

There are a lot of different ways to skin the deep learning cat. But for hyperscalers and cloud providers who want to use a single platform internally as well as providing deep learning services to customers externally, they really want to have as few different architectures as possible in their datacenters to maximize efficiencies and to lower both capital and operational costs. This is particularly true when the hyperscaler is also a cloud provider.
If Moore’s Law had not run out of gas – or at least shifted to lower octane fuel – then the choice would have been easy. Processors would be increasing in speed as well as getting wider, networks and storage would keep up, and a homogeneous infrastructure like the cloud builders and hyperscalers have been assembling for more than a decade would be sufficient. But with the Moore’s Law pace in improvements in price/performance slowing, those who need to get the most work out of a unit of space and power have no choice but to make use of specialized components that are highly tuned for specific workloads. The trick, it seems, is to get something that is malleable enough to be used for a long time and to do different jobs, even those outside of deep learning.
This is why Microsoft has decided to employ FPGA accelerators in its infrastructure, and it is the foundation of its BrainWave deep learning stack, which runs atop the Catapult V2 hybrid servers that mix Xeon processors and Intel/Altera FPGAs and which we have described in detail here. With BrainWave, Microsoft Research has transformed its Catapult platform into a soft DPU, as it is called in the industry, and it stands in contrast to the deep learning ASICs, or hard DPUs, that are coming onto the market. Here is how Eric Chung, a researcher at the software and cloud giant’s Microsoft Research Next laboratory, characterized the landscape of deep learning hardware options in his presentation on the BrainWave effort at the Hot Chips conference in Silicon Valley this week:
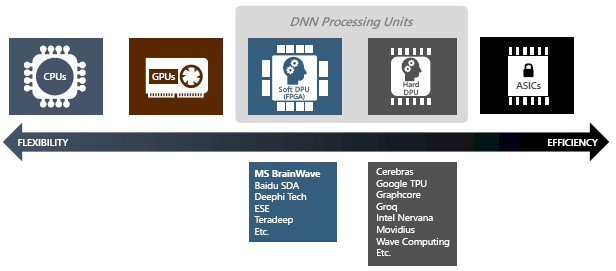
Hyperscalers and cloud builders are wrestling with a number of different challenges, and these all affect the hardware choices that they are making. As we all know by now, deep neural networks and the vast amounts of data that these companies have categorized and the even vaster amount they get from their users to further characterize, are fueling all kinds of speech recognition, video and image recognition, and question-answer services that they use to make their platforms useful and sticky. But, as Chung explains, the DNNs that drive these services are heavily constrained by cost, power consumption, and the latency of processing compared to the 200 milliseconds of a typical online interaction. Moreover, the size and complexity of DNNs is outpacing the growth in performance and the decrease in price/performance of commodity CPU clusters. And therefore, something has got to give and that is why we are seeing a Cambrian explosion in all kinds of processing, much of it related to neural networks.
“We want to be able to serve these models close to where the big data is, and we want to be able to serve it in real time,” Chung says. “We want to be able to ingest the search queries, the incoming text and speed, the sensor data, and do that at low cost with low latency and high throughput.”
The problem with all of the hard DPUs, which offer the promise of great efficiencies, is that those deploying them have to commit to specific operators and frameworks as well as data types, and the deep learning landscape is changing so fast that it is hard to make such a commitment. Moreover, companies are very likely going to need to use an ensemble of deep learning techniques even within a single workflow as well as across time, and that means they probably want more flexibility than a very specific hard DPU or even an ASIC can provide. (We would argue that providers embedded devices using AI, which have a limited range of function and technical and economic lifetime, will probably be eager for hard DPUs and ASICs because efficiency and power consumption will be the overriding factors.)
The soft DPUs based on FPGAs have not been widely deployed, but they offer the ability to change functions and the precision and type of math they do. Thus far, Baidu with its XPU, also unveiled at Hot Chips this week, and now Microsoft with BrainWave, are the two big proponents of this approach among the hyperscalers. There are others exploring this approach, too, such as DeePhi, the EIE effort at Stanford University, and Teradeep. Google has created the TPU family of chips, first to do inference with the TPU v1 and then to do both inference and training with the TPU v2. It will be interesting to see who is right in the long run, Google or Microsoft. Both have search engines, both sell scads of services (either directly or with ad support), and both have public clouds. It would be extremely interesting to know what Amazon is up to in this area.
