

After a long, long wait and years of anticipation, it looks like IBM is finally getting ready to ship commercial versions of its Power9 chips, and as expected, its first salvo of processors aimed at the datacenter will be aimed at HPC, data analytics, and machine learning workloads.
We are also catching wind about IBM’s Power9-based scale-up NUMA machines, which will debut sometime next year and take on big iron systems based on Intel Xeon SP, Oracle Sparc M8, and Fujitsu Sparc64-XII processors as well as give some competition to IBM’s own System z14 mainframes.
The US Department of Energy took initial deliveries at the end of July of the “Witherspoon” Power9 S922LC for HPC servers that underpin the “Summit” supercomputer at Oak Ridge National Laboratory, and Lawrence Livermore National Laboratory has also received its initial Witherspoon systems in the companion “Sierra” supercomputer, albeit with a different configuration to better suit its applications and budget, as we previously reported. Both of those machines will be built out over 2018 and, if all goes well, we think they should be at the top of the Top 500 supercomputer rankings, at number one and number two, by the June 2018 list.
Oak Ridge is getting around 4,600 Witherspoon nodes to crest above 200 petaflops of peak performance with Summit, most of which comes from the six “Volta” GPU accelerators in the system, while Livermore is getting 4,320 nodes with four Volta GPU accelerators to hit 125 petaflops on Sierra. Livermore is also installing a unclassified baby Sierra system with 684 nodes which is not funded by the Department of Energy. So all told, that is 19,208 Power9 processors across 9,604 dual-socket Witherspoon servers. This is a good start, to be sure, but if IBM need to sell a lot more processors to recoup its investment in Power9.
Let’s have some fun with math.
Say IBM charged only $5,000 for the 24-core Power9 chip – twice what it was charging at merchant silicon pricing for a 12-core Power8 without its “Centaur” memory buffer chips – then that would only amount to $96 million for processors out of a $325 million contract that seems to imply that the overall Summit machine costs around $200 million, the Sierra machine costs $125 million, and the uSierra machine costs around $19.8 million. With a likely 30 percent volume discount, the value of the processors in these three machines would be $67.2 million out of a total budget of $344.8 million, or about 19.5 percent of the total system cost. This doesn’t violate our sensibilities, and would leave plenty of room to pay for those Volta GPU accelerators.
Back when Volta was announced in May, we estimated that the theoretical list price of the SMX2 implementation of that GPU accelerator was $13,000 a pop at list price based on the pricing and configuration of the DGX-1V version of Nvidia’s hardware appliance for AI and HPC. At that price, just the GPUs alone would cost $619 million, so we know that didn’t happen. Memory – both flash and DRAM – in these systems is not cheap, and neither is the EDR InfiniBand networking. At 25 percent of what we think list price is for the GPUs, that still would come to $154.8 million across these three machines, and 45 percent of the total system cost, leaving around 35 percent of the budget, or $122.8 million, left to cover storage, networking, system software, and other sundries.
While this is fun math, in a node that might list for somewhere between $50,000 and $100,000 depending on the configuration of GPU, GPU, memory, flash, and interconnect, it is clear that IBM has to sell a lot of hybrid Power9-Volta systems to make money on the Power9 portion, and also that a lot of the money in the system will just pass right through to component suppliers. IBM needs to sell lots and lot of processors, to lots of HPC centers and enterprise shops that want to emulate them on a smaller scale, to make Power9 a better business than Power8 was. It would be nice to see it score some deals among hyperscalers like Google and cloud builders like Rackspace Hosting, who are partnering to deliver an Open Compute system, code-named “Zaius,” but which neither company has committed to deploy in large numbers as far as we know. We presume that Quanta Computer Technology will be building this system for these two companies; Supermicro has its own Power8 server designs, which as it turns out IBM is reselling in its own Power Systems commercial server line, and presumably will do Power9 machines, too.
