

One of the reasons we have written so much about Chinese search and social web giant, Baidu, in the last few years is because they have openly described both the hardware and software steps to making deep learning efficient and high performance at scale.
In addition to providing several benchmarking efforts and GPU use cases, researchers at the company’s Silicon Valley AI Lab (SVAIL) have been at the forefront of eking power efficiency and performance out of new hardware by lowering precision. This is a trend that has kickstarted similar thinking in hardware usage in other areas, including supercomputing, and one that will continue with new devices like the Volta GPUs with “TensorCores” that allow for better exploitation of mixed and low precision operations. SVAIL has been playing with precision since the Maxwell generation GPUs, but it is just recently that they have stumbled on some striking new ways of implementing precision without losing quality and getting better memory and device performance.
Today, Baidu Research described another important deep learning milestone in conjunction with GPU maker, Nvidia. Teams demonstrated success training networks with half precision floating point without changing network hyperparameters and keeping with the same accuracy derived from single precision. Previous efforts with mixed lower precision (binary or even 4-bit) have come with losses in accuracy or major network modifications, but with some techniques applied to existing mixed precision approaches, this is no longer the case. This, of course, means better use of memory and higher performance—something that can be put to the test on the newest Nvidia Volta GPUs.
In essence, the way Baidu and Nvidia have managed to get lower precision without losing accuracy sounds simple and obvious. It boils down to using half precision during the iterations and storing weights and other info in single precision via reductions and multiplications. Of course, putting this into practice isn’t as simple as it sounds.
The most notable part about this is that there are no network hyperparameter changes that need to be made. There have been impressive research results in the past with low precision reported before, but these have involved heavy lifting in advance.
As Paulius Micikevicius, distinguished engineer in the computer architecture and applied deep learning research division at Nvidia tells The Next Platform, there are two techniques Nvidia and Baidu applied that help mitigate these changes. First is the mixed precision key. By using a matched copy of the network weights in single precision during updates from iterations, accuracy can be preserved; another copy in half is used for the forward and back propagation steps for the benefits of lower memory use, memory bandwidth pressure and potentially faster execution.
Another technique to reduce precision to FP16 without losing accuracy is via what Micikevicius describes as loss scaling. “With single precision, anything smaller than a certain value ends up becoming a zero. In many networks we train, a large number of activation gradients fall below that threshold. We don’t want to lose those values that become zeroes, so we run a forward pass as usual, and the resulting loss is multiplied with a scaling factor that is made magnitudes larger. That is moved into a range that is representable in half precision, but before the updates are made, we scale those back down to make sure we’re staying accurate. It ultimately gets added to those single precision master weights and the process is repeated.”
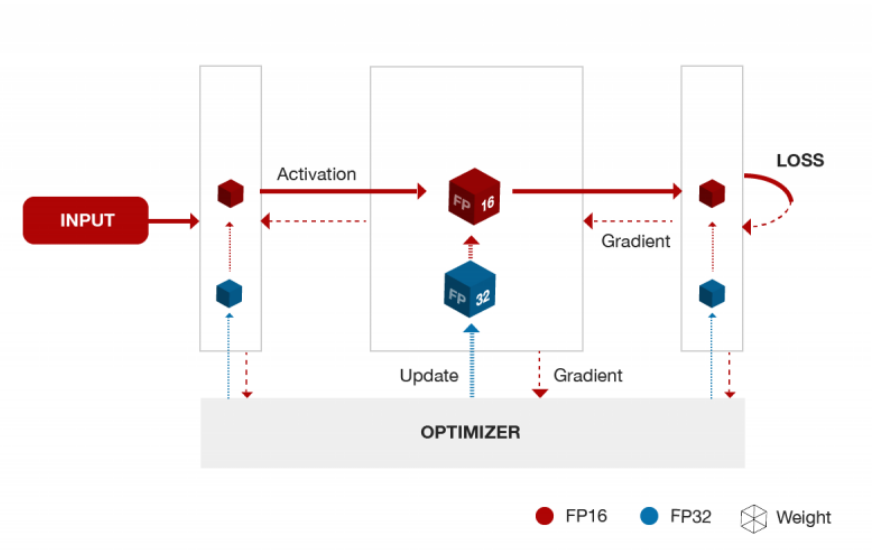
A unique element here is that the TensorCore on Nvidia’s latest Volta GPUs plays an important role. In fact, it would not be possible to do what the researchers proved with good performance without it, according to Baidu’s Greg Diamos. He tells us that the TensorCore is important in that accordion of precision values required. Since TensorCore’s single instruction base takes two input matrices that are half precision and computes their products before adding them in the accumulation to get to single precision for stoing, before a library code converts them to half precision before writing the results out to memory. Yes, you probably had to read that twice.