Microsoft is betting on soft DPUs, and here is why, as Chung explains it:
“The conventional wisdom that gets floated around is that any type of soft DPU must necessarily be less efficient and less performant than hard DPUs. And while that’s certainly true if you took exactly the same RTL and you lowered it onto an ASIC, you would definitely see a gap. But that’s not necessarily the best way to actually harness FPGAs. So we can leverage the flexibility of the FPGA to adapt the microarchitecture exactly to the needs of the application and in some cases be able to close the gap between soft and hard DPUs and in some cases be able to exceed the effective performance that you get out of a hard DPU. And, with the FPGA, at design time you don’t have to commit to any specific design choices. You can make bold changes without worrying that you might have to take it out later or if you had the right start. And at Microsoft, we can leverage the fact that we have the world’s largest cloud infrastructure in FPGAs, and we can use our technology to run on the scale of that structure.”
How big that infrastructure is remains unclear, but Chung hints that Microsoft has an aggregate of multiple exaops of FPGA capacity in its infrastructure, and claims further that Microsoft has made the largest investment in FPGAs among the cloud providers.
For a refresher, here is how Microsoft integrates FPGAs into its Open Cloud Servers:

The latest machines have two 40 Gb/sec Ethernet ports on the FPGA mezzanine card so they can be networked together independently from the server nodes in which they reside while at the same time be linked to the CPUs in their host servers through PCI-Express bus and through the second Ethernet link.
The point is this: Catapult no longer just a science project that Microsoft Research cooked up to goose Bing searches. It is now a hardware platform, and BrainWave is the malleable deep learning platform (we are hesitant to call it either hardware or software because it occupies that area between the two as an FPGA) that compiles down to run on it and take advantage of its FPGA interconnect and the vast scale of CPU and FPGA resources that back the Azure cloud. We presume that many different workloads can run on this FPGA fabric, and that many other things aside from deep learning workloads atop the BrainWave soft DPU do, in fact, run on this iron. But we are also guessing that BrainWave is the most important workload on the massively parallel FPGA infrastructure, which has a service layer in the Azure cloud that looks like this:
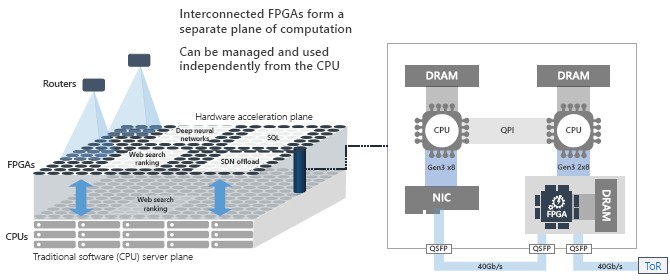
The funny bit is that the FPGAs are closer to the Microsoft network than the CPUs, and for the inferencing applications that Microsoft is running Microsoft is averaging a couple of hundred microseconds of latency and at worst case under 1 millisecond. “This is essentially invisible to the existing end software pipelines,” says Chung. “And further performance improvements in the hardware wouldn’t actually be quite as good for any gains for this particular model.”
There are some other reasons to pool the FPGAs in this fashion. If a workload does not fit into a single FPGA, either for compute or memory capacity reasons, it can be spread across multiple FPGAs and done so completely independently of the underlying CPUs in the servers. Moreover, with the FPGAs linking to the Microsoft Azure network directly, any processor in Azure can access any single FPGA or cluster of them running a DNN for inference. It also provides a better balance between CPUs and FPGAs and hardware and software. “What we often find is that hardware acceleration is so fast that if we take a one-to-one pairing of a CPU to an FPGA, the CPU cannot keep up,” says Chung. “So what we can do is actually oversubscribe CPUs to FPGAs and get better utilization of our datacenter.”
Still, all that this cleverly networked infrastructure outlined above gets you is the networked CPUs and FPGAs. What makes it useful for people creating neural nets is the Brainwave soft DPU, which Chung says is an adaptive soft processor that is optimized for real-time AI, and specifically for inferencing not for training.
The goal of the BrainWave stack is to take trained DNN models that are created using frameworks such as Microsoft’s CNTK, Facebook’s Caffe, or Google’s TensorFlow – yes, Microsoft uses other frameworks, and its Azure cloud customers will want to just as they want to run Linux on raw Azure infrastructure as much as they want to run Windows Server – and compiles those DNNs down so they can run on the BrainWave soft DPU that is loaded up onto the Stratix V, Arria 10, and now Stratix 10 FPGA from Intel that Microsoft puts into its servers. The neat bit is that the BrainWave soft DPU has an adaptive ISA that is completely parameterized and supports no particular kind or level of precision, integer or floating point, and in fact, it supports two homegrown formats called MS-FP8 and MS-FP9, which Chung would not elaborate on much on but which are from the name some kind of funky floating point that is not, strictly speaking, part of the IEEE standards. (Well, at least not yet.)
An ASIC or hard DPU is a fixed function device, and it can take years to crank through an updated chip, but Microsoft is able to create a new soft DPU, perhaps better suited to a larger and more powerful FPGA, in a matter of days to weeks. This is an important factor in platform choice, considering how fast the deep learning world, with new frameworks and algorithms, is changing.
