

Data is quickly becoming the coin of the realm in most aspects of the business world, and analytics the best way for organizations to cash in on it. It’s easy to be taken in by the systems and devices – much of the discussion around the Internet of Things tends to be around the things themselves, whether small sensors, mobile devices, self-driving cars or huge manufacturing systems. But the real value is in the data generated by these machines, and the ability to extract that data, analyze it and make decisions based on it in as close to real-time as possible.
There are few areas in this world where stats and data are discussed more than in sports, and few sporting events that are more watched than the Super Bowl. The 51st edition of the game is this Sunday in Houston, when the New England Patriots take on the Atlanta Falcons. Jessie Piburn, research scientist in the Geographic Data Sciences department of the Oak Ridge National Laboratory (ORNL) in Tennessee, shifted the focus of his data science expertise onto the game.
In a panel discussion called “The Science of the Super Bowl” put on by Newswise and later in talking with The Next Platform, Piburn talked about how the NFL and its teams – particularly the Patriots and Falcons – are rapidly growing their use data analytics, how what they’re doing translates over into the world of enterprises and how human input is still important to the process. It’s gotten so important for the Patriots and team owner Robert Kraft that he spun out a new business called KAGR (Kraft Analytics Group) to not only leverage the data they were getting to better engage fans but also to offer technology to other companies for their own data science efforts.
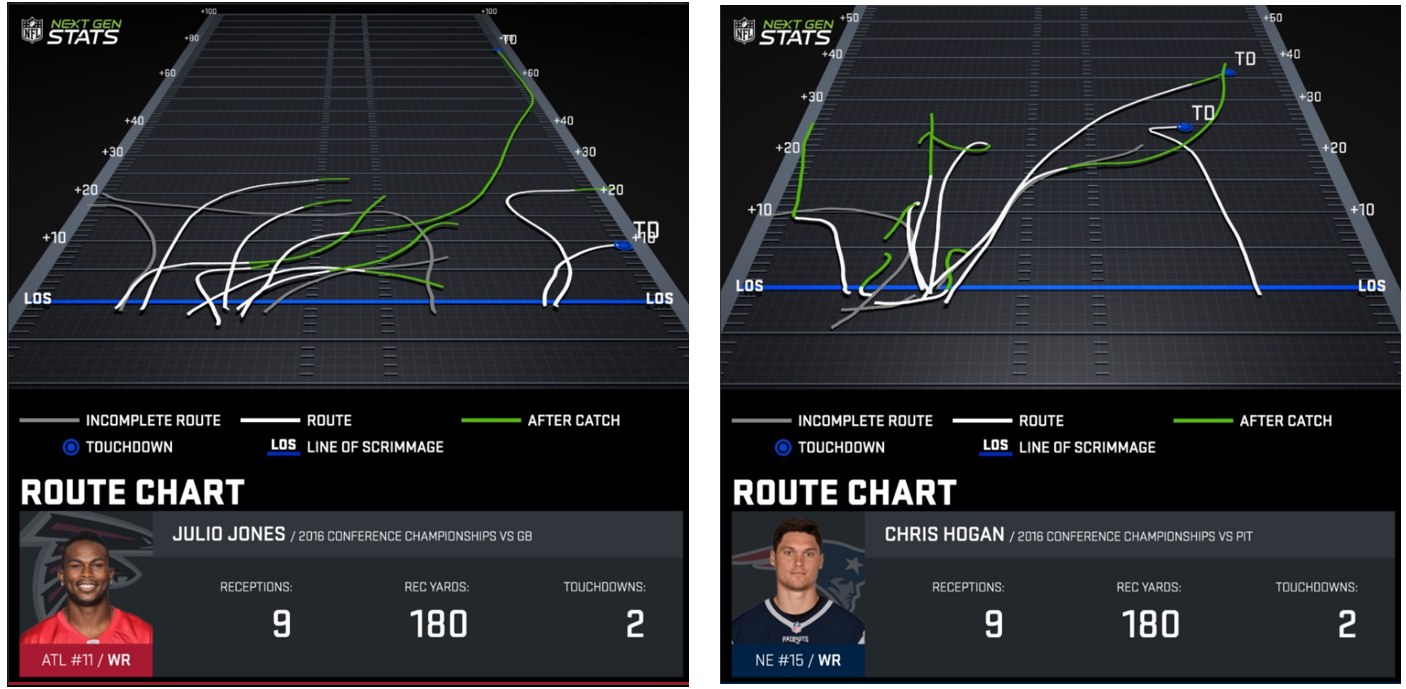
The NFL is leveraging data science for everything from the annual player draft and player health to player performance, game preparation and fan engagement. For example, since 2014, every player in the league has played with RFID tags in their shoulder pads that track the real-time position and movement of every player on the field at all times, including their speed and acceleration. That data can be spun out to give users – coaches, fans and others – statistics for a more complete understanding of the game. For example, both New England receiver Chris Hogan and Atlanta receiver Julio Jones had nine catches for 180 yards in their respective games two weeks ago, but the data showed such information as the different routes the receivers ran and how many of those yards came after the catch.
