

According to a recent Jefferies report, the fourth wave of computing has started and it is being driven by the adoption of IoT with parallel processing as the solution. Tectonic shifts in computing have been caused by major forces dating back to the 1960s.
With each shift, new solution providers have emerged as prominent suppliers. The latest power often cited with the fourth wave is Nvidia and its parallel processing platform for HPC and artificial intelligence (AI), namely GPUs and the CUDA programming platform. The growth of the data center segment of Nvidia’s business – from $339 million in fiscal year 2016 to $830 million in fiscal year 2017 – is a testament to this tectonic shift. The technology and product requirements for AI and self-driving cars are key growth drivers for Nvidia and these can be broadly associated with IoT. However, IoT has other, equally critical requirements in the security and networking space that cannot be overlooked.
The Growth Of AI And Parallel Processing
Let us take a deeper look at the tectonic shift happening now in the field of AI. Machine learning training, inference algorithms and related technologies are foundations of AI, and these have existed for decades. The inflection points that have created a groundswell of opportunities for companies like Nvidia are:
- The availability of massive sets of useful training data across multiple industries, and
- Advances in silicon design and process geometries that enable machine learning-related parallel processing within acceptable cost and power profiles.
As more devices – both in numbers and types across different industries – connect to the Internet (in other words the IoT phenomena), the amount of useful data generated and the ability to use such data for machine learning to help improve user experiences in those industries will experience a viral effect. GPUs, as coprocessors to x86 CPUs, enable much needed parallel processing for machine learning algorithms. GPUs were originally designed for gaming and graphics applications. Along with multi-threaded programming environments such as CUDA, GPUs have been found to be optimal for executing machine learning algorithms most efficiently.
Multi-threaded processing in GPUs enables execution of similar tasks in parallel, and this is vital for executing machine learning algorithms most efficiently. This way of processing is very unlike general-purpose CPUs like X86 and ARM, which are optimized for single-threaded processing needed in common software applications like web servers and database processing. Modern GPUs also provide high speed and efficient memory access to the massive amounts of training data that need to be processed by machine learning algorithms.
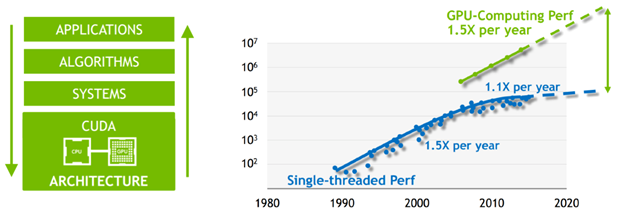
While general-purpose CPUs can be applied to process machine learning algorithms, the computing performance needed simply does not scale. Couple that with the increasing cost per transistor with new silicon process geometries (aka the demise of Moore’s Law), and optimized coprocessor silicon such as the GPU for machine learning has become a must.
Security And 5G Will Drive The Fourth Wave
With respect to IoT and the fourth wave of computing, there is stark similarity between AI and network security in the importance of parallel processing using coprocessors.
The need for pervasive security across every facet of our lives will only be exacerbated by IoT. If we just take the example of recent Distributed Denial of Service (DDoS) attacks and how today’s devices (with laptops and tablets as the attack surface) are hacked into to generate such attacks, one can imagine the exponential effects on the available attack surface with the adoption of IoT. The mechanisms for preventing DDoS attacks will have to extend beyond the perimeter, all the way into the data center servers, to address the needed scale and pace at which DDoS attacks will have to be mitigated. This need is amplified by the growing amount of data traffic that traverses within the data center.