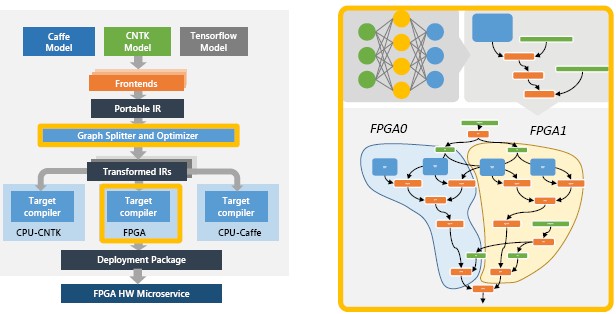
“The goal of our compiler is to take customer pretrained models, developed in CNTK or other frameworks, and seamlessly compile that down onto hardware microservices,” Chung explains. “So we take a model checkpoint, we lower that intermediate graph based representation, where we do graph rewriting, we partition that into tasks, we do optimizations, and then we schedule that across a set of different resources, spread on multiple FPGAs and CPUs. Finally, this is all tied together by what we call a federated runtime, which handles the marshalling and mediating of data as well as the scheduling. The entire goal of the BrainWave compiler is to be able to make frictionless, turnkey deployment of models on to distributed FPGAs without any knowledge of underlying hardware.”
It would have been funny if Microsoft never told its users they were using a soft DPU on an FPGA.
The BrainWave soft DPU is dominated by a matrix vector unit, just like the two TPUs from Google were and necessarily so since deep learning is really just about doing a whole lot of linear algebra. Jeremy Fowers, senior hardware engineer at Microsoft Research Next, explains that this soft DPU can scale to FPGAs that have more than 1 million adaptive logic modules (ALMs) and that on such a device, like the Stratix 10, a single SIMD instruction can invoke over 130,000 floating point operations in a cycle. (This was using the MS-FP9 format, we presume, which maps to the FPGAs very tightly.) This soft DPU uses a single-threaded C programming model to be tweaked, not the RTL common with FPGAs, and that is a neat trick, too. The narrow-precision data formats are wrapped in half-precision, FP16 interfaces, and the instruction set of the device, which is encoded in the logic gates of the FPGA, has lots of specialized functions that DNNs like, such as matrix vector multiplication, non-linear activation, convolutions, embeddings, and such.
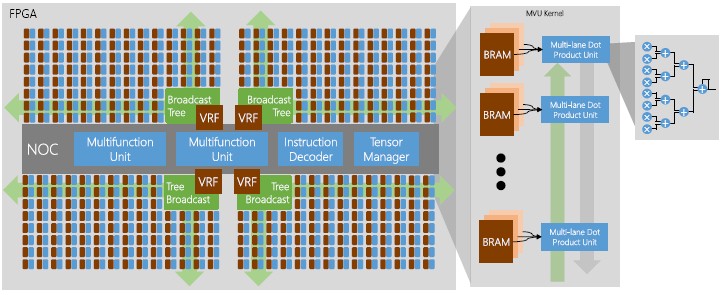
Here is what the block diagram of the BrainWave soft DPU looks like:
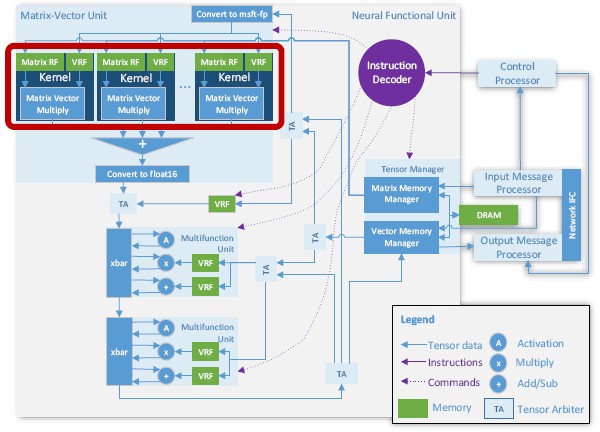
The matrix math unit dominates the gates on the FPGA, which is composed of an unspecified by what we presume is a large number of matrix kernels. These kernels are comprised of an array of hundreds of dot-product units, which are in turn made up of tens of lanes of multipliers and adders. Each dot-product has its own bank of FPGA RAM, and across the whole matrix multiply unit this memory has an aggregate bandwidth of 20 TB/sec. Yes, that is more than 20 times the memory bandwidth of an Nvidia “Volta” GPU accelerator card, and this is important for real-time inference.
There are also two multifunction units on the BrainWave soft DPU, and these do a bunch of different vectorized functions, such as sigmoids and dot-products, that are common with DNNs. Here is a drilldown into the matrix vector unit:
So how does this soft DPU perform? Microsoft was very careful to only show how it did when implemented on various FPGAs and using different math formats, and the effect various precision levels had on the accuracy of different DNN models.