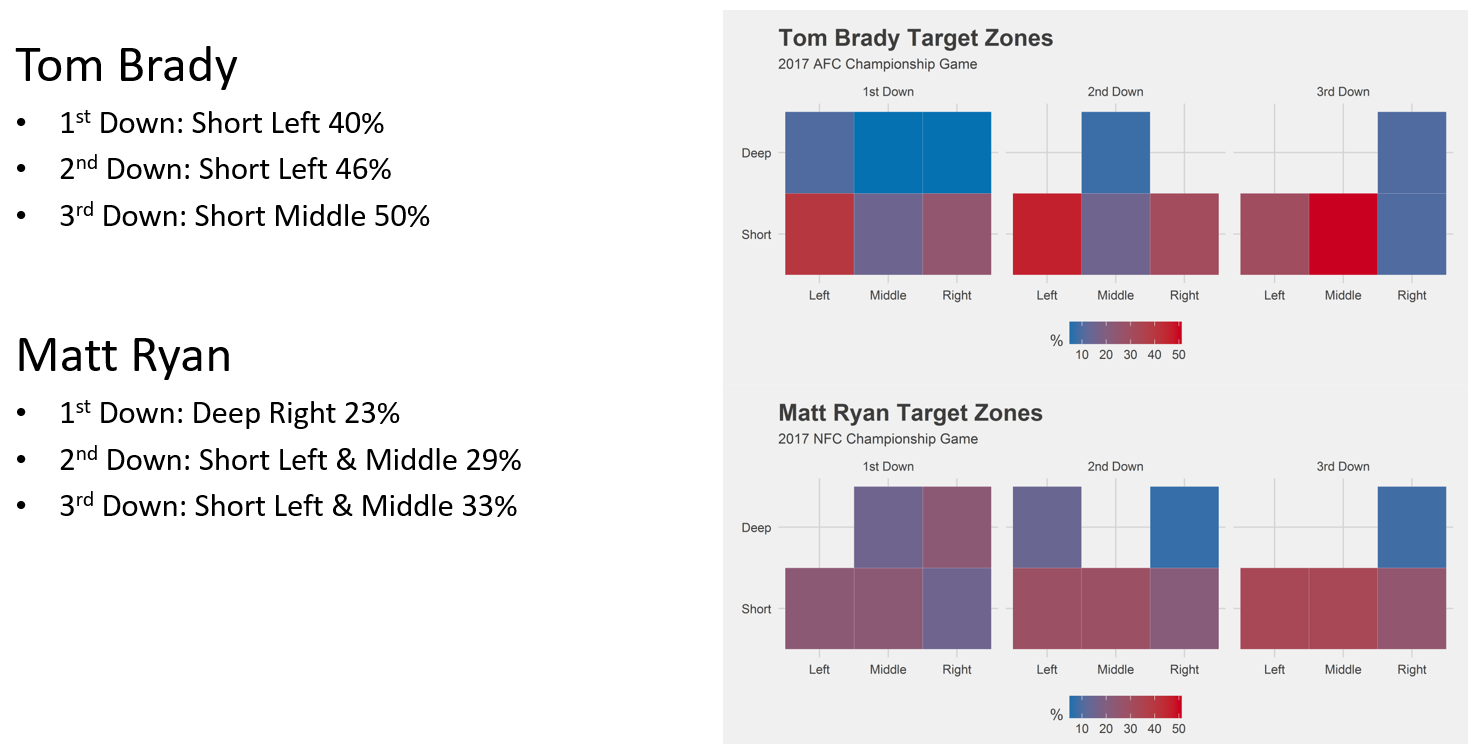
Other stats Piburn collected show such information as where the two quarterbacks, Tom Brady (NE) and Matt Ryan (Atlanta), tend to throw on each down, where each team most often runs the ball (the Patriots up the middle, the Falcons more to the outside), and what they tend to do in the “red zone,” the area between the 20-yard-line and the end zone. (Atlanta throws more when they have the lead, while New England tends to run the ball more.)
