

Chip giant Intel has been talking about CPU-FPGA compute complexes for so long that it is hard to remember sometimes that its hybrid Xeon-Arria compute unit, which puts a Xeon server chip and a midrange FPGA into a single Xeon processor socket, is not shipping as a volume product. But Intel is working to get it into the field and has given The Next Platform an update on the current plan.
The hybrid CPU-FPGA devices, which are akin to AMD’s Accelerated Computing Units, or APUs, in that they put compute and, in this case, GPU acceleration into a single processor package, are expected to see widespread adoption, particularly among hyperscalers and cloud builders who want to offload certain kinds of work from the CPU to an accelerator. While Intel has GPUs of its own and it puts them in a CPU package or on the CPU die for certain parts of the market – low-end workstations and low-end servers based on the Xeon E3 chip that are used to accelerate media processing and such – Intel is not enthusiastic about offloading work from its Xeon processors to other devices. It created the “Knights” family of parallel X86 processors first as an offload engine and then as a full processor in its own right with the “Knights Landing” Xeon Phi 7200 series that saw initial shipments in late 2015 and formally launched in the summer of 2016. Intel has just killed off the coprocessor versions of the Knights Landing chips – they never really shipped – because customers just want to use the hosted version of the Xeon Phi that can run its own operating system.
That said, FPGAs, just like GPUs, imply an offload model and Intel is trying to bring a variety of FPGA configurations into the field to make sure that the work that does get offloaded from a Xeon CPU either moves to a Xeon Phi (for traditional HPC and new fangled AI workloads, mostly for the training of neural networks) or to an Altera FPGA in one form factor or another, or a smattering of those low-end CPU-GPU hybrids mentioned above. It certainly doesn’t want Nvidia’s Tesla GPU accelerators or the combination of AMD Epyc CPUs and Radeon Instinct GPU accelerators to get the job.
Intel first started to talk about hybrid Xeon-FPGA device after it a foundry partnership deal with FPGA maker Altera, its first such commercial customer, and before it went all the way in June 2015, paying $16.7 billion to acquire Altera lock, stock, and barrel. Diane Bryant, who used to run Intel’s Data Center Group before taking a leave of absence this year, made an impromptu announcement of the first hybrid CPU-FPGA device a year early in June 2014. At the time, Bryant said that adding FPGAs to the compute complex could speed up workloads by as much as 10X and that by directly hooking the FPGA to a Xeon processor using a QuickPath Interconnect (QPI) link, which normally used for NUMA scaling in multiprocessor systems, instead of over the PCI-Express peripheral bus could increase that to a 20X performance boost.
It was not really much of a surprise when Intel did buy Altera, one of the two dominant players in the field. (Programable. Gate. Array. The other is Xilinx, of course.) If there was any surprise at all, it was the amount of money that Intel shelled out for a company that made under $2 billion a year in revenue. And we got a hint of what Intel was worried out when, in the wake of the Altera deal, the company set out its positioning of FPGAs against GPUs and subsequently said that it expected that a third of cloud builders (which also includes what we call hyperscalers) would have FPGAs in their systems by 2020. With a 10X to 20X performance advantage on some of the workloads and millions of units at stake, that is a massive compression in the number of Xeons that might be sold. (So far, we have not see this effect, but imagine how many CPUs it would have take to do the deep learning miracle, and at what cost. This innovation might not have happened at all.) Thus far, Intel Xeons are selling apace, even with FPGA, GPU, and other accelerators taking bites out of the Xeon business. In additional to SmartNIC network interface and other network function virtualization work, FPGAs have been used to do server encryption offload and even to accelerate relation databases, as is done by Swarm64. In some cases, the FPGA card is getting its own memory and compute and leaving only some core serial work for the CPU to do, as is the case with the dual-FPGA coprocessor from Nallatech.

By the way, having processors ganged up with FPGAs is, strictly speaking, old hat. Both Xilinx and Altera have had FPGAs with ARM processors on the same system-on-chip package for many years, and Intel could have done the same with its Xeon D X86 chip design for hyperscalers. And, in fact, that could be what it did to create the second generation testbed CPU-FPGA hybrid device, which it showed off in March 2016. This device put a 15-core Broadwell Xeon processor in the same package as an Arria 10 FPGA, which is not the top end part like the top-end Stratix 10, which is made using Intel’s 14 nanometer processes, which is sampling now, and which is expected to start shipping before the end of the year, Bernhard Friebe, senior director of FPGA software solutions at Intel’s Programmable Solutions Group, tells The Next Platform.
Intel is taking a two-pronged approach with its FPGA strategy, using a mix of hybrid CPU-FPGA devices like that Broadwell-Arria package that share a socket and discrete Xeon CPU and Arria or Stratix FPGA devices that are connected over the PCI-Express bus to each other.

