

It is difficult to shed a tear for Moore’s Law when there are so many interesting architectural distractions on the systems horizon.
While the steady tick-tock of the tried and true is still audible, the last two years have ushered a fresh wave of new architectures targeting deep learning and other specialized workloads, as well as a bevy of forthcoming hybrids with FPGAs, zippier GPUs, and swiftly emerging open architectures. None of this has been lost on system architects at the bleeding edge, where the rush is on to build systems that can efficiently chew through ever-growing datasets with better performance, lower power consumption, while maintaining programmability and scalability.
Yesterday, we profiled how researchers at Oak Ridge National Lab are scaling deep learning by dividing up thousands of networks to run on over 18,000 GPUs using an MPI-based approach. As we discussed, this effort was driven by HPC’s recognition that adding deep learning and machine learning into the supercomputing application mix can drive better use of large wells of scientific data—and bolster the complexity and eventually, capabilities of simulations.
One of the researchers involved in that companion effort we described to create auto-generating neural networks for scientific data took neural network hardware investigations one step further. Thomas Potok and his team built a novel deep learning workflow that uses the best of three worlds—supercomputers, neuromorphic devices, and quantum computing.
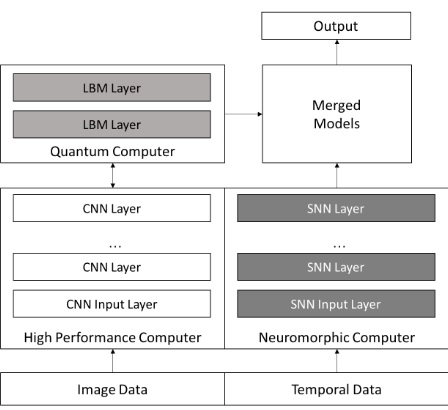
At a high level, they evaluated the benefits of all three compute platforms (we’ll get to those in a moment) and found that they could use HPC simulation data as the baseline for a convolutional neural network generated using their auto-network tools on the Titan machine, then shift elements of that network to the quantum (using the 1,000 qubit machine at USC/Lockheed) and neuromorphic (developed at ORNL and described here) devices to handle the elements they are best at handling.
It is difficult to compare the performance of HPC, quantum, and neuromorphic devices on deep learning applications since the measurements are different—as are the areas where each excel. A quantum system can provide deeply connect networks and a greater representation of the information without the computational cost of conventional machines, Potok says, but again, they cannot span the entire deep learning workflow in the way ORNL envisions it with the HPC layer.
Neuromorphic devices, particularly those with a spiking neural network like the one developed at ORNL (DANNA) can take some of the offload of neural networks that incorporate a time series element. In other words, the HPC simulation and origin of the network can be done best on a supercomputer, the higher order functions of a convolutional neural net can be addressed by a quantum machine, and the results can be further analyzed with a temporal aspect from neuromorphic devices.
“With scientific data you often have imagery that has a time aspect. You have a sensor with a particle that interacts with is. With neuromorphic, we can take the standard convolutional neural net and have complementary spiking neural networks that work on the time element of the data or experiment. We can use those in an ensemble to be able to look at the problem not only from a locality aspect in the image—but temporally as well.”
“Three or four years ago when we started looking at all of this, Andrew Ng and others were trying to scale neural networks across nodes. The problem was, people were not having much luck scaling past 64 nodes or so before the performance gains went away,” Potok explains. “We took a different approach; rather than building a massive 18,000 node deep learning system, we took the biggest challenge—configuring the network, building the topologies and parameters, and using evolutionary optimization to automatically configure it—we made it an optimization problem.”
“Hyperscale companies have been able to do things like label images automatically or recognize speech, but there are a lot of people working on these networks. In HPC, there are a lot of datasets but there are not a lot of people working on them—and even fewer who understand them,” says Potok. “Trying to build a deep learning network that works there would be laborious; that’s where HPC comes in. We can fairly quickly tailor a deep learning network to a new dataset and get results quickly. And what is most important is that it is scalable on Titan, and then to Summit or an exascale machine.”
All of this might sound like a major integration challenge with so many data types working toward the same end result—even if the inputs and outputs are generated as steps in the overall problem on distributed networks. Potok says the above shown architecture does work, but the real test will be merging the CNN and spiking neural networks to see what results might be achieved. Ultimately, the biggest question is just how hybrid architectures will need to be to sate compute and application demands. It will be beneficial to have a new, more robust, scalable, way to create more complex results from simulations, but there is a lot of overhead—and on devices that are not yet produced at any scale.
Big theory work is part of what national labs do best, of course, but this could move beyond concept in the next generations of machines. Potok doesn’t see such a massively hybrid architecture in the next five years, but does think all three modes of computing hold promise in the next decade. For example, he says, if you look at a field like material science where there is an image of a material at the atomic level (with its associated terabytes of data), what new things could be learned from systems that can take this data, learn from it as a static and temporal record, and then create entirely new ways of considering the material. In other words, not only will the compute platform be new, so too will be the ways problems are approached.


Alibaba’s Key to Cryptosecurity is Its Own Quantum Platform
Like all hyperscalers, Alibaba has been carving its own path through the early quantum computing landscape, starting with a cloud-based service rooted in their own 11-qubit quantum system along with simulators, including one 32-qubit that is available as a service with demonstration of a 64-qubit simulator via work with the …

Intel’s Neuromorphic Chip Just Got More Accessible for Mainstream AI
While the promise of neuromorphic computing going mainstream is still mostly unrealized, there are steps being taken to bring it closer to reality. Spiking neural networks (SNNs) have potential, especially in inference, for far lower power consumption and good performance for certain applications in ML but mapping these problems onto …

What Are Quantum Hardware Startups Thinking?
Atom Computing adds itself to a growing list of quantum systems makers with pedigreed founders, funding announcements, and a market that even the big players haven’t mastered. With no acquisition/cash-out goals apparent, no established market to chase, and competitive differentiation so nuanced, what’s the game? If the last five years …
I guess on this grant scale it s new, but overall the approach is not really, people have recently already been using Reinforcement Learning or genetic algorithms to create DNNs. Much smarter would be to build Layers in the neural network that adopt more universal instead of having to build and train a whole network for adopting.