Where the data most likely influences the Super Bowl is with Game Win Probability Models – outlining the probability under a certain set of circumstances of which team will win the game, he said. For example, the probability for the Falcons will go up if they score a couple of touchdowns early, while New England’s probability likely will go up if the Patriots can run the ball. It also plays a role in evaluation game-time situations, like whether to run a play on fourth down or to punt the ball away. However, Piburn stressed that in the NFL and other sports organizations, most often data science is used not for decision-making, but decision assistance. A coach may have pages of data and statistics in his hands that outline the pluses and minuses of each fourth-down decision, “whether to go for it on fourth down will always be up to the head coach, not a model,” he said. The data will assist the coach in his decision, but not make the decision itself.
It’s in these areas that human input comes into play. Data science can tell you how likely it is that a play will work or that a team will win, but it can’t take into account all the various intangibles, like what a coach may know about a certain opposing player or Tom Brady’s coolness under pressure. There’s also the assumption in data analytics that what happens in the past will occur again the future. The Falcons will know that the Patriots will know that Atlanta tends to run the ball wide, so what happens to the probabilities outlined by the data science if Atlanta’s coach decides to run the ball inside?
“The models we generate are representations of what we want to do in the future in so far as the future is similar to the past,” Piburn told The Next Platform. “We assume what the Falcons do in the Super Bowl is what the Falcons have done previously.”
There are similarities that businesses can draw from the sports world when it comes to data analytics. All organizations are hoping to use the data to their advantage – to win a game, to drive revenues, to get better health care results, etc. But there are also significant differences. Unlike business and most everything else in the world, sports are conducted in very controlled environments – there are set rules, there are contained playing fields, everyone understands what is supposed to happen in football and in baseball, and things tend to happen sequentially. One play leads to another, and dictates the possibilities for the next play.
That’s not what life is like outside of sports. There playing fields are not always well-defined, rules are not always clear, there can be many more variables to consider.
“In the business world, it’s not all that neat,” Piburn said. “It’s not that tidy. … It’s not so sequential.”
However, like in sports, “the human factor is the most important part of data science,” he said. Data analytics and probability calculations often have to include the Bayesian technique, a way of incorporating the human subject matter expertise into the mix to include the human understanding of how systems behave. Human insight brings in another factor to be considered.
At the Geographic Data Sciences unit at ORNL, Piburn and his colleagues use a variety of big data strategies to address such issues as national security, urban development and water-and-energy dynamics. For example, the group uses an application called LandScan, which offers a high-resolution population distribution estimate for the world. In highly-developed countries like the United States, population calculation is relatively easy – everything is neatly laid out in towns, cities and counties. That’s not so in other countries. The LandScan algorithm can calculate population in about a 1 km resolution using spatial data, satellite imagery analysis and a multi-variable dasymetric modeling technique to determine census counts within a particular administrative boundary anywhere in the world.
LandScan is used with the Bill and Melinda Gates Foundation in Nigeria to determine population estimates to make medicine distribution more efficient, Piburn said. There have been times when too much medicine has been delivered to one area – when 100 packs are brought to an area with only 20 people – or too little delivered to another area (500 packs to places where 5,000 people live). Using LandScan, those delivering the medicine have a better gauge on how many people live in a particular area, and how much medicine to bring.
Even after all this talk about data science and analytics and probability, Piburn is still going with his gut on the Super Bowl. The Patriots are being given a 60 percent chance of winning the game Sunday, but he is predicting a Falcons championship. When asked why, he notes another factor that can come into play when talking about stats and probabilities – how important the final decision is.
“My decision has no significant long-term impact,” he said.

Well he should have trusted the machine the 60% were right.
Interesting. This is like watching in some old movie, where everything was calculated mathematically and players were picked. Wonder if this works all the time.