


With absolute dominance in datacenter and desktop compute, considerable sway in datacenter storage, a growing presence in networking, and profit margins that are the envy of the manufacturing and tech sectors alike, it is not a surprise that companies are gunning for Intel. They all talk about how Moore’s Law is dead and how that removes a significant advantage for the world’s largest – and most profitable – chip maker.
After years of this, the top brass in Intel’s Technology and Manufacturing Group as well as its former chief financial officer, who is now in charge of its manufacturing, operations, and sales, pushed back today with its first event dedicated explicitly to its chip factories and the processes they use to etch devices. They went to great lengths, with real data and competitive analysis, to show that Moore’s Law was not dead. But even Intel has to admit that things are getting more difficult and that describing the progress in price and performance of circuits is not as simple as it once was.
Moore’s Law, of course, refers to an observation that Intel co-founder Gordon Moore made in 1965 that the cost of transistor manufacturing would come down exponentially, being cut in half every 18 months, and therefore the complexity and performance of circuits would rise at a predictable pace – and importantly in a way that would allow companies to make some money as they rode up the performance curve and rode down the manufacturing cost curve. Moore updated his “law” in 1975 to say the cost of transistors would be cut in half, and the density would double, every two years.
We have hit a lot of bumps since 2000, when Intel started the transition of chip manufacturing at 180 nanometers on 200 millimeter wafers to 130 nanometers on 300 millimeter wafers; we are still stuck on 300 millimeter wafers at the moment and have not moved ahead to 450 millimeter wafers or ultraviolet lithography, both of which have their issues and require enormous retooling and cost, but to Intel’s great credit, it has been able to tweak and fiddle, doping circuits with copper, high-k metal gates, and myriad other technologies, to keep on the economic trend embodied in Moore’s Law. That has required giving up on increasing clock speeds – remember the roadmaps with 10 GHz processors? – and adding a complex memory hierarchy onto a parallel compute complex. Instead of getting faster computers that can do one thing really quick, we have what are in essence many computers that can do lots of things, sometimes one thing chopped up, in parallel fashion.
It is safe to say that the transition to 14 nanometer processes has been a trying one for Intel, and the subtext in the Technology and Manufacturing Day briefing that Intel gave – the first of its kind – is that Intel has a handle on this and will be able to continue to innovate, not just in process technologies, not just in processor architecture, but also in packaging and other factors that drive up performance and, we hope, sometimes drive down system price. But don’t hold your breath on that last bit. . . .
Intel says that it is not just scaling, but it is hyperscaling, borrowing a term that is already used to connote the very large infrastructures built by Google, Microsoft, Amazon Web Services, Facebook, Baidu, Tencent, Alibaba, and China Mobile. Hyperscaling means adding other kinds of innovation above and beyond process – including changes to how circuit components are laid out – to free up more area to dedicate to transistors. All of this is to fight against the inevitable fact that the machinery in each successive process shrink and the multiple iterations of lithography are more expensive and therefore each wafer is more expensive to deliver. If you cram enough transistors on the wafer, you can stay on the Moore’s Law curve, which was updated to a new process node and a doubling of transistor density every 24 months or so back in the 1980s and which is now looking more like three years.
Moore’s Law might not be dead, but it sure is different. And the situation is a lot more complex than the tick-tock method, invented by former Intel Enterprise Group general manager Pat Gelsinger (now chief executive officer at VMware) of shrinking process with one generation of chip and then making microarchitecture improvements in the next generation. Intel is going to be squeezing three generations out of each process as well as making microarchitecture improvements and will mix and match them so that on an annual cadence it will deliver new chips to the market with performance improvements. How it pushes down or pulls up on those levers will depend on a lot of factors, and how this affects future products in the Xeon and Xeon Phi processors, Stratix and Arria FPGAs, and Omni-Path switch chips, will be something that we will discuss in detail. There is a lot here to think about.
“To make products less expensive, year in and year out, is really our core competitive advantage,” explained Stacy Smith, executive vice president of manufacturing, operations, and sales. “It is a huge driver of our business, and it is a huge driver of the worldwide economy. It allows us to connect and to play, and Moore’s Law allows us to solve some of the biggest problems on the planet.”
