

File systems have never been the flashiest segment of the IT space, which might explain why big shakeups and new entrants into the market don’t draw the attention they could.
Established vendors have rolled out offerings that primarily are based on GPFS or Lustre and enterprises and HPC organizations have embraced those products. However, changes in the IT landscape in recent years have convinced some companies and vendors to rethink file servers. Such changes as the rise of large-scale analytics and machine learning, the expansion of HPC into more mainstream enterprises and the growth of cloud storage all have brought new challenges to file servers, which have become increasingly complex and more difficult to manage.
Changes in the business environment for parallel file systems also have put a greater focus on GPFS and Lustre. In particular, Intel in April 2017 shut down its efforts to sell a commercialized release of Lustre, though the giant chip maker will continue to have engineers working on Lustre. But the decision by a such a high-profile proponent raised questions about the future of Lustre.
In the middle of all this has been the rise of another parallel file system – BeeGFS – aimed at the HPC space. Begun in 2005 by Fraunhofer Center for High Performance Computing in Germany to in-house in a computer cluster at the institution, the technology began a rapid ascent that saw the first beta version run out in 2007 and the first major release a year later. It was commercialized in 2009 and in 2014, Fraunhofer spun out a new company, ThinkParQ, to expand its reach in the commercial market. Originally called FhGFS, the file system at this time was given the name BeeGFS. The goal of ThinkParQ is to bring the open-source and free software to organizations of varying sizes and offer everything from support and consulting to events and partnerships with system integrators to develop solutions that include BeeGFS. Much of the development of the parallel file system software remains with Fraunhofer.
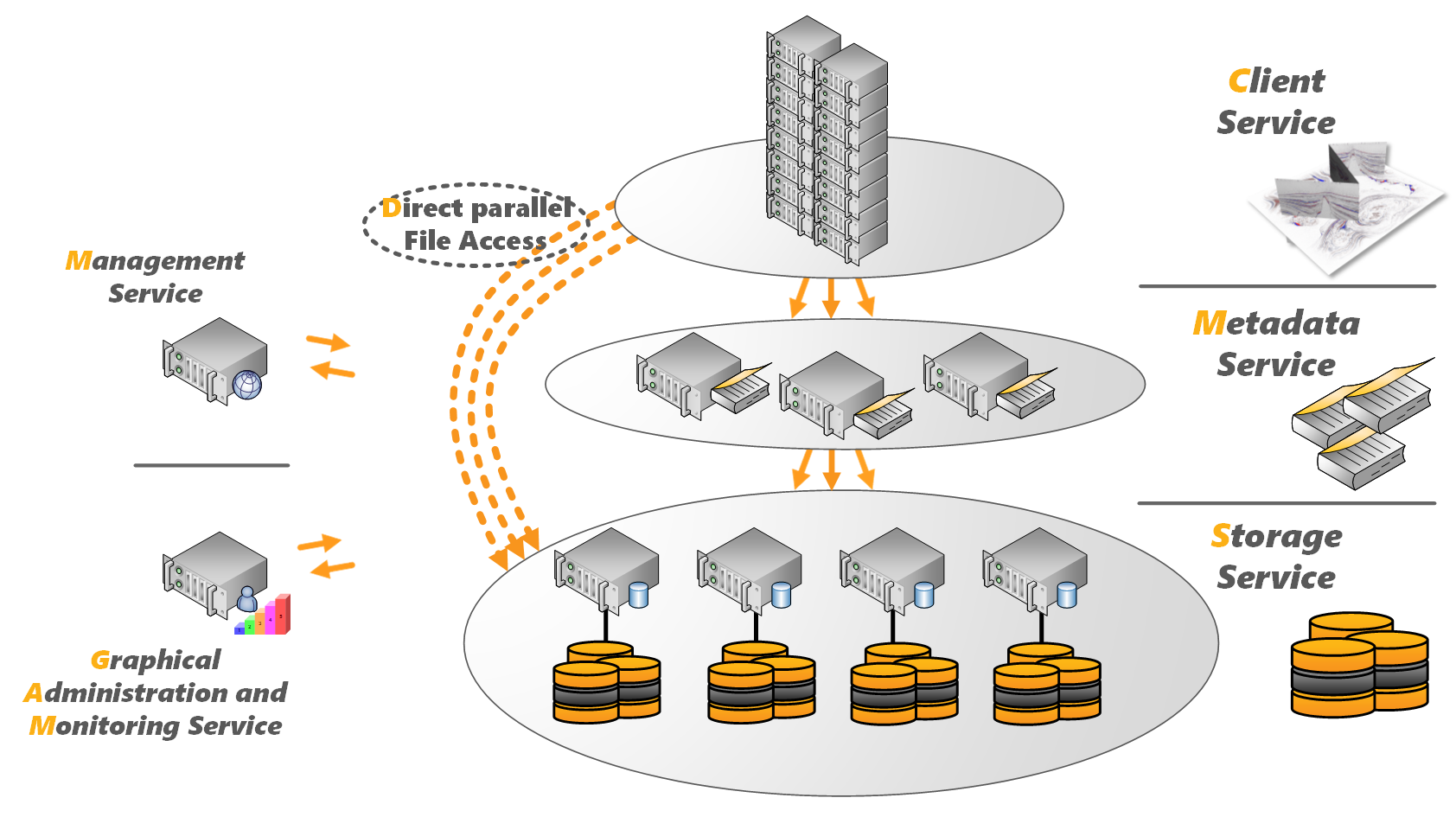
Throughout 2017, ThinkParQ and BeeGFS developers made strides in several areas, including expanded partnerships with the likes of cluster management software maker Bright Computing, HPC solutions provider Penguin Computing, and hardware makers Ace Computers and Quanta Cloud Computing, continued growing beyond Europe in such areas as Russia and Japan, and the release of BeeGFS v7.0 at the SC17 supercomputing show that included new storage pools that can combine