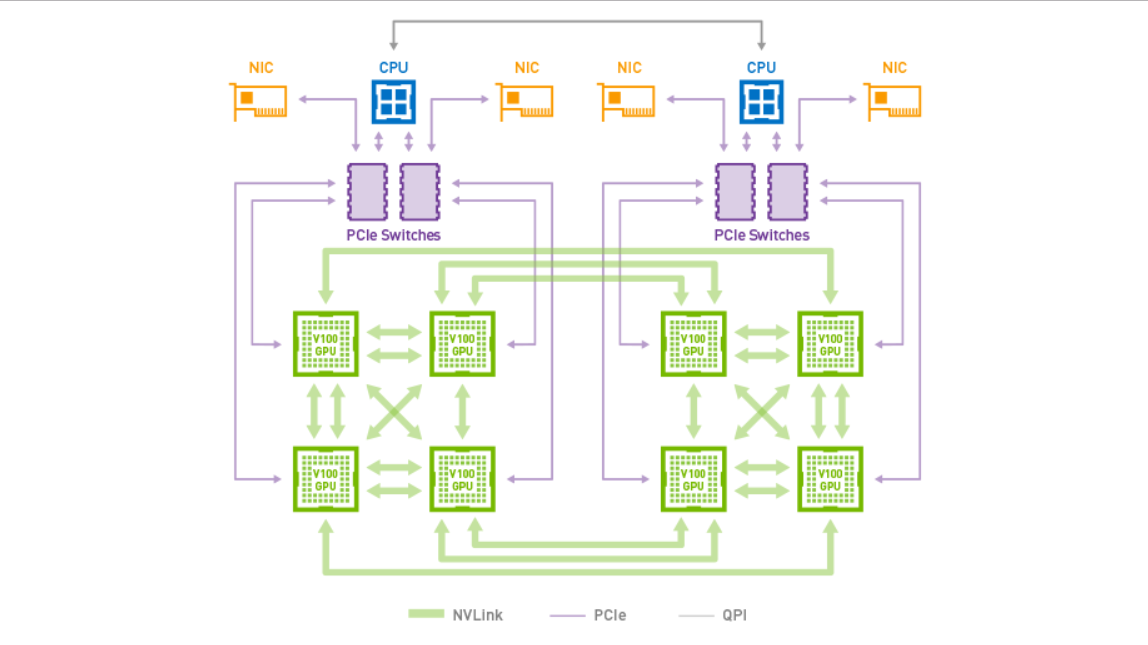
In a multi-node connection, he points to InfiniBand, as seen in the network topology below:
Algorithms, software, storage (where for such complex challenges like with self-driving cars Grzywaczewski is seeing more deployments of flash storage or flash-accelerated storage), and CPUs and memory also play critical roles. In addition, he noted that computational power is needed for all stages of developing and testing an automotive AI model.
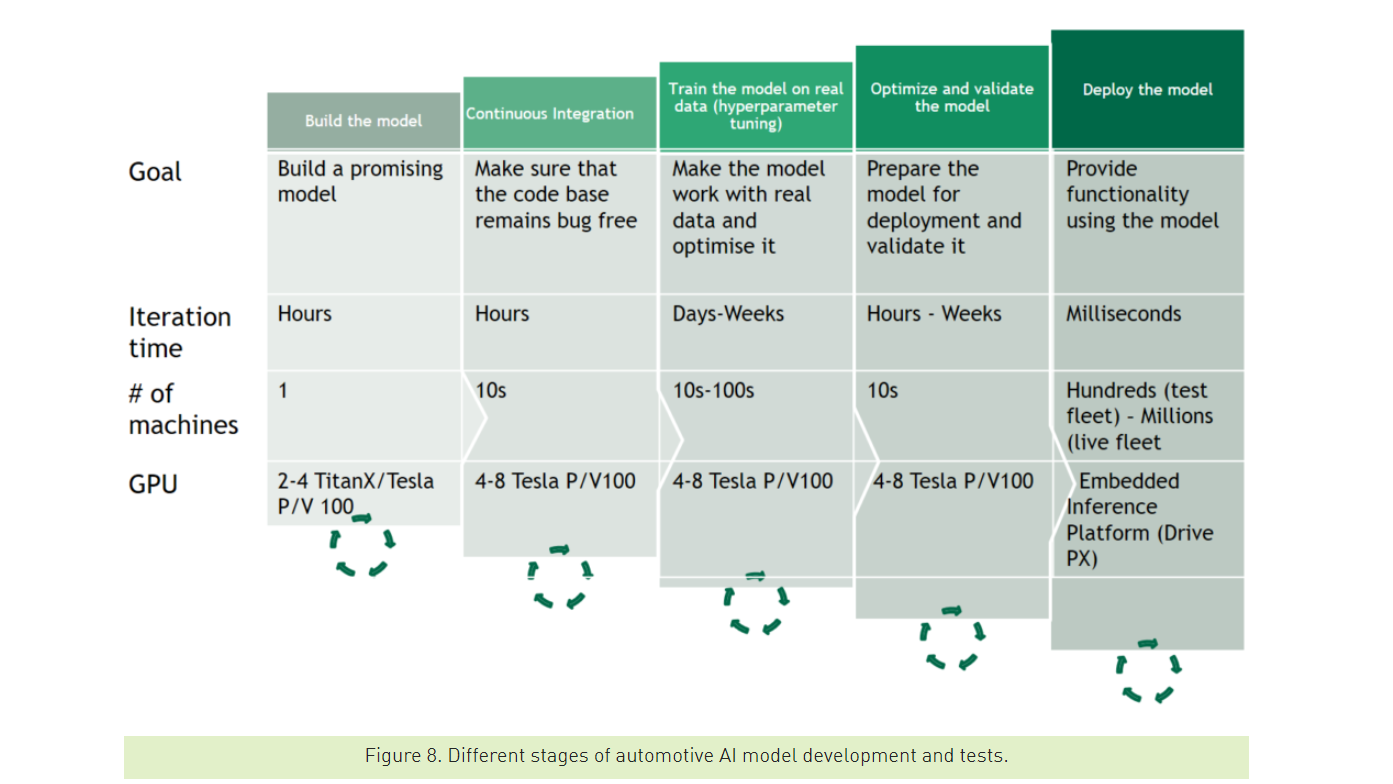
“The computational requirements of deep neural networks used to enable self-driving vehicles are enormous,” Grzywaczewski wrote, noting that “self-driving car research cannot be carried out successfully on a small number of GPUs. Even with a device as powerful as DGX-1 with Tesla V100 GPUs, a single training iteration would take months when dealing with a 100TB dataset. There is no way of escaping large-scale distributed training. Building this infrastructure, as well as the software to support it, is non-trivial, but not beyond reach. For the first time in human history, we have enough computational power for the complexity of autonomous vehicle training.”

Deutsche Bank Tag Teams With Nvidia On Financial Services AI
In many industries, embracing AI in the application software stack it is not just a matter of training some large language models or recommender systems against general and then specific datasets and plugging it in. And in any regulated industry – particularly financial services because it deals with Other People’s …

Eni Chooses Utility Pricing For New HPC4+ Supercomputer
Here are two things you don’t see every day in the realm of scientific and technical high performance computing. The first thing is seeing an organization upgrade an existing system after it has already had its successor plopped down in the datacenter next to it. And the second thing is …

Dell Gives A Second Opinion On Enterprise IT Spending
Like many of you, we are trying to find out what the heck is really going on in the global economy. And as such, we are paying particularly close attention to the original equipment manufacturers, or OEMs, who peddle servers, storage, and often switching into the enterprise. They are leading …
Be the first to comment