Here is a performance comparison on Stratix V D5 and Stratix 10 280 FPGAs:
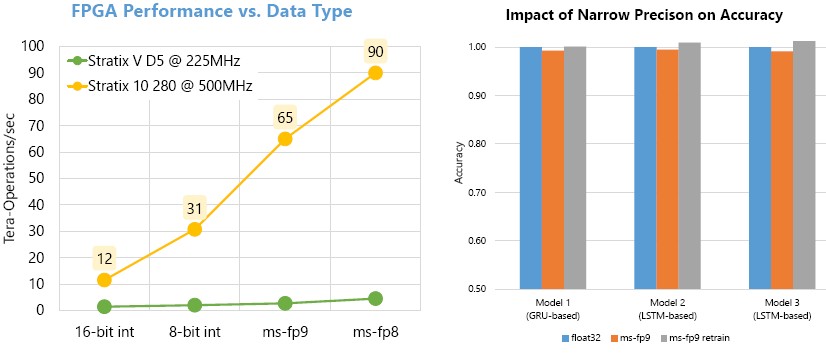
If the BrainWave soft DPU is running on a Stratix V D5 running at 255 MHz and using 16-bit integer formats, then it could drive 1.4 teraops on inference, and by shifting to 8-bit integer, the performance went up by 43 percent to 2 teraops. Moving to the proprietary MS-FP9 format drove it up further to 2.7 teraops, and shifting to the MS-FP8 format pushed it even further to 4.5 teraops. You begin to see why Microsoft, like other hyperscalers, are playing around with tiny numerical formats. This Stratix V FPGA was launched in 2011, and is a bit long in the tooth, and that is why we have shown it against the shiny new Stratix 10 280 FPGA, which is etched using Intel’s latest 14 nanometer technologies and packs a lot more gates and also clocks at 500 MHz.
When you implement the BrainWave soft DPU on this modern FPGA, the performance goes through the roof, hitting 90 teraops using the MS-FP8 format. And the accuracy of the DNN model is not appreciably impacted, as you can see.
Here is another set of comparisons, pitting the Arria 10 FPGA from Intel against the Stratix 10:
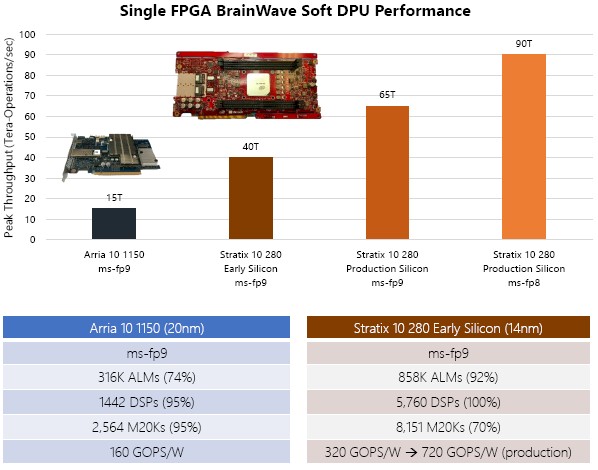
The shift to Microsoft formats and to the fatter FPGA is having a dramatic effect on performance, obviously, with the BrainWave soft DPU. And perhaps more importantly, the energy efficiency of the DPU is going up by a factor of 4.5X. (We would love to see the dollars per ops per watt calculation on this.)
It is important to note that all of these tests are run with batch sizes of one, not hundreds or thousands, and that means it is being done in real time. Batching up of inferences allows for the hardware utilization on the inference engine, whether it is a CPU, GPU, FPGA, or custom ASIC, to be driven up, but it kills latency because you always have to wait for each batch to finish before you can get an answer back. The trick Microsoft has to come up with is distributing inference requests across a wide number of devices and to keep each device as stuffed with requests as possible.
One way to do this is to get the CPU and its RAM out of the equation, and to persist the entire DNN model and all of its parameters in the distributed block RAM of the FPGA itself, and Microsoft is in fact doing this, creating what it calls “persistent neural nets.” This way, all of the resources of the FPGA and the soft DPU are focused on each single request as it comes in and dispatches it as quickly as possible. And if a DNN model doesn’t fit into a single FPGA, that’s fine. The FPGA fabric in the Catapult architecture lets it span multiple FPGAs with something on the order of a 2 microsecond hop latency.




So roughly 320 GOPS / watt?
Volta V100 does estimated 120 000 GOPS / 300 watts ( real world consumption would be lower) which yields 400 GOPS / watt, and its all done in software….
What is the motivation for this FPGA tech if its less efficient and less flexible?
So it does ~ 320 GOPS/ watt and a far more flexible GPU like V100 does ~400 GOPS/watt, what then is the USP for this?