different devices like SSDs and HDDs and enable users to have more control over where their data is placed. In Japan, Fujitsu announced that its upcoming AI Bridging Cloud Infrastructure (ABCI) supercomputer will use BeeGFS-on-Demand (BeeOND), similar to the Tsubame 3.0 system built by Hewlett Packard Enterprise that went online last year. The system uses BeeOND on compute notes for a 1PB NVMe burst buffer at 1TB/s, according to ThinkParQ.
The company is seeing increased interest in BeeGFS for a number of reasons, from the need for a easier to use and more robust option in the market to the concerns about Lustre and its future, according to Sven Bruener, CEO of ThinkParQ and BeeGFS lead at Fraunhofer. It has helped the company and technology gain traction in a market with competition from well-established vendors offering products based on time-tested parallel file systems.
Intel’s decision to abandon its Lustre commercialization efforts “has led to a large number of discussions with partners who are interested in using BeeGFS for a kind of Lustre replacement program because they are unsure of the future of Lustre now,” Bruener told The Next Platform. “It is way to go for many people to go because unlike with Lustre, BeeGFS has its roots in the HPC world. People know that when they use BeeGFS, they get something that is not optimized for tons of features, but mostly for performance, which is important for many [HPC] use cases.”
The CEO said he is seeing organizations gravitate to BeeGFS from GPFS and Lustre systems because of the declining performance of some workloads on those file systems. Some of those problems are related to the underlying architecture, such as access to data in many compute nodes. In addition, BeeGFS is easier to use and requires less maintenance.
“Our idea is that the file system is just a tool to get the job done,” Bruener said. “You should not have to worry about the tool. It should just go its job, like a hammer. You don’t want to worry about the hammer. The hammer is just to hammer something, and that is the idea behind BeeGFS. Kind of a higher-end forget approach. Most of them are actually switching from other systems like Lustre and GPFS because they run into issues and then they start trying out other systems. They’re surprised how easy [BeeGFS] is to set up and how well it performs right out of the box. That is either capability or performance. They notice that in the beginning, their file system was performing quite well, but after a while it no longer performs so well.”