Smith said he was in Intel’s factories back in 1990, when visible light lithography was still being used to etch chips, and at the time the “insurmountable technology wall” that no one thought the chip industry could break through was using to shorter wavelengths. “In reality, it was not even a blip on the Moore’s Law cadence. The reality is, we are always looking out five years, and we have good insight into how we solve the problems in the next five years, and there is almost always the view ten years out that we are not going to be able to solve the problems. But when we get there, we do solve those problems.”
The immediate problem is not whether Moore’s Law is dead, it is whether Moore’s Law is moving smoothly ahead at a steady, predictable pace. Each process shrink has started to take longer and is more physically intense to deliver, and there are some real physical issues that have to be dealt with. The gaps are getting wider in time, and there is a rather severe impedance mismatch between organizations that have annual budgets and process shrinks that are now taking three years per node and could stretch even further in the future. Intel has to sell something new every year, and its new manufacturing cadence will allow for its desktop and server units to get on a more regular schedule – something we proposed it do in July 2015 when it said the Moore’s Law cadence in process shrink was now three years, not two or two and a half.
Over the long haul, perhaps a very long haul indeed, the real question is whether CMOS chips and von Neumann architectures are dead – but that is a topic for another day. Maybe a whole month of days, in fact.
Moore’s Law, By The Numbers
The real purpose of the Technology and Manufacturing Day was for Intel to argue that it has not lost its much vaunted process lead when it comes to chip making, despite the fact that Qualcomm has put ARM-based Snapdragon client and Centriq 2400 server chips into the field using 10 nanometer processes. (The server chips are only sampling, mind you, but Microsoft has adopted them for a chunk of its Azure cloud and ported Windows Server Core to them.) Intel’s argument is that the naming conventions, based on gate dimensions, for various manufacturing processes – only those from Globalfoundries, Samsung, Taiwan Semiconductor Manufacturing Corp, and Intel matter. They are the last of the big chip foundries with leading edge processes – and Smith reminded everyone that back in 2003, there were 25 such players, a number that was cut in half by 2012 and that will probably lose one more at some point. Maybe.
In a sense, Intel put itself on trial and argued its own case that Moore’s Law continues to operate in its business, and at the same time called into question the density improvements that its rivals in the fab business are able to bring to bear on behalf of its rivals in the chip business. Intel went into detail not only how its processes are yielding density, but in the numerous ways it has innovated to get more circuitry into each process. The 3D FinFET transistor is but one innovation in a long line, which Mark Bohr, an Intel Senior Fellow and director of process architecture and integration, explained were all copied by the chip industry around three years after Intel introduced them:

It is these innovations, coupled with the process shrinks people usually think about when they talk about Moore’s Law and that are implied by Moore’s Law, that allows the real Moore’s Law – cutting the cost of transistors down by half every two years – to operate. We will be getting into the advances employed in the latest 14 nanometer and 10 nanometer processes and how they might be deployed for future Xeon and Xeon Phi processors in a follow-up article. For now, let’s just walk through the data on Moore’s Law.
As the chart above shows, in terms of innovative chip design and manufacturing processes, Intel reckons it has a three year lead on the best of the competition, whoever that is at the time, and it expects to continue to have that lead for the foreseeable future.
The traditional way of measuring logic area scaling, explained Bohr, was to measure the gate pitch in a transistor and multiply it by a NAND logic circuit’s cell height. (This NAND is not the same NAND we refer to in flash memory, but the way a NAND logic circuit is implemented.) If you do that, the traditional logical area scaling was a factor of 0.49 per generational jump. But Bohr says this methodology of measuring the effectiveness of each process shrink is not sufficient, and instead, he wants the industry to revert to a method that takes the area of a NAND circuit and adds it to the area of a complex scan flip-flop logic cell and add those areas together as a baseline. (Technically, the metric is weighted to be 0.6 time the NAND cell area plus 0.4 times the area of the flip-flop cell to get the number of transistors per square millimeter.) If you just use the NAND cell, Intel’s not looking so good, with only a 0.45X shrink moving from 32 nanometers to 22 nanometers (Bohr did not supply figures for the 14 nanometer and 10 nanometer jumps). But using this revived metric to reckon transistor density,
![]()
And here is what the same curve looks like with the actual metrics of transistor density as calculated above:
![]()
As you can see, the time it is taking to get each process node out the door is lengthening, but the bang Intel is getting from each jump is such that the transistor density is still on the doubling every two years curve – and in fact, it was a little better than that during the 32 nanometer, 22 nanometer, and 14 nanometer cycles. It just takes more than two years to reap the yields, and there is no reason to believe Intel will be able to shorten the cycles to less than three years between nodes going forward. (The company did not give any indication it could get it back to two years between process nodes.)