“Before TensorCore, if you wanted arithmetic in half precision, there were not instructions that would take two FP16 inputs, multiply them and add them together. The arithmetic in FP16 was more challenging with Volta, but there are big possibilities for memory savings.”
The point is, it is ultra-fast at doing the math to allow the fast half to single back to half precision required for this approach. Doing this on any GPU that came before would be tremendously slow and difficult, Diamos explains, noting that even the cadre of low-precision hardware targeting the deep learning market is going to have a lot of legwork on the software side to get to this point. It is not as easy as it sounds—and another tough problem lies on the other side of the benefits of FP16 at scale. Memory access is an ongoing concern; with more hits against memory from ever-larger and more complex networks at lower precision, there is some passing of the bottleneck going on. In short, the advantages gained from this reduced/mixed precision approach will come with a price, something Diamos says teams at both companies are working on already.
As Diamos says, the focus of the work is to speed training but the side effect of these new approaches with mixed precision allow for the reduction of the memory requirements for training. They can also fully use hardware like the Volta GPU to train, which will be the platform of choice for most, if not all of Baidu’s networks going forward. This includes many of the company’s own models, including Deep Speech 2 and other object and voice recognition frameworks they have developed in house.
Using this approach, we are able to train the DeepSpeech 2 model using FP16 numbers, explains Sharan Narang, systems research at Baidu Research. “For both English and Mandarin models/datasets, we can match the accuracy of the FP32 models. We use the same hyper-parameters and model architecture for the mixed precision training experiments.” He adds that it is also possible to “reduce the memory requirements for training deep learning models by nearly 2x using FP16 format for weights, activations and gradients. This reduced memory footprint allows us to use half the number of processors for training these models, effectively doubling the cluster size. Additionally, peak performance for FP16 arithmetic (described above) is usually a lot higher than single precision compute. This technique enables us to take advantage of the faster compute units available for FP16 numbers.”
The full set of experiments and results are available in the paper, which was just released.
One of the reasons we have written so much about Chinese search and social web giant, Baidu, in the last few years is because they have openly described both the hardware and software steps to making deep learning efficient and high performance at massive scale.
In addition to providing several benchmarking efforts and GPU use cases, researchers at the company’s Silicon Valley AI Lab (SVAIL) have been at the forefront of eking power efficiency and performance out of new hardware by lowering precision. This is a trend that has kickstarted similar thinking in hardware usage in other areas, including supercomputing, and one that will continue with new devices like the Volta GPUs with TensorCores that allow for better exploitation of mixed and low precision operations. SVAIL has been playing with precision since the Maxwell generation GPUs, but it is just recently that they have stumbled on some striking new ways of implementing precision without losing quality and getting better memory and device performance.
Today, the Chinese search and social web giant described another important deep learning milestone in conjunction with GPU maker, Nvidia. Teams demonstrated success training networks with half precision floating point without changing network hyperparameters and keeping with the same accuracy derived from single precision. Previous efforts with mixed lower precision (binary or even 4-bit) have come with losses in accuracy or major network modifications, but with some techniques applied to existing mixed precision approaches, this is no longer the case. This, of course, means better use of memory and higher performance—something that can be put to the test on the newest Nvidia Volta GPUs.
In essence, the way Baidu and Nvidia have managed to get lower precision without losing accuracy sounds simple and obvious. It boils down to using half precision during the iterations and storing weights and other info in single precision via reductions and multiplications. Of course, putting this into practice isn’t as simple as it sounds.
