

We have heard much about the concept of dark silicon but there is a separate, related companion to this idea.
Dark bandwidth is a term that is being bandied about to describe the major inefficiencies of data movement. The idea of this is not unknown or new, but some of the ways the problem is being tackled present new practical directions as the emphasis on system balance over pure performance persists.
As ARM Research architect, Jonathan Beard describes it, the way systems work now is a lot like ordering a tiny watch battery online and having it delivered in a box that could fit something an order of magnitude larger and with a lot of unnecessary packaging around it to account for the extra space.

Even with the coming demise of Moore’s Law, Beard says there is still another 60-70% performance left on devices for many applications since so much time is spent moving useless data around the system. The goal is to take that 60-70% of “packaging” and make it do something more useful.
“Dark bandwidth results in more energy used; higher latency, and less usable bandwidth between levels of the cache hierarchy,” Beard explains. The solutions to this include moving instructions to the data or doing near or in-memory computation. These are new ideas, but Beard says there is much more inefficiency in how this is currently done than meets the eye. The goal is to save the core for what it is good at (dense, high throughput compute) and put smaller bits of compute closer to the data, which is capable of gathering data closer to where it lives.
“Our whole memory hierarchy is designed for 64 or 128 byte access patterns, so you have to access data in those chunk sizes. Back to the packaging example, there is so much waste here; we want to get rid of the superfluous data movement in the system.” Processing near memory allows for tight integration and having logic that is added at the controller level. With processing near memory you can send your functions to the data. This has been proposed before and there are problems with it but it is more efficient, Beard says.
The right kind of system to eke more years out of Moore’s Law would include heavier-weight throughput cores and a few different engines to reduce the unnecessary data movement. These include direct memory access and gather-scatter engines near memory. These computations would be handled by very lightweight (let’s guess small mobile-centric ARM processors) simple near memory processors that would not require all the superfluous data movement of existing architectures.
This idea is getting more traction with the idea that memory is the next platform for pushing performance into existing devices. With HBM, HMC, non-volatile and solid state devices having more logic added at the controller level, we could very well start to see just what Beard and others are talking about—a great deal of lightweight added intelligence into memory to avoid wasteful data movement.
In the case of something like a custom gather-scatter engine near the memory device, there is benefit for applications with high and low compute intensity angles. A gather scatter engine near memory makes sense for things that would otherwise require a GPU or heavy vector units to be efficient.
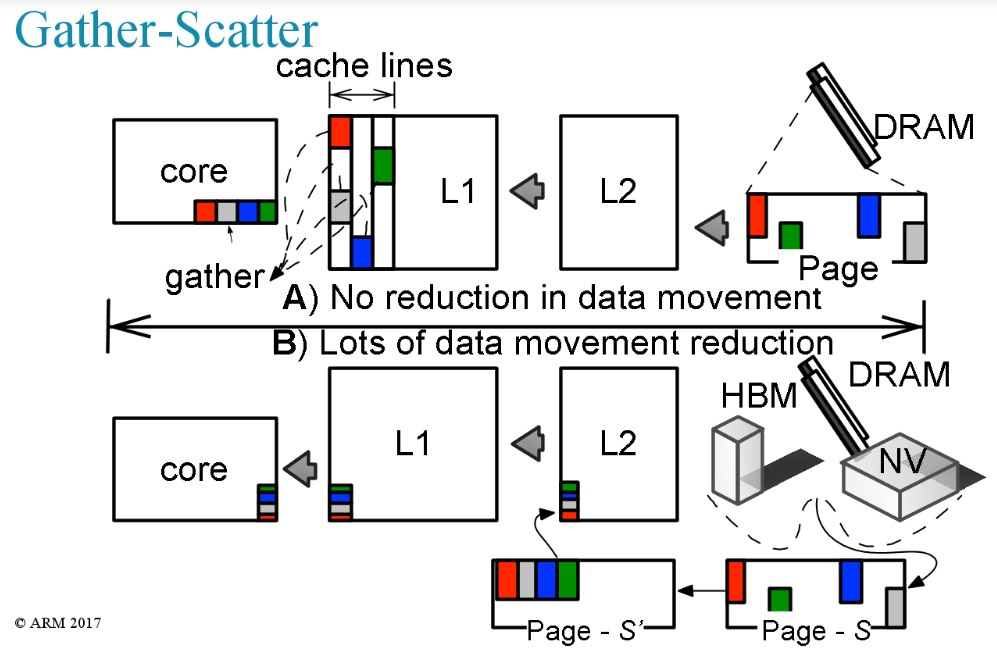
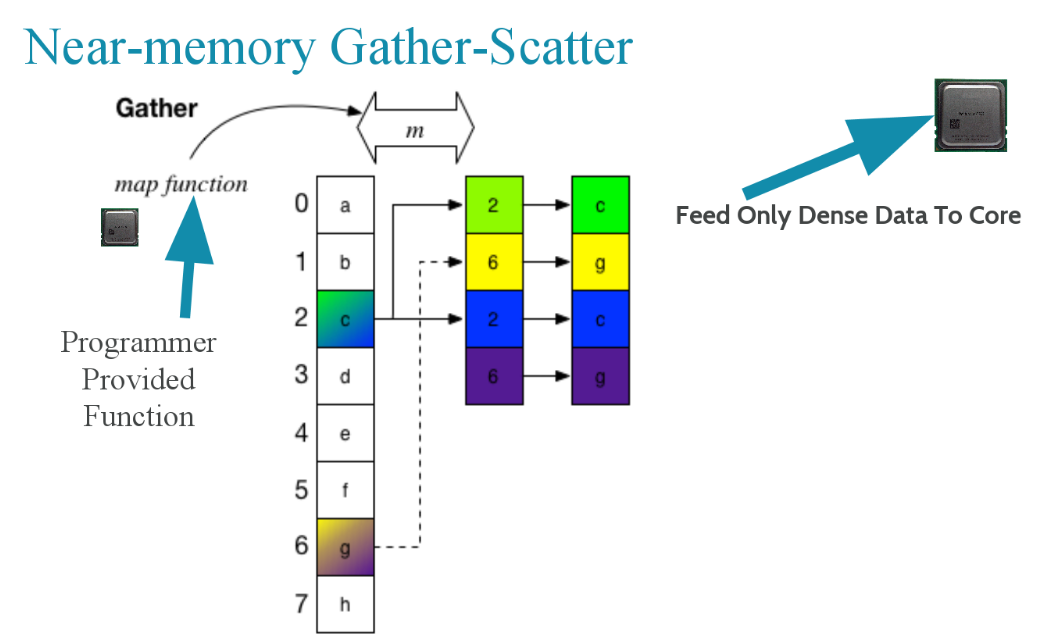
