

Every year at the Supercomputing Conference (SC) an unofficial theme emerges. For the last two years, machine learning and deep learning were focal points; before that it was all about data-intensive computing and stretching even farther back, the potential of cloud to reshape supercomputing.
What all of these themes have in common is that they did not focus on the processor. In fact, they centered around a generalized X86 hardware environment with well-known improvement and ecosystem cadences. Come to think of it, the closest we have come to seeing the device at the center of a theme in recent years is when the first large-scale GPU supercomputers entered the Top 500 list, but of course, those were accelerators versus the core of the machine.
This year at SC17, the unofficial theme has shifted back to the processor with a strong showing from the ARM hardware and software ecosystem, complete with system integration efforts from major supercomputing companies like Cray, and now, with some benchmarks that are difficult to ignore against best in class parts from Intel.
The team building the ARM-based (Cavium’s ThunderX2) “Isambard” supercomputer, which will be a 10,000 core machine at the University of Bristol in the UK next year, has pulled together a lot of the work that has been put into ARM for HPC on earlier systems. The most notable ARM based machine that served as the springboard for much of the development we see now is Mont Blanc (which began with dual Cortex-A15 ARM a few years ago and in its current incarnation is based on Cavium ThunderX2) at the Barcelona Supercomputer Center. For a detailed description of the Mont Blanc ARM journey this is a suggested read.
According to Simon McIntosh-Smith, one of the Isambard leads (who also worked on the Mont Blanc project), “for a long time, everyone was waiting for someone to do something real with ARM. Mont Blanc was an important set of difficult first steps leading here. The difference now is that the hardware is finally here to showcase what we have been working on for the last several years. Now with companies like Cray getting behind this—and getting serious—by putting ThunderX2 on the XC line versus on just a standard cluster, the message is that this is really becoming something real. The hardware just had to be in place.”
McIntosh and teams have revealed some very interesting benchmarks today based on their small 8-node cluster of white boxes from Cray with 32-core ThunderX2 processors compared to Skylake and Broadwell. The following are the basis for the comparison for a number of HPC applications.