The most notable part about this is that there are no network hyperparameter changes that need to be made. There have been impressive research results in the past with low precision reported before, but these have involved heavy lifting in advance. As Paulius Micikevicius, distinguished engineer in the computer architecture and applied deep learning research division at Nvidia tells The Next Platform, there are two techniques Nvidia and Baidu applied that help mitigate these changes. First is the mixed precision key. By using a matched copy of the network weights in single precision during updates from iterations, accuracy can be preserved; another copy in half is used for the forward and back propagation steps for the benefits of lower memory use, memory bandwidth pressure and potentially faster execution.
Another technique to reduce precision to FP16 without losing accuracy is via what Micikevicius describes as loss scaling. “With single precision, anything smaller than a certain value ends up becoming a zero. In many networks we train, a large number of activation gradients fall below that threshold. We don’t want to lose those values that become zeroes, so we run a forward pass as usual, and the resulting loss is multiplied with a scaling factor that is made magnitudes larger. That is moved into a range that is representable in half precision, but before the updates are made, we scale those back down to make sure we’re staying accurate. It ultimately gets added to those single precision master weights and the process is repeated.”
A unique element here is that the TensorCore on Nvidia’s latest Volta GPUs plays an important role. In fact, it would not be possible to do what the researchers proved with good performance without it, according to Baidu’s Greg Diamos. He tells us that the TensorCore is important in that accordion of precision values required. Since TensorCore’s single instruction base takes two input matrices that are half precision and computes their products before adding them in the accumulation to get to single precision for stoing, before a library code converts them to half precision before writing the results out to memory. Yes, you probably had to read that twice.
“Before TensorCore, if you wanted arithmetic in half precision, there were not instructions that would take two FP16 inputs, multiply them and add them together. The arithmetic in FP16 was more challenging was more challenging with Volta, but there are big possibilities for memory savings.”
The point is, it is ultra-fast at doing the math to allow the fast half to single back to half precision required for this approach. Doing this on any GPU that came before would be tremendously slow and difficult, Diamos explains, noting that even the cadre of low-precision hardware targeting the deep learning market is going to have a lot of legwork on the software side to get to this point. It is not as easy as it sounds—and another tough problem lies on the other side of the benefits of FP16 at scale. Memory access is an ongoing concern; with more hits against memory from ever-larger and more complex networks at lower precision, there is some passing of the bottleneck going on. In short, the advantages gained from this reduced/mixed precision approach will come with a price, something Diamos says teams at both companies are working on already.
As Diamos says, the focus of the work is to speed training but the side effect of these new approaches with mixed precision allow for the reduction of the memory requirements for training. They can also fully use hardware like the Volta GPU to train, which will be the platform of choice for most, if not all of Baidu’s networks going forward. This includes many of the company’s own models, including Deep Speech 2 and other object and voice recognition frameworks they have developed in house.
Using this approach, we are able to train the DeepSpeech 2 model using FP16 numbers, explains Sharan Narang, systems research at Baidu Research. “For both English and Mandarin models/datasets, we can match the accuracy of the FP32 models. We use the same hyper-parameters and model architecture for the mixed precision training experiments.” He adds that it is also possible to “reduce the memory requirements for training deep learning models by nearly 2x using FP16 format for weights, activations and gradients. This reduced memory footprint allows us to use half the number of processors for training these models, effectively doubling the cluster size. Additionally, peak performance for FP16 arithmetic (described above) is usually a lot higher than single precision compute. This technique enables us to take advantage of the faster compute units available for FP16 numbers.”
The full set of experiments and results are available in the paper, which was just released.


A Look at Baidu’s Industrial-Scale GPU Training Architecture
Like its U.S. counterpart, Google, Baidu has made significant investments to build robust, large-scale systems to support global advertising programs. As one might imagine, AL/ML has been playing a central role in how these systems are built. Massive GPU-accelerated clusters on par with the world’s most powerful supercomputers are the …

More Proof Points for Low Precision HPC
While it might not happen anytime soon, traditional supercomputing could be in for a sea change with wider acceptance of lower-precision calculations. Such a change translates into reduced accuracy but with the benefit of orders of magnitude higher efficiency and speed. What is acceptable in that tradeoff depends on the …

Vertically Unchallenged
Components make compute and storage servers, and servers with application plane, control plane, and data plane software running atop them or alongside them make systems, and workflows across systems make platforms. The end state goal of any system architect is really creating a platform. If you don’t have an integrated …
Be the first to comment