

In our ongoing quest to understand the human mind and banish abnormalities that interfere with life we’ve always drawn upon the most advanced science available. During the last century, neuroimaging – most recently, the Magnetic Resonance Imaging scan (MRI) – has held the promise of showing the connection between brain structure and brain function.
Just last year, cognitive neuroscientist David Schnyer and colleagues Peter Clasen, Christopher Gonzalez, and Christopher Beevers published a compelling new proof of concept in Psychiatry Research: Neuroimaging. It suggests that machine learning algorithms running on high-performance computers to classify neuroimaging data may deliver the most reliable insights yet.
Their analysis of brain data from a group of treatment-seeking individuals with depression and heathy controls predicted major depressive disorder with a remarkable 75 percent accuracy.
Making More of MRI
Since MRI first appeared as a diagnostic tool, Dr. Schnyer observes, the hope has been that running a person through a scanner would reveal psychological as well as physical problems. However, the vast majority of MRI research done on depression, for example, has been primarily descriptive. While it tells how individual brains differ across various characteristics, it doesn’t predict who might have a disorder or who might be vulnerable to developing one.
To appreciate the role the software can play, consider the most familiar path to prediction.
As Dr. Schnyer points out, researchers might acquire a variety of scans of individuals at a single time and wait 20 years to see who develops a disorder like depression. Then they’d go back and try to determine which aspects of their neuroimaging data would predict who ended up becoming depressed. In addition to the obvious problem of long duration, they’d face the challenge of keeping test subjects in the study as well as keeping biases out.
In contrast, machine learning, a form of artificial intelligence, takes a data analytics approach. Through algorithms, step-by-step problem-solving procedures, machine-learning applications adapt to new information by developing models from sample input. Because machine learning enables a computer to produce results without being explicitly programmed, it allows for unexpected findings and, ultimately, prediction.
Dr. Schnyer and his team trained a Support Vector Machine Learning algorithm by providing it sets of data examples from both healthy and depressed individuals, labeling the features they considered meaningful. The resulting model scanned subsequent input, assigning the new examples to either the healthy or depressed category.
With machine learning, as Dr. Schnyer puts it, you can start without knowing what you’re looking for. You input multiple features and types of data, and the machine will simply go about its work to find the best solution. While you do have to know the categories of information involved, you don’t need to know which aspects of your data will best predict those categories.
As a result, the findings are not only free of bias. They also have the potential to reveal new information. Commenting on the classification of depression, Dr. Schnyer’s colleague Dr. Chris Beevers says he and the team are learning that depression presents itself as a disruption across a number of networks and not just a single area of the brain, as once believed.
Handling the Data with HPC
Data for this kind of research can be massive.
Even with the current study’s relatively small number of subjects, 50 in all, the dataset was large. The study analyzed about 150 measures per person. And the brain images themselves comprised hundreds of thousands of voxels, a voxel being a unit of graphic measurement — essentially a three-dimensional pixel – in this case, the image of a 2mm x 2mm x 2mm portion of the brain. With about 175,000 voxels per subject, the analysis demanded computing far beyond the power of desktops.
Dr. Schnyer and his team found the high-performance computing (HPC) they needed at the Texas Advanced Computing Center (TACC), hosted by the University of Texas at Austin, where Dr. Schnyer is a professor of psychology.
TACC’s machine, nicknamed Stampede, wasn’t some generic supercomputer. Made possible by a $27.5 million grant from the National Science Foundation (NSF) and built in partnership with Dell and Intel Corporation, Stampede was envisioned – and has performed – as one of the nation’s most powerful HPC machines for scientific research.
To appreciate the scale of Stampede’s power, consider its 6,400 nodes, each of them featuring high-performance Intel Xeon Phi coprocessors. A typical desktop computer has 2 to 4 processor cores; Stampede’s cores numbered 522,080.
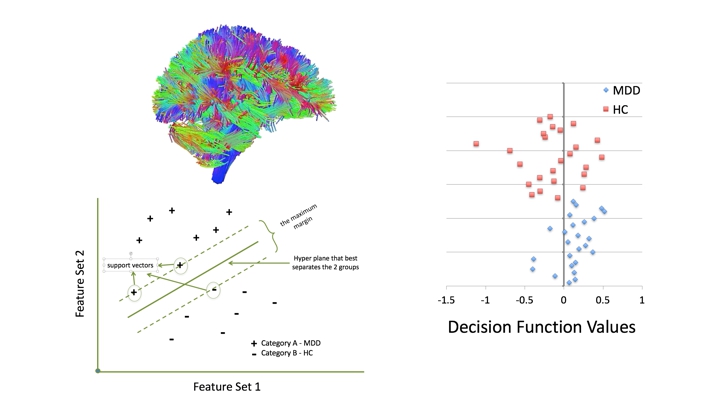
Bottom left panel – A hypothetical graphic application of support vector machine algorithms in order to classify 2 categories. Two feature sets can be plotted against one another and a hyperplane generated that best separates the groups based on the selected features. The maximum margin represents the margin that maximizes the divide between groups. Cases that lie on this maximum margin define the support vectors.
Right panel – Results of the SVM classification accuracy. Normalized decision function values are plotted for MDD (blue triangles) and healthy controls (HC, red squares). The zero line represents the decision boundary.
Moving Onward