This all starts with the Witherspoon servers, which could be launched this week at the Power Systems and Storage Technical University event that IBM is hosting in New Orleans. We talked to Brad McCredie, who is an IBM Fellow, vice president of Power Systems development, and president of the OpenPower Foundation, which is charged with opening up the Power architecture, about the Power9 rollout. “Here is what I can tell you,” McCredie says. “The systems that are engaged in the Summit and Sierra machines, we will make them available commercially this year. Which makes perfect sense.”
At the other end of the spectrum from these two-socket workhorse machines for AI and HPC are the big NUMA systems that run the database, analytics, and enterprise application workloads that still, by and large, power the back-end operations of most large enterprises these days. Some details are leaking out of IBM about the future “Fleetwood” systems, which presumably will be called the Power E970 and Power E980 and which are follow-ons to the “Brazos” Power E870 and Power E880 systems.
Both the current Brazos and the future Fleetwood machines are based on an architecture that goes back more than a decade and that is based on technology that IBM got through its $810 million acquisition of Sequent Computer Systems back in 1999. With this design, IBM puts circuits on the processor to connect four processor sockets in a system into a node and has additional circuits, which used to be on an external chipset but which are now on the Power die itself, that allows for up to four nodes to be linked gluelessly into a single system image. IBM used to have even more scalable 32-socket systems, like the Power 595 using Power6 chips and the Power 795 using Power7 chips, but when the core counts of the Power8 chip hit a dozen per socket and the performance kept doubling per socket, IBM instead decided to cut back the NUMA scale and boost the overall efficiency of the system to get a lot more throughput with only 16 sockets. This is the strategy again, it seems, with the Power9-based Power E970 and E980, which will use the ”Cumulus” or Scale Up, variant of the Power9 chip which has eight threads per core and twelve cores per socket. (The “Nimbus” variant of the Power9 is aimed at two-socket servers and scale-out clusters and has 24 cores with only four threads per core.)
With the Cumulus chips and the Fleetwood systems that use them (other systems will use them, too, not just these big NUMA boxes), IBM is working to improve the interconnect bandwidth on each node and across multiple nodes, which should radically improve the throughput and latency of applications running on these Power9 NUMA systems compared to their Power8 predecessors. Here is what it looks like:
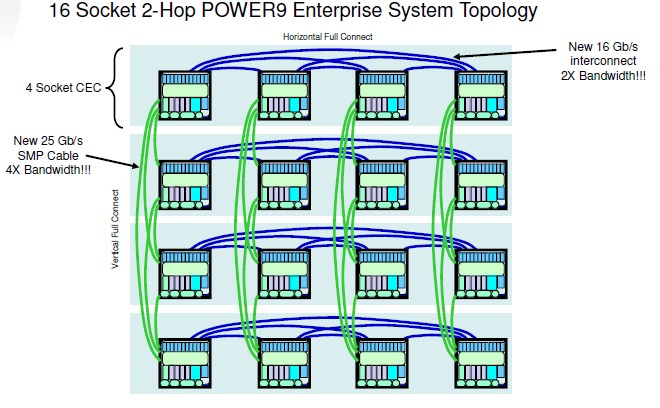
The SMP X buses in the above diagram are not properly named because this is actually a NUMA architecture, but set that to one side for a moment. These buses connect four processors on a system board together, while the SMP A buses link multiple server nodes into the system image up to a maximum of four nodes and 16 sockets. The SMP X buses in the Fleetwood systems are going to run at 16 Gb/sec, which is double the speed as the SMP X links used in Power8 iron, and the SMP A links are going to run at the same 25 Gb/sec speeds as the other interconnect on the Power9 chip, including the OpenCAPI and NVLink 2.0 ports used to link the processor complex to accelerators. As the Fleetwood system scales up, users will have to use up OpenCAPI and NVLink ports that might otherwise link to accelerators and other peripherals. We think the increase in east-west bandwidth on the Fleetwood motherboard and in the north-south bandwidth across multiple Fleetwood nodes is going to do a lot to increase NUMA performance. Maybe 60 higher than with the Brazos Power E870 and E880 machines, with about half of that coming from the processor tweaks and some clock speed bump engendered by the move to 14 nanometer processors (from the 22 nanometer processes used by the Power8) and the other half coming from the NUMA enhancements.