Scalability also is a differentiator, according to Marco Merkel, global sales consulting director at ThinkParQ.
“The flexibility of BeeGFS is really so enormous that you really can start with two servers and then you can just add components on the fly,” Merkel said, saying it can be compared with Panasas and its PanFS file system, but “it absolutely hardware-independent. It brings us into a position the vendors [like IBM] are also recognizing BeeGFS in the market They found out they can sell more hardware controllers [by] adding BeeGFS compared to GPFS, because GPFS is very complex and can be more expensive. For the solution set, this BeeGFS in that kind of environment and that’s the flexibility. … With BeeGFS, you can start very small with less components, but if you are growing, you just need to add the components by capacity or performance requirements. That’s the differentiator, because the architecture is so flexible that is can work in any kind of environment. There’s really no technical limitation. BeeGPS is ready to start very small and from the perspective of scaling, it can scale into exabyte level.”
While much of the action for BeeGFS now is in Europe, the company is seeing growth in other regions, not only Russia and Japan but also the United States, where the are about two dozen installations in places like Oak Ridge National Lab and with oil-and-gas companies, Bruener said. ThinkParQ has customers in the 10PB range, including in the bioinformatics space, and some like the University of Vienna with a couple of thousand nodes.
BeeGFS came at a time when other big vendors were supporting other long-established file systems and some companies that developed their own file systems were struggling to grow. Merkel said BeeGFS addresses the needs of a changing market.
“If you look at the history, GPFS is coming up to 25 years ago and was more focused on data management and Lustre has been developed … 17 years ago as kind of a pilot project to have aggregated throughput on it, and 15 years ago, SSDs didn’t exist, and they couldn’t know what would be demanded of future storage environments and the scalability [that would be] necessary, but the development approach was of a different level,” he said. “But [BeeGFS developers] learned the restrictions and they understood the limitations and they also saw the movement of the market and the demands of the market. They customers do require a hardware-independent software solution that gets out the full benefits of the components and then grow the environment by ease-of-use with no specialists required.”
Being easier to use and faster deployment are key differentiators for BeeGFS.
“For the magic behind this system, we are using a kind of BeeGFS demon which is sitting in a user’s space of a Linux system above the local file system, and that makes it very, very flexible because usually if you are setting up an HPC environment, you need a dedicated metadata server, you need storage server components,” he said. “BeeGFS has the flexibility so you can connect the BeeGFS component directly to the storage node. You can also set up all the file system instances. Other people call it ‘burst buffer,’ we call it BeeGFS-on-Demand, which allows you to use them to avoid nasty IO patterns on your existing HPC environment to avoid that stuff, because if you run a data set … and you have long-term computation on your HPC environment, that wouldn’t fit into IO patterns. But maybe you have SSDs available and you can use BeeGFS-on-Demand so you can do that automatically and you light up this approach and use it as a burst buffer kind of technology, and that works very fast.”
Bright Computing has been working with BeeGFS for about a year, though some of its customers have been using the file system for longer than that. Bright has kept in contact with BeeGFS engineers for several years, and told them that Bright would adopt BeeGFS once there was enough demand for it, according to Bright CTO Martijn de Vries.
“The threshold has been reached,” de Vries told The Next Platform. “Our partners have been talking to us about BeeGFS, our customers have been talking to us about BeeGFS and we finally said, ‘It’s not so much of an effort to attract, so we should go ahead and do this and make it super-easy to deploy this BeeGFS on top of a Bright cluster and go the extra mile in health-checking BeeGFS and monitoring BeeGFS, so why not go ahead and do it?”