Here is where it gets interest. Bohr whipped out this chart that shows how the competition is doing using the NAND plus flip-flop circuit method to calculate transistor density:
![]()
This is a very interesting chart indeed. It shows that Intel got its 45 nanometer processes out the door a year and a half ahead of the competition, but the competition had significantly better transistor density. (Remember that these are log scales on the Y axis in these charts, so the gaps are big.) Then Intel’s 32 nanometer processes quickly closed the gap, and when Intel jumped to 22 nanometer FinFET (what used to be called TriGate) transistors in late 2011, it got the lead and has held it since then. As best as Bohr can figure, using the NAND plus flip-flop cell calculation method and available information on the 10 nanometer processes from TSMC, Intel’s 14 nanometer processes (used on “Broadwell” and “Skylake” families of Core and Xeon processors) deliver almost the same transistor density as the 10 nanometer processes will, and its own 10 nanometer processes, due to start coming to market later this year in Core client chips, will have about twice the density, right on track with Moore’s Law.
By the way, Smith says Intel has already shipped more than 450 million units of 14 nanometer chips on over 7 million 300 millimeter wafers.
Here is the same chart showing the logic area shrink comparing Intel to its fab competition:
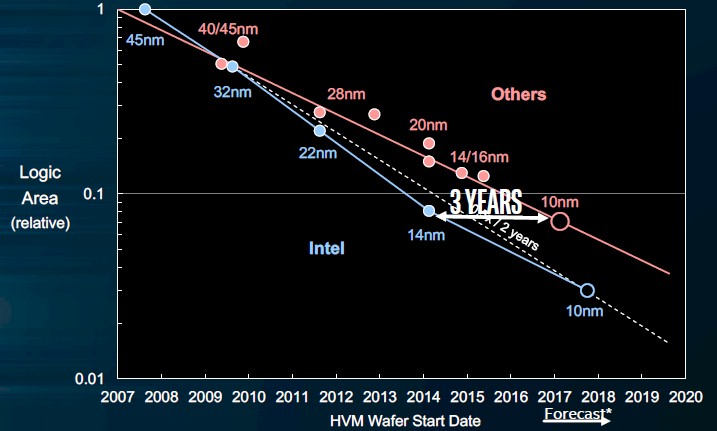
So what matters with process shrinks is where the rubber meets the road in terms of the shrinking of the die sizes, since the smaller the die, the better the chance it does not have a defect in it. The die area scaling has traditionally been a factor of 0.62 shrinkage for the same circuit, and thanks to the hyperscaling techniques used in the 14 nanometer and 10 nanometer processes, Intel has been able to do better than that:
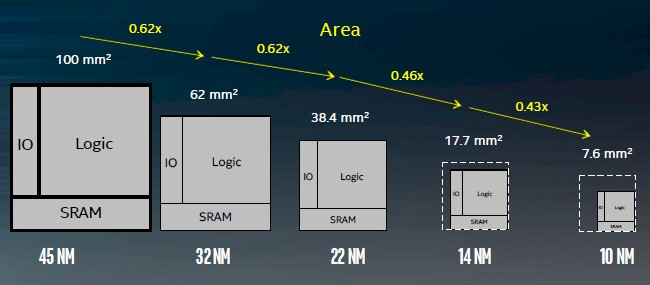
Ruth Brain, Intel Fellow and director of interconnect technology and integration in the Technology and Manufacturing Group, tells The Next Platform that this chart is a blended average of area shrinkages for Core and Xeon chips implemented in each process. With normal areal density improvements, you would expect that a chip with 100 square millimeters of area implemented in 45 nanometer processes would shrink to 23.8 square millimeters at 14 nanometers and 14.8 square millimeters at 10 nanometers. But thanks to the hyperscaling techniques, it has been able to get a 0.46X scaling factor with 14 nanometer processes, down to 17.7 square millimeters, and a 0.43X scaling factor at 10 nanometer processes, pushing that chip down to 7.7 square millimeters. That is a substantial increase in the number of chips per wafer, and this is one of the reasons why Intel is still using 300 millimeter wafers and has not been pushed to 450 millimeter wafers, which would be an enormous cost. (Eventually, Moore’s Law will push Intel and everyone else to the larger wafers, it is just a matter of timing.)