Here is our best guess about how the Power9 big iron boxes might stack up against their predecessors:
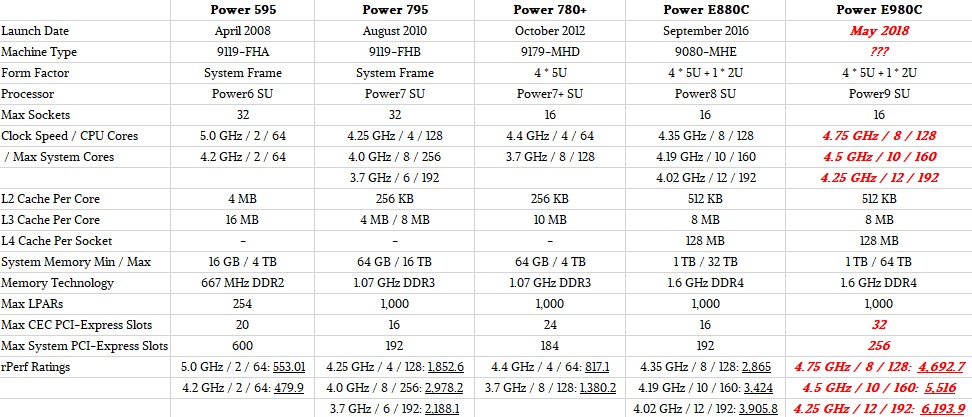
We are guessing that IBM is going to launch the Fleetwood systems in May, which is the tail end of the launch cycle and which is almost four years since the top end of the line was refreshed with the Power8 chips; we are not counting the tweaks with the Power E880C that came out in September 2016 as an upgrade since the processors did not change at all. It was just a packaging and pricing change with a doubling of main memory capacity.
The Power9 architecture supports up to 8 TB of memory per socket, or 128 TB across a machine with 16 sockets, but we do not believe that IBM will deliver this in the production Power E980 system, but rather will keep half the maximum capacity in reserve for those customers who need extra on a special bid basis. (This happens a lot with the Power Systems line.) So the Power E980 system will probably top out at 64 TB, which is twice that of the Power E880 it replaces and on par with the UV 300 systems from Hewlett Packard Enterprise (formerly SGI), which scale up to 64 sockets and 64 TB of main memory. With memory prices so high right now, no one is going to be shelling out for 128 TB of DRAM, unless they have damned near unlimited budgets.
In the table above, we are guessing about how the I/O will be configured in the Fleetwood system. With more compute and memory capacity, it is reasonable to expect an increase in I/O capacity, too. IBM is first out if the chute with PCI-Express 4.0 slots, and these will be particularly important for flash storage sporting the NVM-Express protocol, which substantially boosts I/O rates and lowers latency on flash and other non-volatile media when it becomes available. We expect for IBM to have NVM-Express slots in all of the Power9 systems, including the Fleetwood machines. The PCI-Express 4.0 protocol uses 16 Gb/sec signaling, double that of the PCI-Express 3.0 protocol used in several prior generations of Power Systems machines and, incidentally, matching the SMP X bus speed that is used to link processor sockets on a single Power9 motherboard.
We will see how well these Fleetwood rumors and our guesses pan out.

IBM Views Enterprise Storage Through Hybrid Cloud Glasses
For the past couple of decades, IBM’s Spectrum Scale – formerly known as General Parallel File System –has had a solid standing as one of the two go-to file systems for HPC. However, the emergence of modern workloads like artificial intelligence and analytics, coupled with the rapidly expanding growth of …

Big Blue Bucks The Datacenter Server Recession
Some patterns are very hard to break. From the very early days of the systems business as we know it, which started six decades ago, the fourth quarter of the calendar year has been the money maker for companies like IBM, and the second quarter has been a relatively big …

OpenPower Puts Open Source Software Guru In Charge
If you want to build a successful hardware ecosystem around a chip architecture that has recently been open sourced, as the Power chip instruction set was last August, then it probably makes a lot of sense to put someone at the helm of the project who has deep and broad …
Be the first to comment