

Solving problems by the addition of abstractions is a tried and true approach in technology. The management of high-performance computing workflows is no exception.
The Pegasus workflow engine and HTCondor’s DAGman are used to manage workflow dependencies. GridWay and DRIVE route jobs to different resources based on suitability or available capacity. Both of these approaches are important, but they share a key potential drawback: jobs are still treated as distinct units of computation to be scheduled individually by the scheduler.
As we have written previously, the aims of HPC resource administrators and HPC resource users are sometimes at odds. High utilization rates help the administrators provide an economically-sound resource. To that end, sites will sometimes offer discounts to promote utilization. This can be done based on a job’s width or run time. Both Oak Ridge National Laboratory’s Titan and the National Energy Research Scientific Computing Center’s Edison systems have policies in place to incentivize jobs above a certain node count, while Google Cloud offers sustained usage discounts.
Such policies are helpful to administrators in meeting utilization goals, and they certainly are of benefit to the users that can take advantage of them. However, not all jobs fit such a model. For those users, a new paradigm has been developed. Instead of a meta-scheduler, they can use a meta-queue. The METAQ project developed by Evan Berkowitz provides a mechanism by which smaller or short-running jobs can take advantage of scheduling policies that promote utilization.
Unlike meta-schedulers, which submit multiple jobs, METAQ submits a single job — the meta-queue — and manages all of the computational work (called “tasks” in order to provide clarity) within the allocation that the scheduler provides. Thus, a meta-queue that makes a single request of one thousand nodes from the scheduler for eight hours can run one 8,000 node-hour tasks, 8,000 one node-hour tasks, or any other combination that will fit. This gives the user the opportunity to reap the benefits of utilization-favoring policies without having to forcibly combine tasks. Where tasks are unrelated, this is an even bigger benefit.
Meta-queueing provides additional user benefit beyond just the ability to get usage discounts. On systems with a large wait time, the user can submit the meta-queue to the scheduler queue without knowing exactly what work is to be done. Even once the meta-queue begins executing, the user can readily add, edit, or remove work without having to move to the back of the line. The specific implementation details of METAQ add yet another benefit: collaboration. METAQ uses files on disk to describe tasks. The application of appropriate POSIX permissions and ownership enables a user to allow others to submit their own tasks into the meta-queue. A lab team, for example, could then bundle their disparate tasks together under a single meta-queue job.
METAQ is a collection of Bash scripts that examine and run tasks. Tasks define their own hardware requirements (both node/CPUs and GPUs are currently supported) and wall time. The METAQ directory structure allows for high-priority and low-priority tasks to defined, as well as tasks that are defined but won’t be executed. When capacity is available within the meta-queue, METAQ examines outstanding tasks, rejects what cannot be run, and launches a task or tasks from what remains. By using METAQ, Berkowitz reduced the idle time to 10% compared to approximately 25% with naive bundling.
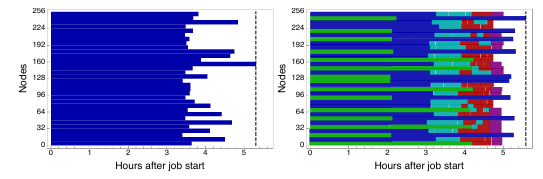
As with any technical solution, METAQ has some drawbacks. The METAQ job runs on a service node and launches a process for each task in addition to the overhead processes of METAQ itself. This can lead to exhaustion of the process ID namespace, as Berkowitz discovered when he inadvertently crashed a service node on Oak Ridge’s Titan. METAQ does not validate the resource requests of tasks. If the task scripts and the METAQ description file are inconsistent, there is no way to address the inconsistency. Another shortcoming is of a political instead of technical nature. Task bundling in such a manner — especially between users — may be viewed by some as gaming the system, particularly if it results in longer wait times for jobs that need the very-wide capability that large resources uniquely provide.
While the potential political concerns are left as an exercise for the reader, a new project inspired by METAQ seeks to address the technical shortcomings. mpi_jm is a meta-queue being developed by Berkowitz and his colleagues that Berkowitz expects will supersede METAQ. mpi_jm is being written in C++ to provide a lower-overhead meta-queue that runs on a compute node and uses a single process for task management, eliminating the process exhaustion problem. mpi_jm will also provide a richer ability to manage CPU-only and GPU-only tasks. However, mpi_jm will require recompiling code against the mpi_jm libraries, so this may leave METAQ as the preferred solution for some situations.
METAQ is available on GitHub and is released under the GNU General Public License, version 3. Code for mpi_jm is not publicly-available as of this writing.


Sharpening a New Fork for HPC Cluster Tuning
There is a long-running joke in high performance computing that for any question that can be asked, the answer is probably going to be “it depends.” This maxim persists because there is an incredible amount of diversity of hardware, software, middleware, applications, and other factors that make coming up with …
Be the first to comment