

Moving data is the biggest problem in computing, and probably has been since there was data processing if we really want to be honest about it. Because of the cost of bandwidth, latency, energy, and iron to do multiple stages of processing on information in a modern application that might include a database as well as machine learning algorithms against stuff stored there as well as from other sources, you want to try to do all your computation from the memory of one set of devices.
That, in a nutshell, is what the GPU Open Analytics Initiative is laying the foundation for with regard to GPU-accelerated computing. The effort, which was gently nudged into being behind the scenes by Nvidia, includes as founding members MapD, the creator of one of the upstart GPU databases that not coincidentally is open sourcing its core database as part of the GOAI launch; Continuum Analytics, a creator of Python tools for GPUs; and H2O, which provides machine learning algorithms that run on GPUs. Others including BlazingDB, another GPU database maker, Graphistry, a provider of visual analytics tools, and the Gunrock project for graph processing at the University of California Davis, are contributing their expertise to the initiative.
The fact that MapD is open sourcing its GPU database is one of the reasons why the company is able to help create GOAI, which is pronounced “Go AI” as you might expect, and the company’s founder and CEO, Todd Mostak tells The Next Platform that when talks with Continuum Analytics and H2O started a few months ago, they kind of looked at MapD askance because it was not open code. Once Mostak explained that it was always his intent to open source the database, and that with the MapD 3.0 release that just came out a few weeks ago, the company’s programmers had worked to clean up the code from its “academic” earlier form so it could be opened up, then the talks got rolling.
The idea is to promote end-to-end computing on top of GPUs and, sorry Intel, but to keep as much of the processing off of CPUs as possible. This is consistent with our thinking that a convergence of machine learning and GPU database workloads on a single set of iron makes sense, as we discussed earlier this week and that we had been considering even before we caught wind of the GOAI effort.
The first project that the GOAI members are working on its called the GPU Data Frame, which Mostak says is loosely based on the Apache Arrow project. Spark has a concept of a data frame, and so does the Python NumPy analytics routines commonly used in analytics, and these are common data formats that would allow different parts of a composite application mashing up database, analytics, and machine learning functions to access the same data as it resides inside of the memory of GPUs. No transformation, no data movement. Just go. This is a lot more efficient, says Mostak, than MapD grabbing a dataset and performing a query against it to get a subset suitable for analysis and training, passing this result to the CPU, and then moving it to a buffer so tools such as the Anaconda Python framework or H2O for further use. The reason this works, Mostak explains, is that there are interprocess communications features embedded in CUDA, which he said he didn’t even know where there, which allows for this data to be shared across processes by passing handles.
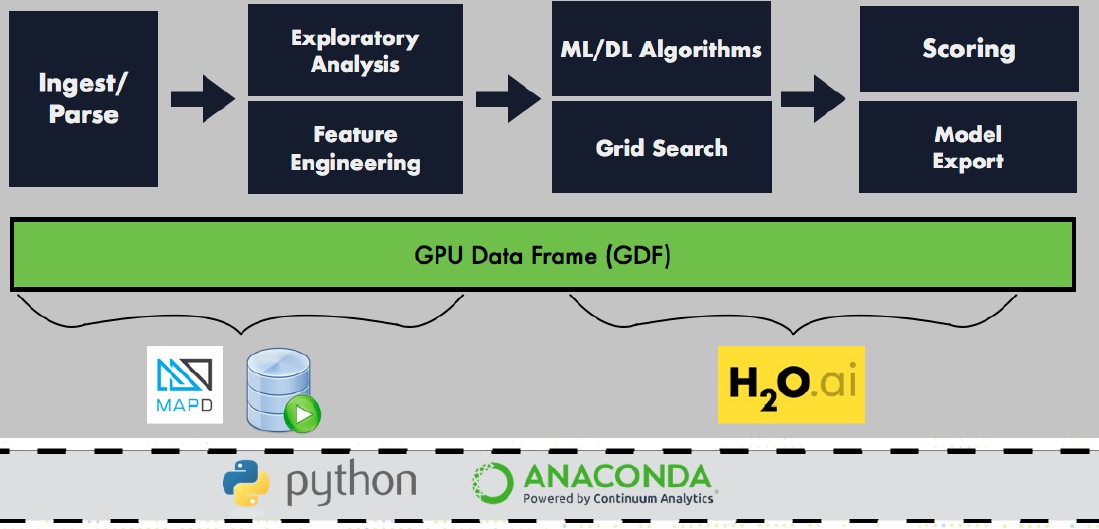
A working demo of this GPU pipeline was demonstrated at the GPU Technology Conference this week, where the MapD database was continuously querying a dataset with around a hundred queries, the Anaconda tool was used to manipulate and preprocess the data extracted by MapD, and this was fed into the H20 machine learning algorithms. The prior method involved a Spark in-memory cluster feeding data into H20 directly, and this GOAI setup was an order of magnitude faster in getting an answer across the whole pipeline.