The normal scaling, Bohr explained, was just not going to cut it. Take a look at the curves:
![]()
As you can see, there is a nice and predictable log scale improvement in area density, but the cost per wafer keeps going up and up thanks to the process shrink, which takes more steps and time. And if Intel just relied on process shrink alone, the cost per transistor would start flattening out rather than improve at the exponential pace.
Intel could have shifted to 450 millimeter wafers, and that is what this would look like:
![]()
The transistor density would have remained the same, but the cost per area would shift down because it was handing wafers that were 50 percent larger. Consequently, the cost per transistor would have shifted quite a bit below the 2X over two years line that Moore’s Law defines for transistor cost improvements, but the slope of the curve going out to 14 nanometers and 10 nanometers would not change and by 7 nanometers, it would be off the curve again. Whoops.
Here is what it looks like when Intel puts 450 millimeter wafers in its back pocket for a rainy day and implements all of those hyperscaling techniques:
![]()
The cost per wafer is going up, but the transistor density on its chips is rising fast enough that Intel is actually doing better than Moore’s Law on Moore’s Law. The curve is starting to bend up at 7 nanometers and will probably cross at 5 nanometers, but that latter bit is just a guess on our part.
This is a lot of theory, but what actually happens with the chip costs? Smith shared some interesting data. The chart below is interesting in that it shows Intel’s cost curves for Core chips on the past five generations of chips on its 22 nanometer and 14 nanometer processes:
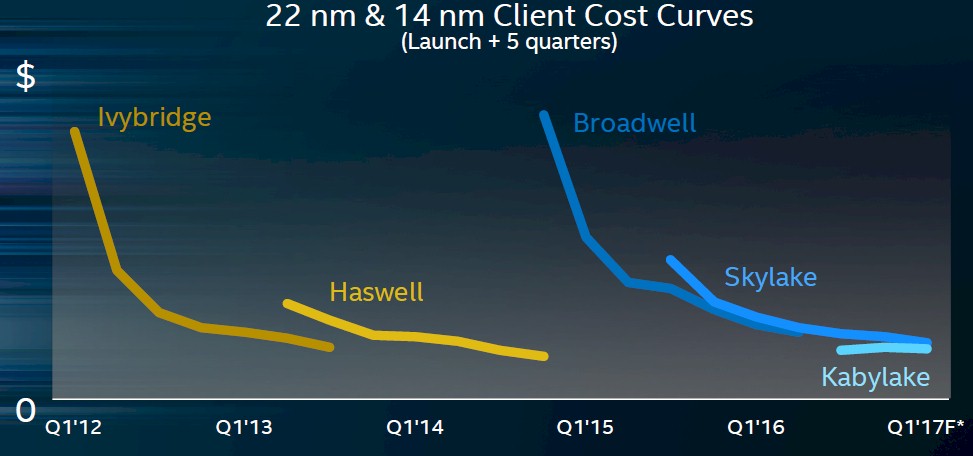
This is obviously a blended mix of PC chips in each generation, so mix affects the numbers as much as process because the chips have difference sizes within a generation (Core i5 is smaller than Core i7). The interesting bit is that the 14 nanometer “Kaby Lake” chips that Intel is ramping now cost less than the mature “Haswell” chips from a few years back on 22 nanometer processes. How far that 14 nanometer curve can go down is unclear, but the 10 nanometer ramp will begin later this year at the top again and inch its way down over three generations of chips.
If you take the average chip costs and the average transistors per chip and plot it out, here is what the log curve looks like:
![]()
Intel doesn’t put dollar figures, chip counts, or transistor counts in the charts, which would be fun. But as you can see, that is a pretty straight line on a log chart, as you would expect from Moore’s Law. Which is why everyone at Intel is chanting that Moore’s Law is not dead, but alive and well.