

There is an arms race in the nascent market for GPU-accelerated databases, and the winner will be the one that can scale to the largest datasets while also providing the most compatibility with industry-standard SQL.
MapD and Kinetica are the leaders in this market, but BlazingDB, Blazegraph, and PG-Strom also in the field, and we think it won’t be long before the commercial relational database makers start adding GPU acceleration to their products, much as they have followed SAP HANA with in-memory processing.
MapD is newer than Kinetica, and it up until now, it has been content to allow clustering of multi-node GPU systems using the Boost middleware product from Bitfusion to compete with Kinetica on workloads that had to scale out beyond one fat node system with four, eight, or even sixteen GPUs linked together using PCI-Express or NVLink interconnects (or a mix of the two). MapD founder Todd Mostak told The Next Platform back in October last year that the company wanted a lower level, higher performing means of lashing together multiple nodes together than Boost, and with the MapD 3.0 release announced this week, MapD is making good on that promise.
The native scale-out feature of MapD is coming to market just as several of the big cloud makers have embraced GPU instances, and when Microsoft in particular is putting virtualized CPU-GPU servers on its Azure cloud linked by very fast InfiniBand links. But equally importantly, the scale out feature is timed as customers are looking to scale their GPU databases beyond 5 billion to 10 billion rows with sub-second response times, the limit of what they can cram into the GPU memory in a single fat node system. But even without those scalability requirements, the big customers adopting MapD for databases (like telecom giant Verizon, which is MapD’s flagship customer) wanted native clustering for high availability that would be based on the same interconnect.
It’s funny how scale quickly becomes an issue, and even vendors can be caught a little off guard by the increasing demands. MapD was founded with the idea that companies had large datasets, but they only needed to do fast queries and visualization against a portion of that data. As Mostak himself pointed out only last October, MapD did not have any aspirations to build something at hyperscalers like Google’s Spanner or Facebook’s Presto. But now MapD has one online real estate customer that has a database that is over 100 billion rows, and another hedge fund customer that is at that scale and is targeting a trillion row database. There is no easy way to do that in a single node, and hence the native scale add-ons coming with MapD 3.0.
The new scale out features that are part of the updated to MapD are actually just an extension of the sharding, load balancing, and aggregation that happens in a fat server node using PCI-Express or NVLink interconnects, only the metaphor is extended over the fabric interconnecting multiple nodes together. In general, complex queries are going to require reasonably low latency between nodes and relatively high bandwidth, but for all but the largest queries and very large datasets, perhaps with tens to hundreds of billions of rows of data, 10 Gb/sec Ethernet is okay and 40 Gb/sec Ethernet or InfiniBand is fine. The proprietary interconnect that MapD uses does not require the Remote Direct Memory Access (RDMA) feature of InfiniBand or its RDMA over Enhanced Converged (RoCE) Ethernet analog. The scaling technology created by MapD does not use the Message Passing Interface (MPI) protocol commonly used to scale out distributed HPC simulations, either.
The architecture that MapD has adopted is a familiar one for distributed databases and datastores, and is based on ideas that have been deployed in MemSQL or Vertica databases. Data can be sharded across chunks of GPU frame buffer memory (or any other storage media) and SQL queries can be broken up and run in parallel across those shards, and then the results can be combined together at the end of each individual query. (The MapReduce method invented for batch analytics by Google and embodied in the open source Hadoop project is a little bit like this, except the mapping functions – the query bit – are only sent to the shards of data where the query needs to run and the answers are aggregated and reduced in a batch mode. It’s not a good analogy, mind you.)
