
All the shiny and zippy hardware in the world is meaningless without software, and that software can only go mainstream if it is easy to use. It has taken Linux two decades to get enterprise features and polish, and Windows Server took as long, too. So did a raft of open source middleware applications for storing data and interfacing back-end databases and datastores with Web front ends.
Now, it is time for HPC and AI applications, and hopefully, it won’t take this long.
As readers of The Next Platform know full well, HPC applications are not new. In fact, they were created alongside commercial applications more than six decades ago at the birth of commercial electronic computing, often on specialized gear designed to do complex mathematical calculations instead of counting money and running transactions. These early HPC applications, usually coded in Fortran, were on their own cutting edge, and they allowed scientists to simulate all kinds of physical and chemical processes, all of which leads to a better understanding of the world around us and the wider universe and often to create better products to enrich our lives or defend them. While HPC applications have been around for a long time, no one would ever call HPC easy. And if simulation and modeling of all kinds, augmented by machine learning, is to get easier, then it is going to have to get easier to install, update, and manage traditional HPC and new AI applications.
To that end, Nvidia, which has the most at stake in the GPU revolution that is sweeping both HPC and AI, is investing heavily in making it easier to deploy these applications. At the GPU Technical Conference in May, the company previewed its Nvidia GPU Cloud, which is not actually a compute cloud as the name might suggest to some, but rather a free repository of CUDA-enabled software that is prepacked to help speed the deployment of applications. This initial Nvidia GPU Cloud, which was opened up for general use in late October, had a cloud-based registry for containerized frameworks and application images for machine learning that is used to keep the DGX-1 appliances up to date; it could also be used to deploy application images and maintain them out on the Amazon Web Services cloud, with other clouds soon joining the fold, according to Buck. It can also be used to deploy images to on-premises Nvidia DGX-1 systems, or to other ceepie-geepie machines with some tweaking.
At the recent SC17 supercomputing conference in Denver, Nvidia co-founder and chief executive officer Jensen Huang unveiled a new branch of this cloud registry that will be focused on traditional HPC applications to try to grease the skids on using such technologies in the enterprise. The HPC industry has been lamenting the high bar that HPC applications have in being deployed in commercial settings, where there are not essentially free graduate students or researchers who want to do science that are willing and able to spend weeks setting up HPC applications for simulation and visualization on clusters. With the Nvidia Compute Cloud, the HPC stacks – like the AI stacks – are all wrapped up in Docker containers and can be deployed wherever a Linux platform is exposed.