“In core gather-scatter is good for things where you bring the cache lines into L2 or L1 but if you use this engine you can get far more reuse out of that data. This would be useful for things like MapReduce, fluid dynamics, molecular dynamics—anything where you’re gathering over a lattice or many locations and don’t know where that is going so you can’t arrange the data structures.” In short, instead of adding accelerators or additional vector units as hardware, processing near memory via tiny lightweight engines is more efficient, he argues.
“The main difference between the CPU, and accelerators is that memory hand-off must be coordinated by an external agent: the CPU. No matter how efficient engineers and researchers make cores and accelerators, the model of paging in data from memory one DDR burst at a time, all coordinated by the general purpose core, limits the efficiency and scalability of all future systems intended for more sparse workloads.”
“Pulling the memory hierarchy into the compute system as a first class citizen, not only to feed cores but as an active participant, will enable extracting more performance from less revolutionary memory and compute technologies. Reducing overall system data movement will likely net system designers far more over the next decade than any revolutionary technology changes,” Beard explains. “Enabling small amounts of computation in- or near-memory along with fixing the virtual memory system could enable future systems to recapture dark bandwidth. Doing all of this, while not breaking all extant software is a huge, but not insurmountable, challenge. It’s not just the memory technology or compute alone that should be the focus, it’s how the compute system as a whole uses it.”
Beard’s disclaimer is that this is just research and not a statement of direction for where ARM is going, but it is fair to conjecture that all chipmakers are thinking about this very thing. System balance is a more important goal than mere floating point performance these days and with a shorted list of post-Moore’s Law options on the realistic horizon, it is no surprise ARM and others are considering ways around the dark bandwidth problem. Beard and ARM colleagues have a paper on this topic with some good charts and benchmarks here.

The Power Of Power10’s Memory Inception Clustering
Scanning through Power10’s detailed announcement material, I’ve seen a lot architecturally that intrigues an avid reader of The Next Platform like myself, but one item – one that IBM calls “Memory Inception” and IBM-based techie material calls enablement for a “memory cluster” – really caught my eye. It has the …

Intel Declares A Truce Before Bus Wars Flare Up
A system is more than its central processor, and perhaps at no time in history has this ever been true than right now. Except, perhaps, in the future spanning out beyond the next decade until CMOS technologies finally reach their limits. Looking ahead, all computing will be hybrid, using a …
Mashing Up CXL And Gen-Z For Shared Disaggregated Memory
If you are impatient for not just memory pooling powered by the CXL protocol, but the much more difficult task of memory sharing by servers attached to giant blocks of external memory, you are not alone. Memory fabric creator IntelliProp is right there with you. And that is why IntelliProp, …
Be the first to comment