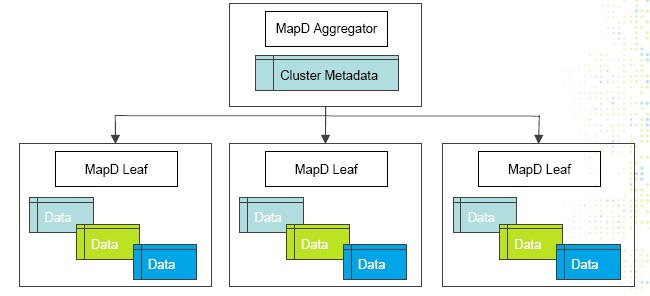
The neat thing about scaling up parallel databases that makes them distinct from other kinds of workloads is that you can actually have a hierarchy of processing, whether that processing is accelerated by GPUs or not, with aggregations at several levels and an ultimate aggregation where the answers to a query all come home. For the moment, as the diagram above shows, the scale out implementation of MapD has two levels, with multiple MapD leaf servers chewing on subsets of the sharded data and being controlled by a cluster metadata server and an aggregator that brings all of the partitioned queries back together. But you could take a Russian doll approach and add layer after layer, building clusters of clusters to scale it up even further rather than try to scale it all out on one cluster. (This might be useful when you know you are usually going to query one part of the data but sometimes want to run a query against all of the data every now and then.)
This is not as hard as it sounds because MapD was already architected to run in parallel across multiple GPUs inside of a box, all holding a portion of the database. The same abstraction layer that was used to chop up the data on each GPU and parse out queries to them over the PCI-Express or NVLink fabric were extended to run over the network fabric hooking the servers. Like this:
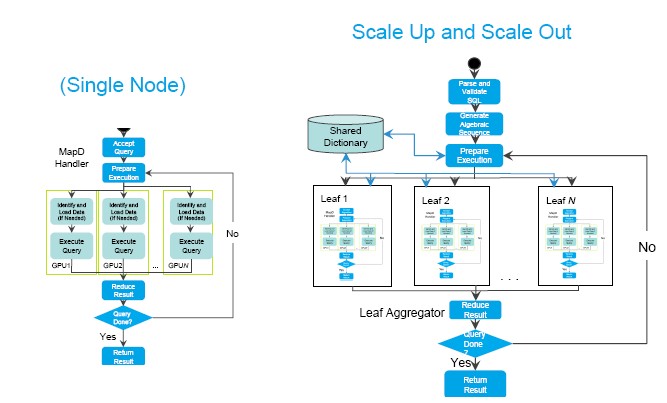
The big change in the architecture is that now there is a shared dictionary to keep all of the data in synch across the leaf servers and their underlying individual GPUs. As far as we know, companies can mix and match different generations of GPUs across these clusters, which offers a kind of investment protection, but there are probably good Amdahl’s Law and predictable response reasons to try to run the MapD database on the same cluster nodes if possible.
The MapD database can take advantage of whatever in-server and cross-server interconnect that is in the box, and the choice of interconnect is really driven by the amount of data and the complexity of the queries that companies run. “If you are using a GPU accelerated database, you are all about response time, and so you probably want to maximize the bandwidth and minimize the latency between the nodes,” Mostak explains.
For modest datasets and simple queries, a 1 Gb/sec Ethernet link would work, says Mostak. (If you can find one on a modern server these days that is not the management port.) But once you start doing more complicated queries, particularly ones where you have to do repeated waves of aggregation and sending it back out to the leaf servers, then having at least 10 Gb/sec or 40 Gb/sec Ethernet or 40 Gb/sec InfiniBand can be a big help. If all you have is 10 Gb/sec Ethernet ports, you can band a bunch of them together to create a 20 Gb/sec or 40 Gb/sec link between nodes, and you can get to 25 Gb/sec or 50 Gb/sec and even 100 Gb/sec for Ethernet ports on servers, which is getting pretty close to the bandwidth that the CPU can push out of the peripheral controllers.
“In the future, we may do inter-GPU reduction between nodes over InfiniBand with RDMA or Ethernet with RoCE for maximizing performance, but we have not done that optimization yet. Sometimes, you can’t be didactic about this and you have to conform to what the customers have in their datacenters or what is available in a public cloud. For instance, AWS does not have InfiniBand. We have done a lot of work with the multi-node feature to compress the data as much as possible to come up with a very efficient binary wire protocol because you never know what you will have between the nodes. It is always good to use the bandwidth that you do have as efficiently as possible.”
