

Efficiently and quickly chewing through one trillion edges of a complex graph is no longer in itself a standalone achievement, but doing so on a single node, albeit with some acceleration and ultra-fast storage, is definitely worth noting.
There are many paths to processing trillions of edges efficiently and with high performance as demonstrated by companies like Facebook with its distributed trillion-edge scaling effort across 200 nodes in 2015 and Microsoft with a similar feat as well.
However, these approaches all required larger clusters; something that comes with obvious cost but over the course of scaling across nodes, latency as well. A team from Georgia Tech has demonstrated Facebook and Microsoft-class capabilities for graph processing, but without the heavy-handed cluster approach via MOSAIC, a graph processing engine that exploits all the hardware resources available in a standard Xeon host processor, Xeon Phi coprocessors, NVMe, and a fast interconnect.
As one of the leads, Changwoo Min, tells The Next Platform, even though terascale graph processing is no longer unheard of, finding ways to make it efficient and high performance is where the real research and implementation challenge lies. He points to the Microsoft work that spanned one trillion edges across a 64-node Infiniband connected cluster, but says with their single node on the same sized graph, the performance difference was only 1-2X slower on single-machine versus high-end cluster.
“For smaller graphs, MOSAIC consistently outperforms other state of the art, out of core engines by 32-58.6X and shows comparable performance to distributed graph engines. Furthermore, MOSAIC can complete one iteration of the Pagerank algorithm on a trillion-edge graph in 21 minutes, outperforming a distributed disk-based engine by 9.2X.”
The tile structure is also useful because of the way graph data is structured—it can be somewhat variable but capable of tight compression. At the high level, the four Xeon Phis on the node are crunching the edge processing via the tiles, which are essentially local graphs that use can use those many cores while the CPU merges the graph with its bigger, beefier (albeit fewer) cores. With four 61-core Xeon Phi cores in parallel and a clever ordering mechanism on the algorithm side among the concurrent accesses to tiles, “the host processors are able to exploit the locality o the shared vertex states associated with the tiles currently being processed, keeping large parts of these states in cache.” In other words, it is combining the best of both the in-memory single-node world without sacrificing performance.
MOSAIC was implemented in close to 17,000 lines of C++. As Min describes, “to efficiently fetch graph data on NVMe from the Xeon Phi, we extended the 9p file system and the NVMe device driver for direct data transfer between the NVMe and the Phi without host intervention.” He adds that for higher throughput, their architecture batches the tile reading process to use all of the available parallelism inside NVMe.
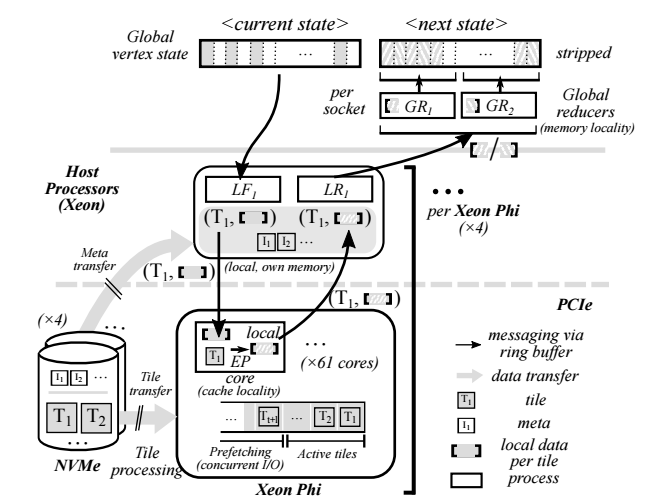
Although Min’s team uses Xeon Phi coprocessors, he says that this same concept can be applied to GPUs as well since it boils down to massive parallelism and a NUMA sharing framework fed by the quick interconnect and NVMe. He does say that with other approaches to using GPU as the accelerator for graph processing, the massive back and forth of data between the host and GPU set can cut down on what is possible in terms of performance scalability. Min says, “MOSAIC solves this problem by tunneling P2P DMA between the Xeon Phi and NVMes, which is the dominant data exchange path in out-of-core graph analytics.” They also ran a few of their graph benchmarks CPU-only, which is 2.1X slower overall (there is a table representing this in more detail).

As one might imagine, the single-node performance is impressive, but scaling this out to multiple machines can be a challenge. Min cites the main barrier, which is the PCIe bottleneck, especially since there are a number of devices attached. Despite the NUMA approach employed and other tricks, the team will also still be limited by relatively slow memory access in a Xeon Phi and on the other side, bottlenecks of NVMe throughput. Of course, these are temporary problems that can be addressed by using Knights Landing with and Intel’s own Optane NVMe, even if the PCIe bottlenecks continue.
Min says that continuing work will focus on the multi-node scalability problem as it relates to the newer hardware cited. The paper is exhaustive in detail and can be found here.


Giving Cloud Data Warehouses A Relational Knowledge Graph Overlay
The cloud has been a boon for enterprises trying to manage the massive amounts of data they collect every year. Cloud providers don’t have the same scaling issues that dog on-premises environments. But storing the data is only part of the problem. Pulling valuable business information from data housed in …
Graphing The Coronavirus Pandemic
Since late February and early March, when the coronavirus outbreak began to spill out of China in earnest and spread its sickness and death across Europe, throughout the United States, and into other parts of the globe, IT companies have stepped up to lend their technologies to fight the pandemic. …
What Would You Do With A 16.8 Million Core Graph Processing Beast?
If you look back at it now, especially with the advent of massively parallel computing on GPUs, maybe the techies at Tera Computing and then Cray had the right idea with their “ThreadStorm” massively threaded processors and high bandwidth interconnects. Given that many of the neural networks that are created …
On 2012 the GraphChi algorithm was able to process networks having billions of edges on a standard Mac laptop.
Check the paper for their explanation about how that isn’t in the same class.