According to Friebe, Intel’s current plan is to create its own PCI-Express cards based on the Arria 10-GX FPGA, what it is calling a programmable acceleration card, or PAC, and start peddling these in the first half of 2018. There will eventually be PACs based on the Stratix 10 FPGA, but Intel is not saying when they might be available. Probably later in 2018 is our guess.
The hybrid CPU-FPGA device, which will include an unnamed “Skylake” Xeon SP processor matched to an Arria 10 FPGA, will be a follow-on to the experimental Broadwell-Arria device and will use faster UltraPath Interconnect (UPI) links to hook the FPGA directly to the Skylake chip within a Socket P socket. We also know that this is a single-socket machine, so it probably means a relatively low bin Skylake part (maybe Silver or Bronze) and probably with only one UPI link. (More is not necessarily better.)
It is not clear if there are one, two, or three links between these two compute elements, but given that Skylake can do one, two, or three UPI ports, depending on the model, it could by anything. It is also not clear what coherency model Intel intends to use between the two devices, but clearly the benefit is that the CPU and FPGA can access literally the same memory and not pass data between the two devices, either by directly or by moving pointers with virtual addressing, and therefore not have to move it at all. It would be interesting indeed if Intel endorsed CCIX, Gen-Z, or OpenCAPI, three emerging protocols, to provide some level of coherency between the devices so memory addressing was invisible to programmers. We shall see.
What we can tell you is that Intel is concentrating on the programming environment so the same tools will be used whether the CPUs and FPGAs are discrete or hybrid in the same socket. This is called the Acceleration Stack for Intel, and it is a complete programming environment that is based on OpenCL, the common higher level programming language that is converged to Verilog and VHDL for FPGAs.
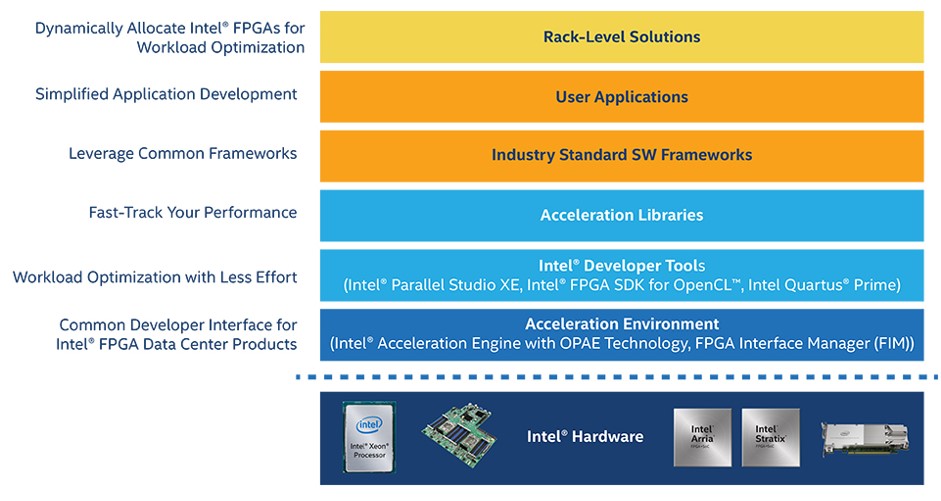
This Acceleration Stack for FPGAs is made explicitly for Intel devices, and according to Friebe is a combination of firmware in its systems and the FPGAs coupled with an open source framework called the Open Programmable Acceleration Engine, or OPAE. This consists of physical FPGA drivers for operating systems running on bare metal and a virtual FPGA driver for those running underneath a server virtualization hypervisor and having their functions exposed to virtual machines.
The idea is to have a consistent set of APIs, accessed through C, for either hybrid or discrete setups, and like a good open source citizen Intel has freed up this OPAE code and let it run wild on GitHub. The APIs for the FPGAs are under a BSD license, and the FPGA drivers are under a GNU GPLv2 license. There are a number of OpenCL tools, which companies will have to license, and Intel has its own, which is called the Intel FPGA for OpenCL, and it does all kinds of optimizations to run on the FPGAs.
It would probably be useful if these tools can suck in C code, convert it to OpenCL, and then down to VHDL.) It is expected that, given this OPAE software layer, application frameworks higher up the stack will talk to OPAE to offload work to FPGAs, greatly simplifying the programming task. The OpenCL code gets automagically compiled down to VHDL for the FPGA, of course.
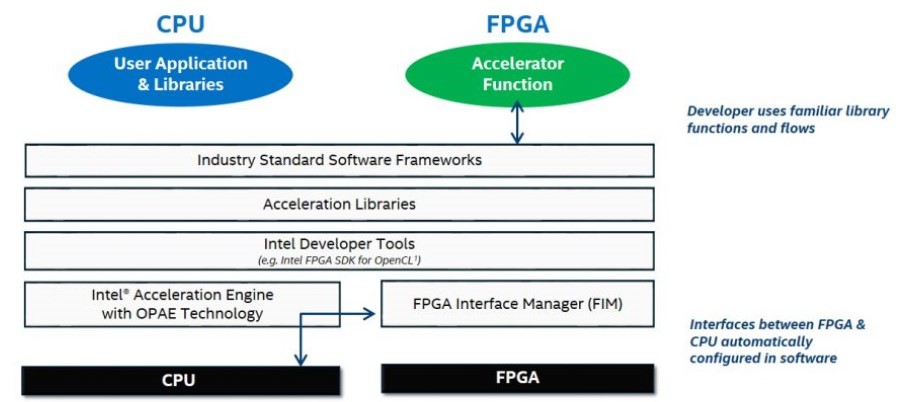
The point is, Intel is making programming FPGAs easier and consistent across its two prongs, and even if it is not simple, FPGAs are by their very nature a little tougher to program. What do you expect for something that is halfway between hardware and software?
Perhaps the most interesting this is that Intel is very keep on using FPGAs to accelerate machine learning workloads, particularly for inferencing, and it will be putting out its own preconfigured FPGA algorithms for this, which customers will be able to license like software. This is precisely what we predicted when rumors about the Intel acquisition were going around two and a half years ago.
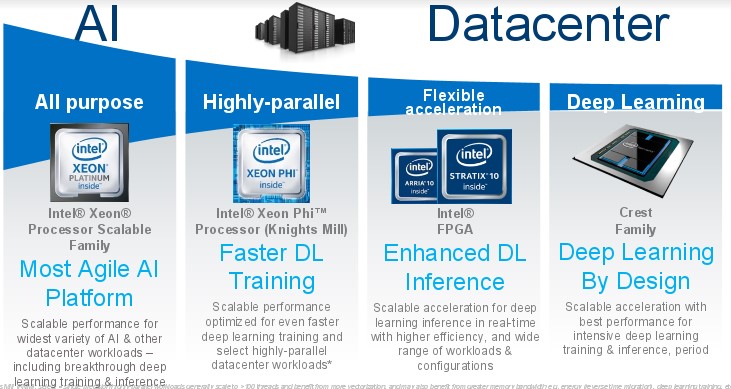
But Intel has a lot of different iron to throw at AI, and it will be interesting to see what customers do.
What we have been wondering is when to use the hybrid setup and when to use the discrete setup in CPU and FPGA compute. The hybrid device has modest compute power, but it has high memory bandwidth and low latency; the discrete approach allows for more CPU compute – two, four, or eight sockets with the Xeon SPs – and more FPGA compute – as many PCI-Express x16 cards as you can fit, call it eight in a server. The FPGAs have a lot of different connectivity and I/O options in their own right because this, too, can be programmed with VHDL.
“Depending on what you want to do, there are different use models,” says Friebe. “The integrated solution is mostly used as a lookaside accelerator. “The data comes into the CPU, tasks are offloaded to the FPGA, results are sent back, and you move onto the acceleration. With a discrete card, you can expand into other use models. For example, you can use the FPGA in an in-line or streaming mode, where the data comes in through high bandwidth interfaces directly into the FPGA and then through the PCI-Express link data that is worked on is sent to the CPU for further processing.”
There might even be scenarios where both are used in the same system. Stranger things have happened.