The natural thing to ask is how sensitive a distributed GPU-accelerated database is to network bandwidth or network latency. The latencies are getting down to 100 nanoseconds or so for InfiniBand and Omni-Path and maybe 300 nanoseconds to 400 nanoseconds for Ethernet – and it will be hard to get any of them to get much lower. Bandwidth is commonly available at 100 Gb/sec for Ethernet, InfiniBand, and Omni-Path at reasonable prices. InfiniBand is pushing ahead to 200 Gb/sec right now from Mellanox Technologies and is on a two-year upgrade cadence, and there is even 400 Gb/sec Ethernet on the horizon from upstart Innovium and 200 Gb/sec Omni-Path is expected maybe next year from Intel, too. The bandwidth boost and latency shrink matter for many traditional HPC simulation workloads, to be sure.
“A database is much more bandwidth sensitive,” says Mostak. “Even a gigabyte of result set data can become tens to hundreds of milliseconds over a relatively slow connection. It really depends on the workload, but bandwidth is going to be the main driver of performance. Even though MapD is very fast, you are still talking about tens to hundreds of milliseconds for these big SQL queries to run. For a lot of Ethernet networks, you are in the microseconds range, which is low enough, but also, you are ponying up for a lot of GPU iron, so don’t put 12-inch tires on your Ferrari, either. A lot of people are as interested in price/performance as they are in price/performance, and we deliver somewhere between 50X and 100X the bang for the buck of Vertica, Spark, or Redshift databases. So I am not saying we cost like Ferrari. For a modest cost we can beat the performance of a hundred nodes running the Impala SQL layer on top of Hadoop, for instance.”
The scale out feature of MapD does not, in theory, have any limits, but Mostak says this is the first release and there is more tuning to be done to squeeze all of the performance out of it. Here is a test that was run on a single instance and then a pair of instances on the Amazon cloud:
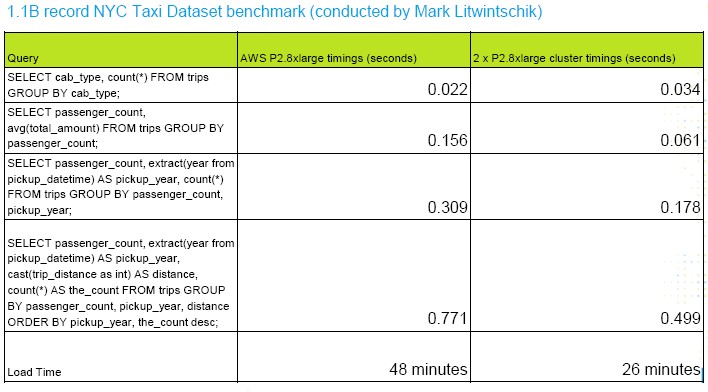
There was a little less than a 2X speedup with a pair of instances, as you can see. The load times for data have a 2X speedup, too, because the sharded data is loaded in parallel, and this is a big deal for customers. You can speed up the load on a consistent dataset as you scale, or scale the dataset and load in the same time, or do something in between.
MapD has tested its code on four and eight mode clusters, and the goal with this release was to be able to scale across one or two racks, which is somewhere around the 100 billion to 200 billion row mark for the GPU database, which equates with the high 10s to the low 100s TB range for dataset sizes. This is the sweet spot for what customers have been asking for. Mostak says it is not a good idea to have more than 20 or 30 nodes on a single head node, and it will do multi-level clustering to scale beyond this to reach that 1 trillion row mark and petabyte range that its hedge fund customer – and probably soon others – is looking to support.
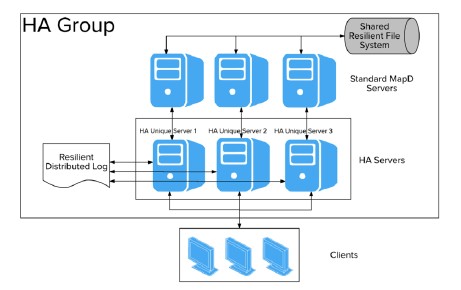
The MapD database is priced by the number of GPUs in the system and cluster, and the scale out features are including in the 3.0 release as part of the upgrade and do not carry an additional charge. MapD is also adding a high availability option, which uses the Gluster clustered file system to house the touchstone copy of data in the GPU memory and uses Kafka to segment and stream updates between pairs of GPU servers or clusters and the Gluster file system. This is based on the open source Kafka and Gluster code and does not require licensing software from Confluent or Red Hat.