For now, the Nvidia GPU Cloud is targeting the top fifteen HPC applications for the registry and container service, which represent 70 percent of HPC workloads deployed, and is starting out with the NAMD and GROMACS molecular dynamics and the Relion electron cryo-microscopy applications, with more to follow. Buck says that Nvidia will do all of the quality assurance and testing on the codes added to the cloud registry and will validate it on DGX-1 systems using both “Pascal” and “Volta” generations of Tesla GPU accelerators as well as on the public clouds that make use of these devices. The open source community is encouraged to create containers for their HPC and AI applications and work with Nvidia to test them and then get them posted on the registry, too.
With this approach, regular enterprises as well as academic and government supercomputing centers will have the kind of containerized, automated application deployment that Google, Facebook, and other hyperscalers have deployed more than a decade ago. This is one case where hyperscale software techniques are being adopted for the betterment of HPC, and a company like Nvidia, which stands at the intersection of the two and which understands accelerated computing better than any company on earth, can help a great deal. Besides, Nvidia would have had to do all of this itself, or wait for HPC software makers to realize they needed to do it and then create compatible container environments. If Nvidia wants to keep the GPU acceleration wave building, it is just easier to drive this containerization and support itself, and it is enlightened self-interest to do this packaging for free. This will also help the commercial HPC application providers, who might actually made inroads into the “missing middle” of enterprise customers who have not adopted HPC technologies because they do not have the expertise to set up and maintain the codes.
“This is a call to action to the HPC community that as they containerize their applications, Nvidia is happy to host and test their applications,” says Buck.
Nvidia has set up a bunch of virtuous and now overlapping cycles, first tying accelerated computing for HPC workloads to its core professional and gaming graphics engines, and then AI researchers grafted machine learning onto the same iron.
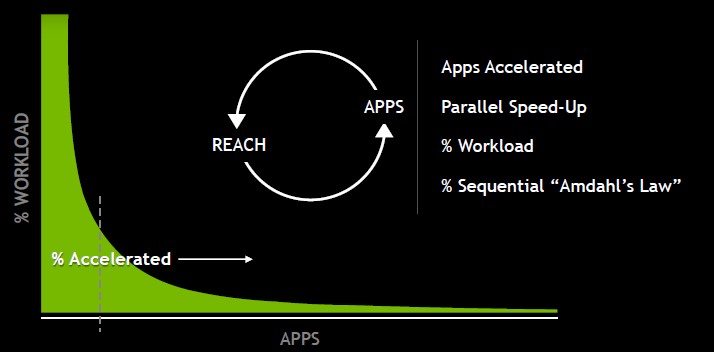
“One of the most important things with any computing architecture is accessibility,” Huang explains. “If it is not accessible, then obviously people cannot develop for it. If it is not abundantly accessible, if it is not literally everywhere and provided by every computer maker in the world, then developers are reluctant to adopt that architecture because in the final analysis developers want to expand their reach. With the reach of Volta, developers are now accelerating their adoption of our architecture and Volta is taking off.”
All of the major server OEMs and ODMs had Volta accelerators in their systems by September, in either PCI-Express or SXM2 form factors, and AWS announced its P3 instances a month ago. And at SC17, Microsoft previewed its NCv3 instances based on the Tesla V100 accelerators. The NCv2 instances based on the Tesla P100 accelerators will be generally available on December 1 and so will be the ND instances, which are based on the Tesla P40 cards and which are aimed more at machine learning inference than deep learning training or HPC simulation. (We will be doing a cross-cloud analysis of GPU computing soon.)
Of course, simulation and modeling is only one key aspect of HPC. Human beings need to see things to understand them, so visualization of what has been simulated and modeled is key. Every supercomputer, in essence, has its own frontal lobe, and these days, visualization is being done in situ on the same iron that is hosting the simulation. To that end, Nvidia is working with ParaView, the maker of the eponymous HPC visualization software stack, to integrate with Nvidia’s IndeX volumetric rendering, OptiX optimized ray tracing, and Holodeck VR immersion technologies to make all of this accelerated by the GPUs and available in the Nvidia GPU Cloud. This containerized ParaView stack with Nvidia plug-ins is in early access now. Nvidia has also packaged up its physics engines used in gaming systems, called Engine Bridge, and packaged up with the ParaView visualization stack, replacing the homegrown OpenGL system that ParaView created with one that is highly tuned for Tesla accelerators.
What this all means is that you can do real-time models with real-time visualization with real-time shadows, all on the same machine. Generally speaking, about 80 percent of the compute will go for the simulation and 20 percent for the visualization, so there is 20 percent growth in Tesla sales right there.
This visualization integration will also help drive the GPU business, particularly now that the entire visualization stack, including the GRID virtualized GPU card firmware, is running on the Tesla accelerators. In fact, there is not going to be a Pascal or Volta variant of the GRID remote virtualization cards, we are told by Nvidia. It is Tesla accelerators doing all the work from here on out.
Stacking Up The Apps
The Nvidia Tesla catalog now has over 500 HPC and AI applications that have been tweaked to support CUDA and offload parallel work to GPU accelerators. Most of those codes are traditional HPC applications to do simulation and modeling, but there are also a number of AI frameworks and applications in the mix, Ian Buck, vice president of accelerated computing at Nvidia, tells The Next Platform. It is hard to say for sure, but Buck estimates that there is easily double or triple that number of homegrown applications in academic and government supercomputing centers as well as within enterprises (particularly in the financial services sector) that have also been accelerated.
This is a very large application base, and enough to drive the business forward. Back in the days when HPC and enterprise applications ran predominantly on RISC systems (and sometimes Itanium ones) running a flavor of the Unix operating system, it was considered a success if more than 3,000 applications – with some generous slicing and dicing of what constituted an application – were supported on a given release of Solaris, AIX, or HP-UX. It looks like the CUDA-Tesla combo is probably around 2,000, which is not bad considering that not all applications can be accelerated by GPUs. And we have not even but the tip top of the wave of GPU accelerated applications for database and analytics that will flood the enterprise in the coming years.

Opening Up The Future “Venado” Grace-Hopper Supercomputer At Los Alamos
There are many interpretations of the word venado, which means deer or stag in Spanish, and this week it gets another one: A supercomputer based on future Nvidia CPU and GPU compute engines, and quite possibly if Los Alamos National Laboratory can convince Hewlett Packard Enterprise to support InfiniBand interconnects …
The New General And New Purpose In Computing
The term “general purpose” in regards to compute is an evolving one. What looked like general purpose in the past looks like a limited ASIC by today’s standards, and this is as true for GPUs and FPGAs as it is for CPUs. There is much talk about the era of …

Taking A Superhybrid Approach To HPC/AI Convergence
AMD has been on such a run with its future server CPUs and server GPUs in the supercomputer market, taking down big deals for big machines coming later this year and out into 2023, that we might forget sometimes that there are many more deals to be done and that …
Be the first to comment