In announcing Stampede, NSF noted it would go into full production in January 2013 and be available to researchers for four years, with the possibility of renewing the project for another system to be deployed in 2017. During its tenure Stampede has proven itself, running more than 8 million successful jobs for more than 11,000 users.
Last June NSF announced a $30 million award to TACC to “acquire and deploy a new large scale supercomputing system, Stampede2, as a strategic national resource to provide high-performance computing (HPC) capabilities for thousands of researchers across the U.S.” In May, Stampede2 began supporting early users on the system. Stampede2 will be fully deployed to the research community later this summer.
NSF says Stampede2 “will deliver a peak performance of up to 18 Petaflops, over twice the overall system performance of the current Stampede system.” In fact, nearly every aspect of the system will be doubled: memory, storage capacity, and bandwidth, as well as peak performance.
The new Stampede2 “will be among the first systems to employ cutting edge processor and memory technology in order to continue to bridge users to future cyberinfrastructure.” It will deploy a variety of new and upcoming technology, starting with Intel Xeon Phi Processors, previously code-named Knights Landing. It’s based on the Intel Scalable System Framework, a scalable HPC system model for balancing and optimizing the performance of processors, storage, and software.
Future phases of Stampede2 will include next-generation Intel Xeon processors, all connected by Intel Omni-Path Architecture, which delivers the low power consumption and high throughput HPC requires.
Later this year the machine will integrate 3D XPoint, a non-volatile memory technology developed by Intel and Micron Technology. It’s about four times denser than conventional RAM and extremely fast when reading and writing data.
A Hopeful Upside for Depression
The aim of the new HPC system is to fuel scientific research and discovery and, ultimately, improve our lives. That includes alleviating depression.
Like the Stampede project itself, Dr. Schnyer and his team are expanding into the next phase, this time seeking data from several hundred volunteers in the Austin community who’ve been diagnosed with depression and related conditions.
It’s important to bear in mind that his published work is a proof of concept. More research and analysis is needed before reliable measures for predicting brain disorders find their way to a doctor’s desk.
In the meantime, promising advances are happening on the software side as well as in hardware.
One area where machine learning and HPC are “a bit closer to reality,” in his terms, is cancer tumor diagnosis, where various algorithms classify tumor types using CT (computerized tomography) or MRI scans. “We’re trying to differentiate among human brains that, on gross anatomy, look very similar,” Dr. Schnyer explains. “Training algorithms to identify tumors may be easier than figuring out fine-grained differences in mental difficulties.” Regardless, progress in tumor studies contributes to advancing brain science overall.
In fact, the equivalent of research and development in machine learning is underway across commercial as well as scientific areas. In Dr. Schnyer’s words, “there’s a lot of trading across different domains. Google’s Deep Mind, for example, is invested in multi-level tiered learning, and some of that is starting to spill over into our world. The powerful aspect of machine learning,” he continues, “is that it really doesn’t matter what your data input is. It can be your shopping history or brain imaging data. It can take all data types and use them equally to do prediction.”
His own aims include developing an algorithm, testing it on various brain datasets, then making it widely available.
In demonstrating what can be discovered with machine learning and HPC as tools, Dr. Schnyer’s powerful proof of concept offers a hopeful path toward diagnosing and predicting depression and other brain disorders.
This article was produced as part of Intel’s HPC editorial program, with the goal of highlighting cutting-edge science, research and innovation driven by the HPC community through advanced technology. The publisher of the content has final editing rights and determines what articles are published.


Stampede3: A Smaller HPC System That Will Get More Work Done
All of the major HPC centers of the world, whether they are funded by straight science or nuclear weapons management, have enough need and enough money to have two classes of supercomputers. They have a so-called capability-class machine, which stretches the performance envelope, and a capacity-class machine, which plays an …

Leveraging Fat Nodes To Get Around I/O Bottlenecks
BioTeam, the famous HPC consulting practice, is using the quad-socket large memory nodes at the Texas Advanced Computing Center to speed alignment and HMM (Hidden Markov Model) inference workflows to find biological “synonyms” in biological databases like GenBank. This work gives hands-on bench scientists a collection of HMMs that reference …

Putting Composability Through The Paces On HPC Systems
With HPC and AI workloads only getting larger and demanding more compute power and bandwidth capabilities, system architects are trying to map out the best ways to feed the beast as they ponder future systems. One system design scenarios involves cramming as much stuff as possible onto the silicon, integrating …
Be the first to comment