Additionally, the update has a native ODBC driver, which is licensed from Simba Technologies just like rival Kinetica and a slew of data warehouse and database suppliers do.


Ampere DGX Servers Pack A Wallop, Including AMD Epyc CPUs
A new CPU or GPU compute engine is always an exciting time for the datacenter because we get to see the results of years of work and clever thinking by hardware and software engineers who are trying to break through barriers with both their Dennard scaling and their Moore’s Law …
Crafting A DGX-Alike AI Server Out Of AMD GPUs And PCI Switches
Not everybody can afford an Nvidia DGX AI server loaded up with the latest “Hopper” H100 GPU accelerators or even one of its many clones available from the OEMs and ODMs of the world. And even if they can afford this Escalade of AI processing, that does not mean for …
The AMD “Aldebaran” GPU That Won Exascale
If you want to know how and why AMD motors have been chosen for so many of the pre-exascale and exascale HPC and AI systems, despite the dominance of Intel in CPUs and the dominance of Nvidia in GPUs, you need look no further for an answer than the new …
GPU accelerated SQL databases and analytics are the next best target markets for GPUs…
I think you mean Confluent, not Concurrent.
Correct! Slipped a cog and fell back in time 30 years….
MapD 3.0 may be very fast for the right workload – but it’s not clear from the published NYC taxi benchmark results if that’s really the case.
Out of curiosity I run the same 4 NYC taxi queries on a single small EC2 node ( i3.2xlarge – 4 CPU cores and 60GB of RAM; it cost ~ $0.10/hr spot) with 1.3 billion rows of data using Vertica 8.0 database – and total time was ~75 milliseconds (15 + 10 + 15 + 32 msec) i.e. about 10 times less than with MapD 3.0 that was using much faster/more expensive dual p2.8xlarge GPU nodes.
How about some real benchmark results – like TPC-H or TPC-DS?
I am very curious how you got these results on Vertica. On version 8.0.1 Mark Litwintshik got times of 14.4, 32.1, 33.4, and 67.3 seconds respectively on the same queries. Obviously more RAM might have helped but there is a three-order of magnitude discrepancy between his results and yours. Moreover, getting a result of 10 ms for the second query would nominally require 800 GB/sec of bandwidth, roughly 10X the theoretical max of that system you tested on. (Vertica can compress well but not that well. Either Vertica is pre-computing heavily or your results aren’t correct.
When making comments like this please at least use believable numbers next time.
Mark Litwintshik did not define/build ANY projections to speed up those 4 queries so his queries were doing full scan of relevant columns + aggregation.
That’s NOT how Vertica is used (or at least supposed to be used) if you want to get good performance.
I’ve used live aggregate projections to get results I reported (and they were what they were regardless of what you believe – or don’t believe – in; if you’re indeed a DB geek as your handle implies you should at least be familiar with DB technology you’re commenting on before claiming that something isn’t true or impossible).
Table I used was partitioned by year (query results for unpartitioned table were slightly better). My approach will also easily scale to 10s of billions of rows on 1 server (using bigger i3 instance for more disk space and to speed up data loads) or 100s of billions of rows on a cluster for such queries.
Of course, NYC taxi queries is a TOY benchmark (single table and really simple queries with no joins etc) – and that’s exactly why I’ve asked for results from a real benchmark (where I expect MapD to perform relatively much better). Running something like TPC-H or TPC-DS would involve much more work and therefore should be done by MapD or some team with enough time/hardware to do it right.
As I mentioned, effectively pre-aggregation. Good luck trying to run ad-hoc queries with ad-hoc filters with your live aggregate projections, i.e. there’s no free lunch.