The other interesting bit is how various machine learning frameworks can be integrated within GPU databases themselves, which both MapD and Kinetica are working on. One possibility for further integration would be for the GOAI members to take the TensorFrame data frame created to output tensor data formats from MapD directly to the TensorFlow machine learning framework created by Google. Similar approaches could be used to output data through a connector to other frameworks such as Torch, Caffe, Theano, and CNTK. This connector approach is how Hadoop was integrated with various data warehousing stacks some years back.
Mostak says that over the longer haul, MapD is interested in pushing the tensor formats used by machine learning frameworks directly into the database itself.
The Anaconda stack from Continuum Analytics is an open source platform that includes a bunch of tools but most importantly the NumPy compiler that crunches Python analytics applications so they can run in parallel on GPUs and the Conda installer for packing up applications for GPUs. The company has also created connectors for Hadoop clusters to seamless grab data from the Hadoop Distributed File System.
One of the goals of GOAI is not just having an integrated pipeline, explains Travis Oliphant, president and co-founder of Continuum Analytics, but such seamless integration between tools that they don’t even know they are not using a single analytics stack. The Python front end is something that is familiar to data scientists, who have widely adopted Python as their language of choice, but plenty still use the R statistical language, too. “We want this infrastructure to be just plug and play,” says Oliphant. “Coupling this all together is very powerful.”
Oliphant says that the three GOAI partners hope to have a preview release of their integrated stacks ready in a couple of weeks, with a usable version of their integrated code available sometime in September.
SriSatish Ambati, co-founder and CEO at H2O, says that while the company compiled machine learning algorithms that ran on CPUs in the early days, its focus is on running this code on GPUs, as is the case with hyperscalers who also use GPUs almost exclusively to train their machine learning models. That said, there is no reason that the code from any of the three partners can’t run on IBM’s Power chips or AMD’s impending Naples Opterons or even ARM processors for those elements that do require a CPU.
Incidentally, Ambati says that he expects that other GPU database providers will probably join up with the GOAI effort, with Kinetica and BlazingDB being the obvious ones. But no one from either company has made a commitment to do that as yet.
Opening Up The GPU Database
The Kinetica GPU database, formerly known as GPUdb, and BlazingDB, a relative newcomer to the GPU database space, are still closed source, but that may change quickly now that MapD has opened up the core of its GPU database.
With the machine learning frameworks and popular analytics tools all being open source, Mostak says that opening up MapD was not just natural, but necessary in the fullness of time. The company’s initial investors, who like to make money, were not precisely keen on opening up MapD, but when New Enterprise Associates was the lead investor in the company’s $25 million Series B round back in March, the mood shifted and going open was the course.
Like other open source products, MapD has a core, community, and enterprise edition, with these feature distinctions:

The MapD database is being launched with an Apache 2 license, which makes it very friendly with other open source code. The rendering engine and visual analytics that were layered onto the MapD database are not being open sourced, and neither are the high availability, distributed processing, and other enterprise-grade features that were part of the recent MapD 3.0 release. Companies can process pretty large databases on a single system with multiple GPUs these days, so this is a pretty good way to seed the market.

Be the first to comment