Reimagining Accelerators with Sparsity at the Core
There could be a new era of codesign dawning for machine learning, one that moves away from the training and inference separations and toward far less dense networks with highly sparse weights and activations. While 2020 was peak custom AI chip, it could be that the years ahead feature devices …

Covering All The Compute Bases In A Heterogeneous Datacenter
Intel has spent more than three decades evolving from the dominant provider of CPUs for personal computers to the dominant supplier of processors for servers in the datacenter. While Intel has argued that Moore’s Law is not dead – that the pace of innovation with transistors and therefore semiconductors has …
Intel’s First Discrete Xe Server GPU Aimed At Hyperscalers
We have been waiting for years to see the first discrete Xe GPU from Intel that is aimed at the datacenter, and as it turns out, the first one is not the heavy compute engine we have been anticipating, but rather a souped up version of the Iris Xe LP …
So, OpenCL. Means, after all heavy computational software packages are filled with CUDA code, after “Knights” or whatever levels with GPU cards prices, after another OpenCL code injection we finally will be able to do something with those cards. And still no decent heating solution. Great plan, prepare cash.
What is QuickSync?
“Intel is not enthusiastic about offloading work from its Xeon processors to other devices.”
“With a 10X to 20X performance advantage on some of the workloads and millions of units at steak [sic], that is a massive compression in the number of Xeons that might be sold. ”
That says a lot about intel. a/ obstructed clients getting a 10-20x performance benefit & b/ stupid enough to think they could get away with it til its too late – & have to pay through the nose for altera for what sounds a kludgy knee jerk response to competitors with no market share to defend.
It begars belief intel dont get that the cpu is only half the answer these days. It takes til 2015 to realise they need a gpu skillset and products.