If Vertica could run every ad-hoc query in 10ms then the whole world would be using Vertica. Stop trying to compare apples-to-oranges.
When MapD CEO Todd Mostak makes bold claims like “…we deliver somewhere between 50X and 100X the bang for the buck of Vertica…” he should provide some serious evidence of that – and NYC taxi queries are definitely not it (as I’ve proved beyond any doubt – see above).
I’m not comparing apples to oranges – I’m comparing 2 relational DB engines on the same data using same queries.
And I didn’t choose this data or those queries – MapD apparently did (or at least was happy with this choice since they’ve mentioned similar results for the same “benchmark” for previous MapD release as well).
DISCLAIMER I do not work for or on behalf of or against any DB vendor (including Vertica and MapD) and I do believe that use of GPUs in databases has a lot of potential – but making unsubstantiated (so far) claims about price/performance will not help MapD credibility.
@Igor – Its really not fair to query materialized view and compare to online computation 🙂 or its important to mention that you will really waste lot of space the more query you have and you want them be super fast which enforces you to provide for each specific projection 🙂
Why would this benchmark not be considered “real”? I’ve conducted it on a wide variety of software, hardware and cloud services. I document every step involved in getting the benchmarks up. The results often show large gaps in performance between the different data stores I’ve benchmarked.
I might not run a test suite that hits every line of code in every database but when there is a 100x difference in speed between databases in the top 10 of my rankings board there isn’t much of a reason to.
The TPC-* benchmarks are aimed at OLTP data warehouses for the most part where a key feature is being able to update records at random. They’re focused on databases that are good at OLTP (as well as OLAP workloads in some cases).
In the datasets I work with on a daily basis they’re at a size that anything other than append-only storage just isn’t going to scale in a cost effective manor. Aggregating on billions of records that are usually less than a few days old is a very common task with my clients and that is the workload my four benchmark queries focus on.
NYC taxi benchmark is useful (and it’s very nice that you and others have published all or most steps needed to reproduce those results using different DB products and hardware platforms).
However, until it’ll use more than one table and have some queries with joins it’s just not representative of many/most workloads that I’ve seen which are worth paying mid 6- to high 7-figure $ amount for (and that’s what DB server/cluster – including MapD – will usually cost over 3-5 years on-premises or in the cloud).
Have a look at SQream DB and Blazing DB which /can/ handle Joins quite easily because they’re not focused strictly on in-memory.
I disagree here about TPC is not right for analytical load, actually TPC-H with its star schema (I tested it on Postgres/Oracle back in time) and on Alenka – SQL ANSI compatible GPU accelerated db prototype:
https://github.com/antonmks/Alenka
I just expect I will need to clean up CREATE TABLE scripts from Primary/Foreign keys and maybe I will replace values of some strings to integers (for enumerations like country code name, etc.) – case with OmniSci.
I think that Todd and the crew did a fantastic job going in a very short time from nothing to a promising smart product.
Looking forward for the next iteration might be container base I hope.
> There is an arms race in the nascent market for GPU-accelerated databases, and the winner will be the one that can scale to the largest datasets while also providing the most compatibility with industry-standard SQL.
In that case, there is only one clear leader – and that’s SQream DB which you failed to mention.
You /did/ mention PG-Strom – which is an academic project. You also mentioned Blazegraph – which is not an SQL database by any measure.
You really went out of your way to only focus on MapD while ignoring the actual leaders in this space.
Thanks again to Mark, who gave me some navigation as I am at moment testing OmniSci. The issue with SQreamDB vs OmniSci (MapD) is that I have out of box: github repository with full source code, limited to single multi gpu node, I have docker images and lot of demos available, so the setup is deadly fast for evaulation. On SQreamDB the website is full of advertising like statements, but no links to real benchmark, offloads, etc.
But I will give a try in TCP benchmark, why not. I have even written my own heavy parallel CSV data generator which supports single or multi table setup, will release it on my github once finalized as I got task to explore the best GPU real time analytics on the market 🙂