

Over the last two years, there has been a push for novel architectures to feed the needs of machine learning and more specifically, deep neural networks.
We have covered the many architectural options for both the training and inference sides of that workload here at The Next Platform, and in doing so, started to notice an interesting trend. Some companies with custom ASICs targeted at that market seemed to be developing along a common thread—using memory as the target for processing.
Processing in memory (PIM) architectures are certainly nothing new, but because the relatively simple logic units inside of memory devices map well to the needs of neural network training (for convolutional nets in particular), memory is becoming the next platform. We have looked at deep learning chips from companies like Nervana Systems (acquired by Intel in 2016) and Wave Computing, and like other new architectures promising a silver bullet to smash through AlexNet and other benchmarks, memory is the key driver for performance and efficiency.
For background on this next wave of deep learning architectures with memory at the core, take a look at this article, which explores how new memory capabilities are driving efficient, scalable, and high performance machine learning training.
Today we are adding yet another custom architecture to the list of memory-driven, deep learning devices. This one, called Neurostream, out of the University of Bologna, is similar in some ways to the Nervana, Wave, and other deep learning architectures pinned to next-generation memory like Hybrid Memory Cube (HMC) and High Bandwidth Memory (HBM) and might offer us a clearer view into how some of those companies we just mentioned are thinking about deep learning architectures. In the past, we’ve been able to extract some architectural detail from Nervana, Wave, and others, but this team offered a much closer look at why memory-driven devices are going to be the future of custom deep learning hardware.
“Even though convolutional neural networks are computation-intensive workloads, their scalability and energy efficiency are ultimately bound by the main memory, where their parameters and channels need to be stored because of their large size…For this reason, improving the performance and efficiency of convolutional network accelerators without consideration of the memory bottlenecks can lead to incorrect decisions.”
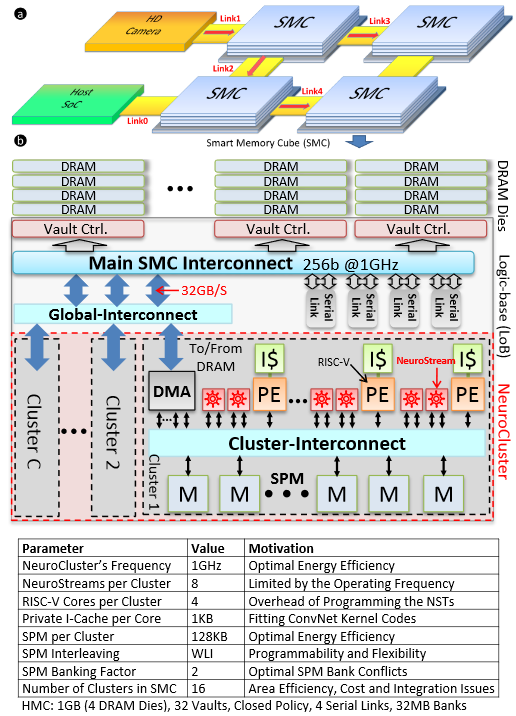
Neurostream directs its in-memory approach at scaling convolutional neural networks. The design hinges on a variation on Hybrid Memory Cube called “Smart Memory Cubes” that are “augmented with a manycore PIM platform called NeuroCluster. NeuroClusters have a modular design based on NeuroStream floating point coprocessors (for convolution-intensive computations) and general purpose RISC-V cores.” They also point to a DRAM-friendly tiling mechanism and scalable programming environment. What is interesting about this architecturally is that only 8% of the HMC die is used to achieve 240 GFLOPS of performance in a 2.5 Watt envelope.
“This platform allows for offloading the convolutional network tasks completely into the memoy cubes at a minor system power cost. This implies that the compute logic in the host SoC is free to deal with other workloads. Also, the cost increase with respect to a baseline HMC system would be negligible.”
The team is making some big claims about the performance per watt figures for the Neurostream architecture. “An energy efficiency of 22.5 GFLOPS per Watt is achieved in a single 3D stack, which is 5X better than the best off-the-shelf GPU implementation.” They note that the “minor increase in system-level power and the negligible area increase make this PIM system a cost effective and energy efficient solution, easily scalable to 955 GFLOPS with a network of four SMCs.” The GPU they compared Neurostream with was the Nvidia Tesla K40, which hits 1092 GFLOPs in a 235 Watt profile. “Neurogrid can achieve 955 GFLOPs at 42.8 Watts with 4.8X better energy efficiency,” the team argues, noting that it can also scale to higher node counts because of reduced demand on the serial links.
Neurostream creators expect the energy efficiency figures can be further boosted via some application-specific tweaks, but also by using reduced precision arithmetic. As they highlight, “reduced precision has the potential to reduce power consumption up to 70%.” In the next iteration of the work, they will be looking at implementing the architecture in silicon with four NeuroClusters, which will be used to monitor how it performs on back propagation and training.
We have been seeing a great many benchmarks about the efficiency and performance of coprocessors, ASICs, GPUs, and X86 processors with extensive software optimizations for deep learning frameworks. While we tend to take all of these with a grain of salt and do our best to compare, time will tell what architectures make the grade. The point here is less about the benchmarks cited and more about the architecture. Neurogrid, like Nervana, Wave, and other approaches, are all using HMC and HBM to the fullest—taking advantage of the limited processing inside memory, which as it turns out, is just heady enough to handle convolutional neural networks quite well.
Further, a more in-depth look at such an architecture helps us better gauge what’s going on under the hood of the few machine learning chip startups we’ve mentioned. We expect that 2017 will usher in a whole host of memory-driven processors with hooks for deep learning frameworks—both in terms of startups and academic efforts.


Former Nervana Leads Target Optimal Training Configurations
Ex-Nervana Systems engineers made the jump from a hardware-centric approach to efficient training to pushing better insight into optimization of models and systems. Nervana Systems was one of the first AI chip startups to generate big buzz, culminating in an acquisition by Intel in summer, 2016. The startup’s co-founder and …

Another Strange Shift for the AI Chip Startup Segment
Few of the AI hardware startups that have made it through the first round of reality (roughly 2016 until the present) have managed to navigate the choppy waters without shifting course, sometimes wildly. Nearly all have a story that begins with training, which washed into a rabid focus on inference …

Keeping Pace In A Fast-Moving AI Space
During the Intel AI Summit earlier this month where the company demonstrated its initial processors for artificial intelligence training and inference workloads, Naveen Rao, corporate vice president and general manager of the Artificial Intelligence Products Group at Intel, spoke about the rapid pace of evolution in the AI space that …
Hmm I wonder if this also would improve recurrent neural networks which have large swathes of hidden state variables that need to be kept for each iteration.
NVIDIA GP100 has 10.6 Tflops (32bits) and 21.2 Tflops (16bits) per 230W http://www.nvidia.com/object/tesla-p100.html, which is much better than numbers published by Neurogrid.
Those last figures for GPU are peak efficiency, I believe, not the actual efficiency on CNNs, which are typically 100x lower. My understanding from recent literature, .e.g. Kim, Yong-Deok, Eunhyeok Park, Sungjoo Yoo, Taelim Choi, Lu Yang, and Dongjun Shin. “Compression of Deep Convolutional Neural Networks for Fast and Low Power Mobile Applications.” arXiv:1511.06530 [Cs], November 20, 2015. http://arxiv.org/abs/1511.06530.
is that GPUs have been achieving <10GOp/W on large CNNs in runtime inference (single image) mode, i.e. the mode they need to run in for real time applications. E.g. VGG16 takes 15GOp and computes in about 11ms on Titan X, which burns around 200W, thus about 7GOp/W.