Bright also works with GPFS and Lustre parallel file systems, and doesn’t recommend one over another to its customers. However, “we do have experience with GPFS and Lustre and BeeGFS and we found BeeGFS to be the most lightweight,” de Vries said. “It really is easy to install. Even without our integration, it isn’t as tricky as Lustre and GPFS and I’m glad to say we’ve made it even easier now with our integration.”

You Want HPC And You Want Virtualization? Let’s Talk About It
HPC architects have continued to push the bounds of what is possible with computing, but the underlying architecture they have used has been fairly consistent – bare metal servers, which get bigger and faster over time. While their colleagues in enterprise computing have been exploiting virtualization for years, the HPC …

Nvidia Adds Cluster Management To Its Enterprise Stack
Chip maker Nvidia might be best known for its graphics and datacenter compute engines, but the company has made no secret of its aspirations to be a bigger player across the datacenter. And not just in hardware, but in software, too. To that end, Nvidia has acquired Bright Computing, for …
Making HPC And AI More Accessible To Enterprises
For more than a decade, as they have watched the amount of data they are generating stack up and technologies like artificial intelligence and analytics come to the forefront, enterprises have turned an eye toward high performance computing equipment and tools to help them get a handle on all of …
BeeGFS has already been deployed by several integrators for Top500 machines for years, e.g. Megware and DALCO. As a parallel file system it is okayish, but has its problems. Actually you want a file system to be old because it takes at least ten years to shake all the bugs out of it. I’m on a technical advisory board for ten large HPC clusters (four of them currently in the Top500, one in the Top 20). Eight use Lustre, two 600-node clusters use BeeGFS (one with OmniPath). Those two BeeGFS installations have completely dominated our bi-monthly status meetings since they’ve been installed. Random lockups, random speed variations, problems when the storage systems become too full, etc. At one point a whole parallel file system became unresponsive and ThinkParQ had to fix it. BeeGFS is an open source product, but you absolutely need a support contract to keep it running in production environments.
The funny thing is that every time our colleagues report a new BeeGFS issue, our Lustre admins smile and say “Ah, that specific problem reminds me of Lustre five years ago”. And they are right. Personally I would wait for another five years until I start thinking about replacing Lustre, except if I absolutely needed a feature or the appliance manufacturers like DDN dropped Lustre.
Interesting opinion … We use BeeGFS in bioinformatics simplly because it’s the only thing that works. Majority of our files are less than 32K in size (yes, K, not M), we even have a couple of millions of empty files (and users tell me they’re important). For lustre to work in such environment one would need to go with burst buffers and related expensive storage but we run BeeGFS on off-the-shelf Dells.
Something on my whishlist for some time now is a decent cgroups implementation for limiting both iops and bandwidth for network attached file systems. Shared filesystem IO is the only shared resource “running wild” that HPC admin has no control over and it is entirely possible for a single user to bring the whole thing down to a halt. Something like this would need to get the kernel people, hpc filesystem people and hpc scheduler people together in one room for a week or so and I’m sure the outcome would be something brilliant.
Well, you should ask them to pack all required functionality in a docker container, some sort of minio.io
Worse is better.
For all of its limitations, HDFS is the dominant filesystem for “big data” because its reliability is up there with cockroaches and porcelain toilet bowls. Three times replication might be wasteful, but it means your system will not be alive but will be exuberant after a massive degradation event.
No matter how efficient a parallel filesystem is, you will curse it forever if you have operational problems. That’s why the world likes boring filesystems.
HDFS is far from boring, and HPC IO requirements vary from “Big Data” requirements..
Your observations (“No matter how efficient a parallel filesystem is, you will curse it forever if you have operational problems”) are your personal thoughts, not a fact.
Lustre & GPFS, once up, can run stable for years, unless some major outage.
Plenty of customers with such configuration, and good tools to analyze & fix if issue appear.
Lustre was behind on that, but ca
ught up in the past couple of years.