A second key shift in the paradigm is the need for traffic visibility for performing telemetry on network traffic or blocking rogue traffic flows. This need exists today and will be further exacerbated as 5G networks open the gates (with a 10X bandwidth increase) for new industries to deliver innovative services over the telecom service provider networks. For example, IoT sensors of various types and self-driving cars will add to the data traffic already generated by mobile devices such as smart phones. The ability to split the network into “slices” will be key to ensuring the right service levels are guaranteed for different types of traffic. This will require traffic classification and visibility at high speeds.
Gartner predicts that by 2019, 80 percent of all web traffic will be encrypted. The key relevant technologies are Secure Sockets Layer (SSL) and Transport Layer Security (TLS) used for securing web traffic. When traffic is encrypted with such technologies, it becomes impossible to gain needed visibility into the traffic. A study by NSS Labs reported that decrypting SSL traffic on a firewall appliance (for the purpose of gaining visibility into the traffic) implies a loss of 74 percent for throughput and 87.8 percent for transactions per second. Longer keys are necessary to process the sophisticated traffic increases in the workload needed by the SSL decryption engine. The impact to latency and related service levels are also significant. The optimal solution is to move away from implementing such functions in appliances in the perimeters of the data center network where traffic is aggregated and bottlenecks are most impactful, and distribute the SSL decryption engine workload across all servers.
Scaling Security Applications With SmartNICs
To enable scale, performance and efficiency for network security applications in data center servers, a SmartNIC platform uses an optimized coprocessor, the NFP, or Network Flow Processor. Similar to the GPU, the NFP is multi-threaded, with up to 960 threads on a single chip. Similar to CUDA-based multi-threaded programming on GPUs, the NFP silicon in SmartNICs supports multi-threaded programming using C or higher-level, vendor-agnostic programming methods such as P4 and eBPF. Like a GPU, the NFP can execute multiple tasks in parallel. Unlike a GPU that can execute only similar tasks in parallel, the NFP can execute multiple different tasks in parallel as well – a feature needed in network security.
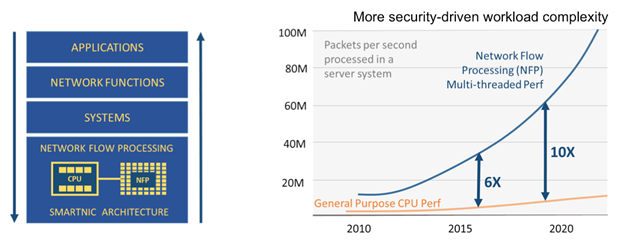
The NFP enables fast and low-latency access to large amounts of memory using a multi-threaded memory access engine, enabling it to process vast amounts of sophisticated traffic flows in parallel. Finally, in the world of AI, deep learning frameworks such as Caffe are accelerated using libraries of code running on GPUs. Similarly, in the world of network security, distributed virtual switching, routing, firewall, DOS, load balancing, other security and visibility frameworks are accelerated using libraries of code running on NFPs.

In summary, the need for security and visibility is becoming pervasive, and technologies such as DDoS protection and SSL or TLS decryption will need to be implemented in a distributed fashion using COTS and data center servers. In this paradigm, parallel processing using coprocessors is critical to ensure both network performance-related service levels and the efficiency of the servers. Similar to the use of optimized coprocessors like GPUs for AI, optimized coprocessors for network security will be a major force as the fourth wave of computing enables the world of IoT.
To enable re-configurable fabrics, we believe that the future of data center servers will have two co-processing planes – one for machine learning and AI, and one for networking and security. These co-processing planes will support innovative, multi-threaded programming environments that use the application-optimized features in co-processing silicon designed to deliver the best price-performance metrics for servers.
Nick Tausanovitch is vice president of solutions architecture at Netronome and is responsible for cloud data center applications of the company’s SmartNIC products. Tausanovitch’s passion is helping telecom and cloud service providers realize the promises of SDN and NFV while maximizing the efficiency of their infrastructure. Prior to Netronome, Tausanovitch was responsible for the high-end network processor product line at Broadcom and also director of electronic design at IDT, where he developed network search engines, and a system architect at Nortel, where he developed switches, routers, and network processors.




Be the first to comment