Overall, McIntosh-Smith says anything that is memory bandwidth dominated does well on ThunderX2 and at worst, is roughly similar to Skylake. However for more floating point-heavy applications, Skylake and Broadwell do better and are evenly matched because of the wider vectors, even though ThunderX2 cores strive to make up the difference. As a preface, it will be interesting to see what might happen with these results if and when high bandwidth memory is added in, say, a ThunderX3 chip to bring it closer into line with what Fujitsu and NEC are working on. Either way, the results speak for themselves.
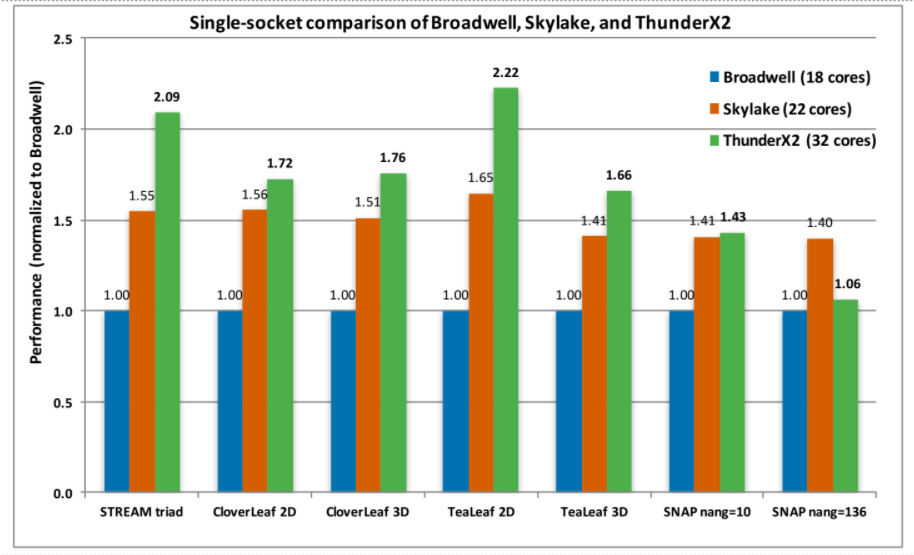
The memory bandwidth advantages are best seen in HPC on OpenFOAM—an open source CFD application frequently used in both commercial and research high performance computing as compared to Broadwell. We were told by the benchmark team that the OpenFOAM results were higher than Skylake and will work to get an updated chart showing just how much.
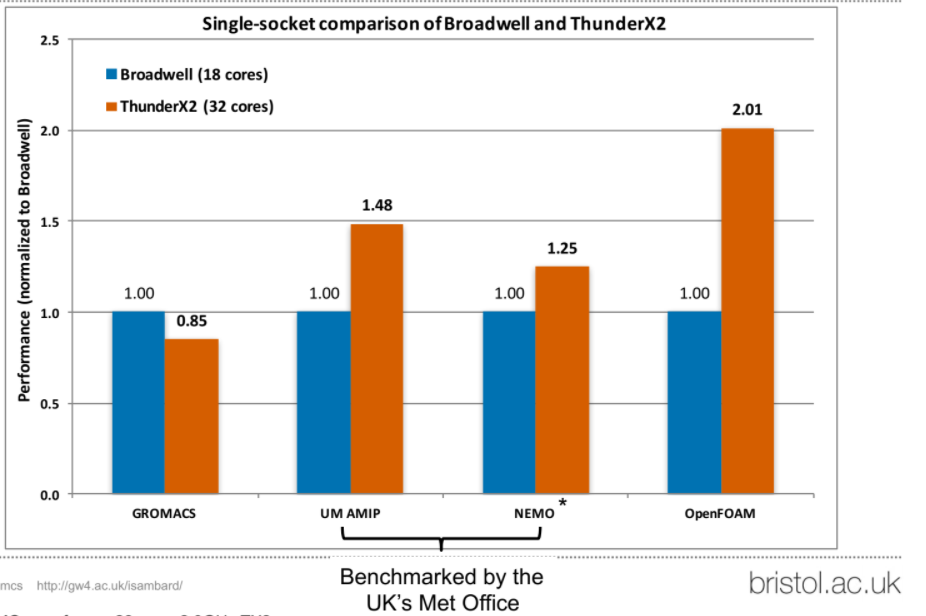
It would have been useful to see these results with Skylake comparisons included. Weather and climate modeling codes also show similar improvements with their memory bandwidth bounds as well. The figure below is the UK Met Office’s production code tested on ThunderX2—Nemo is an ocean modeling code.
“Early results suggest that for compute-bound applications such as GROMACS, CP2K, and VASP, performance between the different processors is closer than for memory bandwidth bound codes. This is because, while the codes benefit from wider vector units of the X86 processors, ThunderX2 compensates with higher core counts and clock speeds,” McIntosh-Smith says.

We will be able to see more results from this actual production ARM-based supercomputer as early as next SC with the arrival of top-end Cray XC50 system as described below. Until today, many of the HPC ARM watchers knew that Isambard was a Cray machine, but it might come as a surprise to some that the supercomputer maker took the tougher road, integrating ThunderX2 with the Aries interconnect and full complement of Cray software for the XC line. It would have been simpler for Cray to add this to a non-Aries based line like the CS Storm, for instance, but to McIntosh-Smith, this shows real commitment to the future of ARM in HPC from Cray.
Looking ahead, he sees opportunities for further growth of ARM’s reach into more HPC application areas with the addition of SVEs—something they are pushing with Cavium to see in future generations. As noted previously, NEC and Fujitsu are setting the bar for ARM performance and Qualcomm with its new Centriq processors are deploying interesting tradeoffs between external memory and clock speed/core count balances.
McIntosh-Smith sees a potential future where the different ARM options allow for an application specific approach to implementation. “In the future, ARM-based HPC will grow vector capabilities that will match anything from other CPU vendors. You can see that with Fujitsu, for sure. The next generation ARM offerings will have vector widths similar to everyone else,” he says. “There is a desire to explore options and try different ways to get to exascale and we know are looking at lot of diversity of in the tradeoffs. There will be lots of areas where Intel and AMD CPUs dominate, but with Cavium, Qualcomm, Fujitsu and others, there are a lot of choices to optimize for memory bandwidth for less floating point, for instance.”
The interesting thing here is also that these results are based on pure compiled results after optimizing just for core count and the basics. It took just a few hours of mild tweaking. McIntosh-Smith says that while this might seem like a sudden development, the hard work that went into being able to show results like these on HPC codes is several years in the making. With the hardware in place, the software story for ARM in HPC coming together faster than ever, and commercial availability of high-end supercomputers sporting ARM processors, this is the architecture’s day in the sun—and it could be the beginning of a new chapter for processor options in the X86 dominant world of HPC.




Be the first to comment